

Clustering method and system based on big data parallel computation
A technology of parallel computing and clustering methods, applied in computing, relational databases, database models, etc., can solve problems such as unstable initial point selection, large computational load, and easy to fall into local optimal solutions.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0054] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
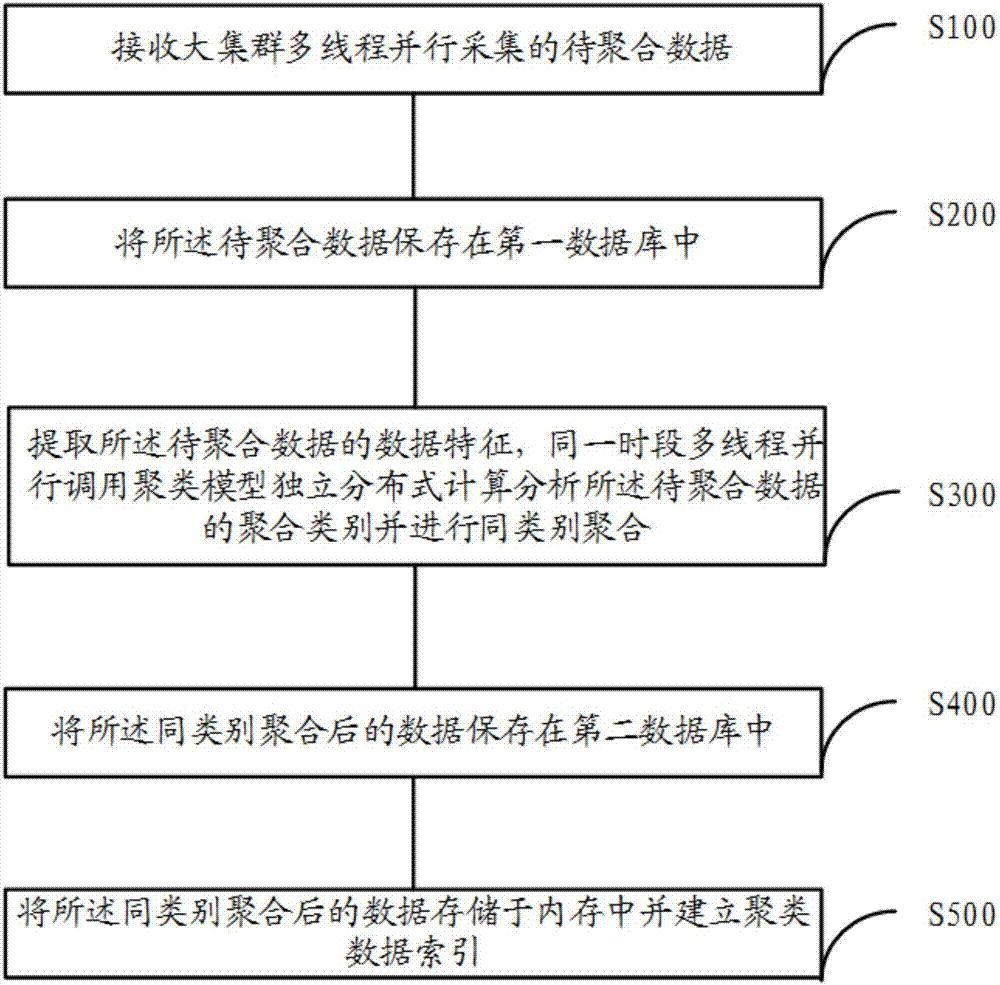
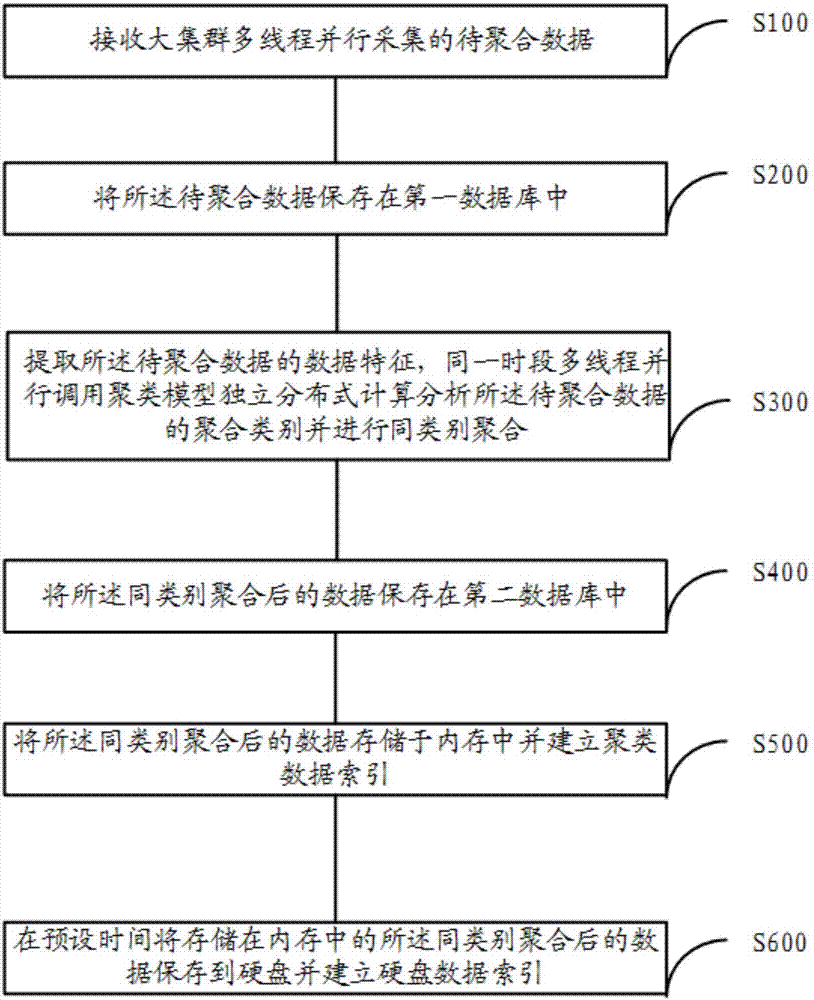
