

A large-scale data distributed clustering processing method based on mapreduce
A large-scale data and distributed clustering technology, applied in special data processing applications, database models, relational databases, etc., can solve the problems of reducing the overall efficiency of parallel clustering, high similarity time consumption, and high computational overhead, etc. Achieve the effect of improving the efficiency of parallel clustering, reducing the number of clustering iterations, and fast convergence.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
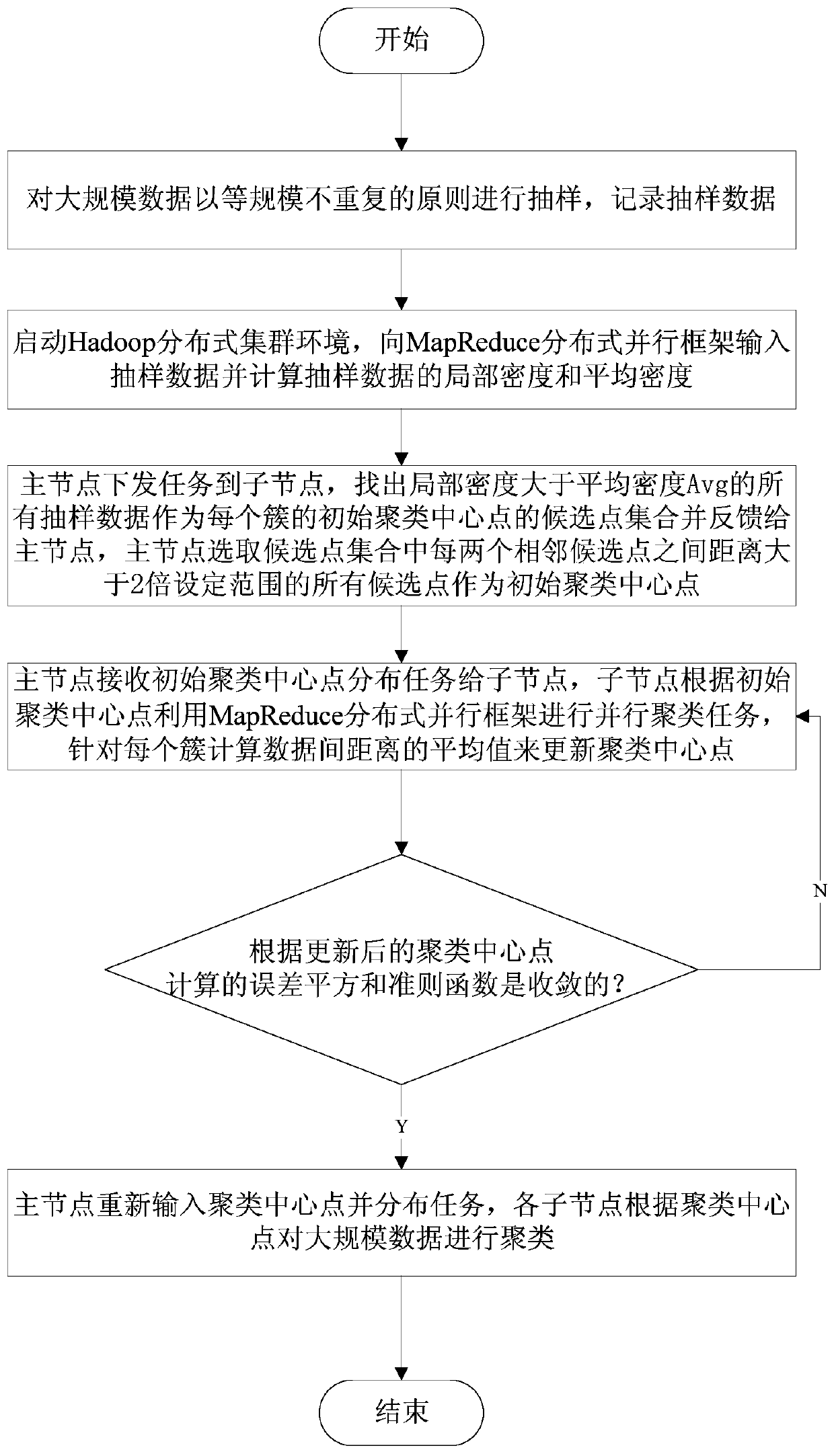
[0037] The specific implementation manners of the present invention will be described in detail below in conjunction with the accompanying drawings.