[0055] see figure 1 , the present invention provides a kind of clustering method based on big data parallel computing, comprising the following steps:
[0056] S100, receiving the data to be aggregated that is collected in parallel by multiple threads of the large cluster.
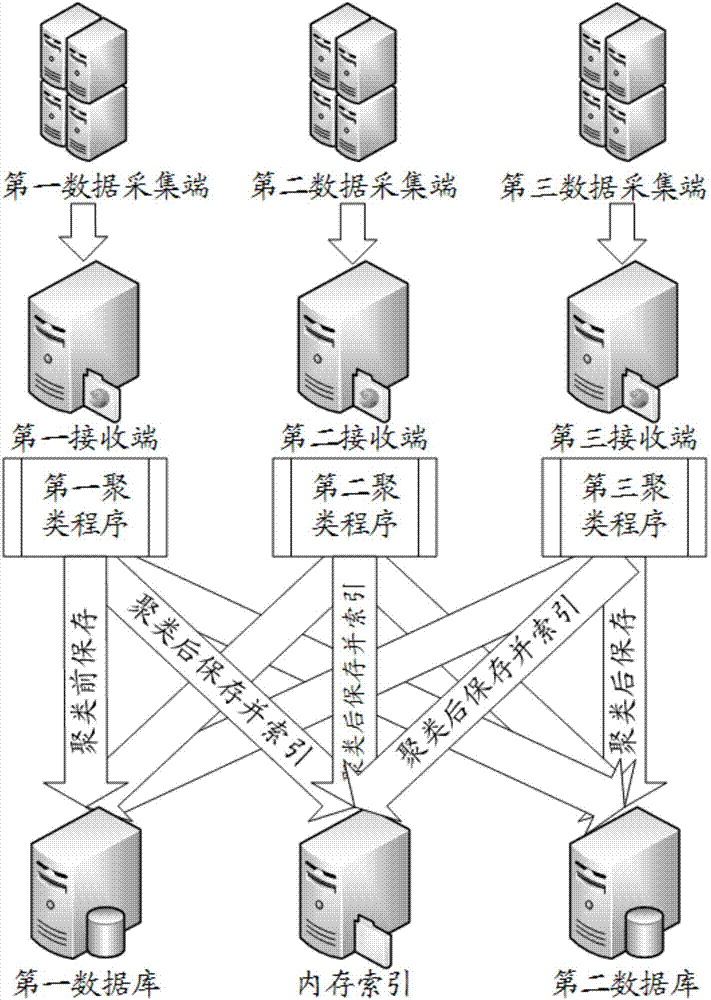
[0057] In the embodiment of the present invention, please refer to figure 2 , the first data collection end, the second data collection end and the third data collection end carry out t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More