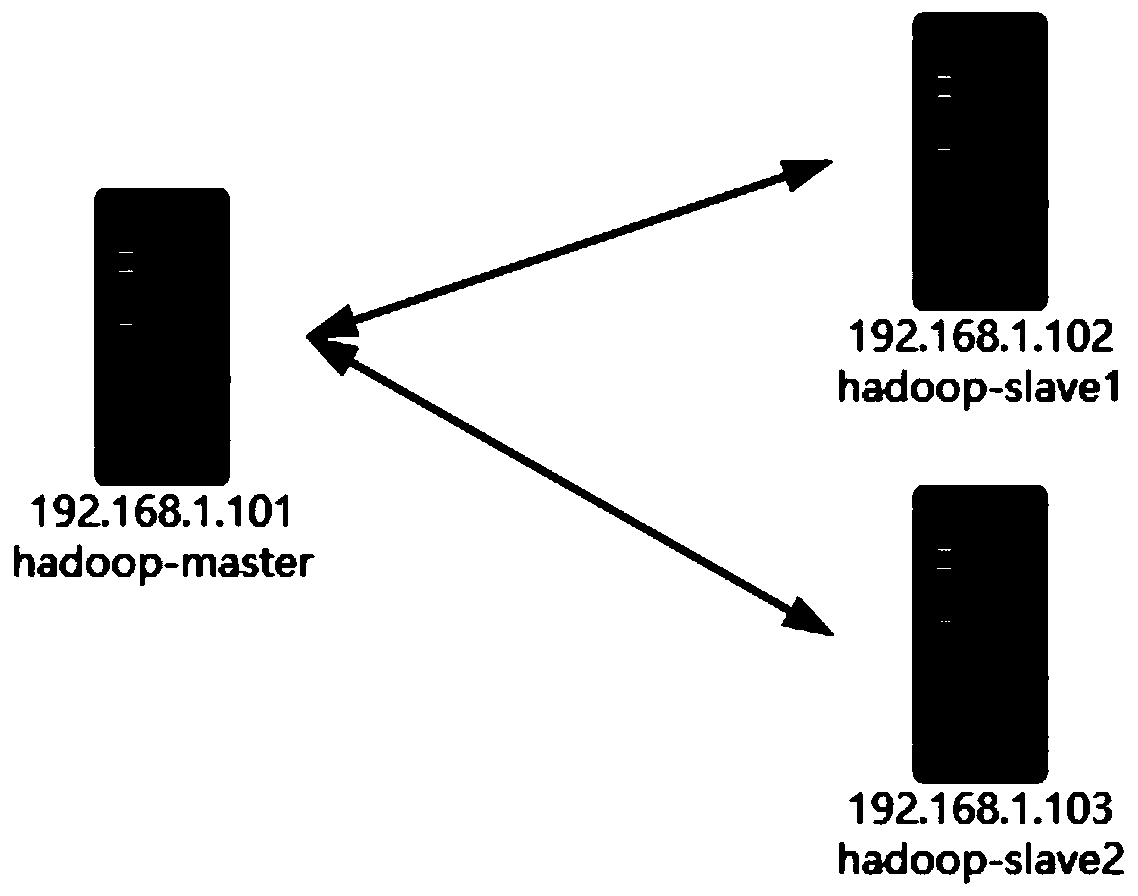
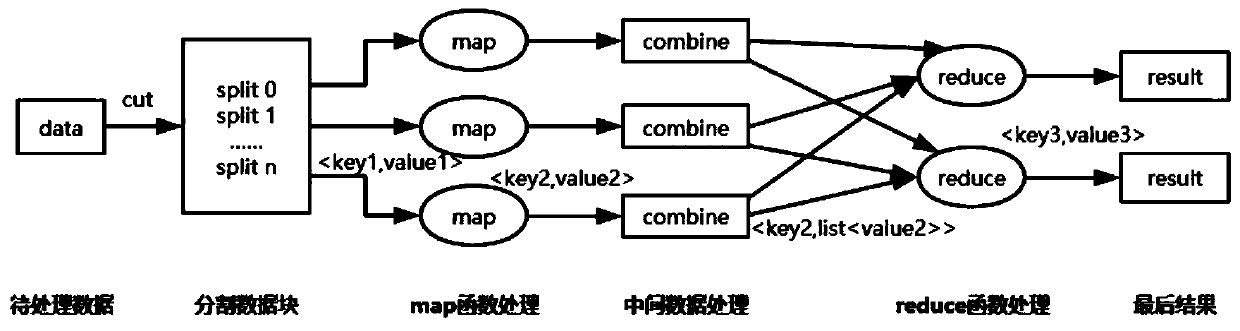
[0038] Such as figure 1 As shown, the Hadoop distributed cluster environment in this embodiment has 3 servers, which constitute 3 nodes, including a master node Master for issuing orders and distributing tasks, and 2 sub-node slaves for receiving tasks distributed by the master node and according to the master node. Node Master requests to process running tasks, and all nodes are connected through high-speed Ethernet. The master node Master starts the entire cluster environment according to the user's application request. The slave node slave and the master node Master are the main body of the Hadoop distributed cluster environment parallel system, responsible for the processing and operation of the entire Hadoop distributed cluster. Such as figure 2 As shown, in this embodiment: 1) receive data to be processed according to u...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More