

Data compression engine and method used for big data storage system
A big data storage and data compression technology, applied in file systems, electronic digital data processing, special data processing applications, etc., can solve the problems of increasing access tasks on resource occupation period, adverse effects on system performance, and reducing timeliness, etc. Improve the query response speed, improve the access task mechanism, and relieve the effect of load
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0042] The technical solutions of the present invention will be further specifically described below through examples.
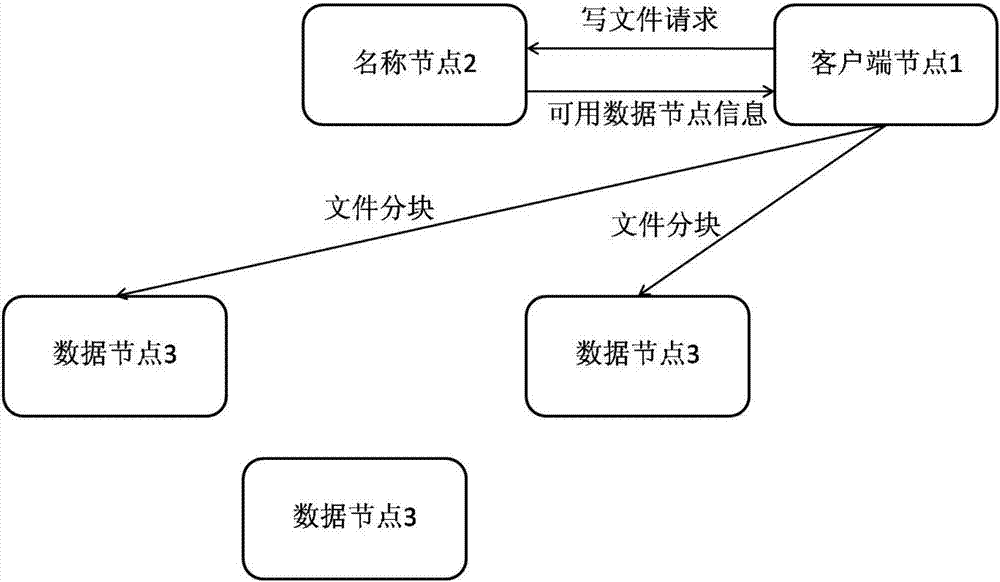
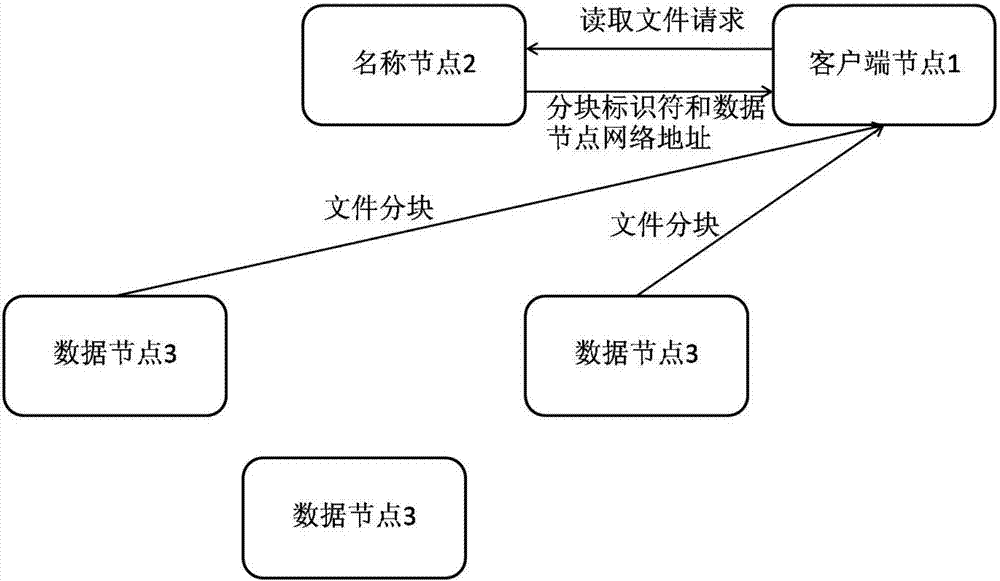
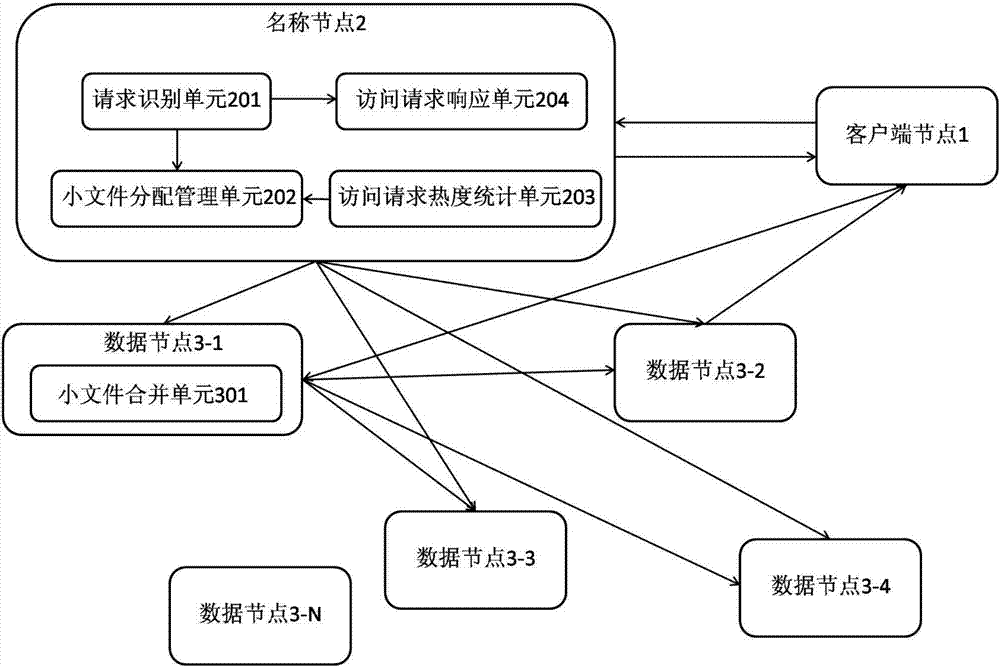
[0043] figure 2 It is a schematic structural diagram of the data compression engine system under the HDFS system provided by the present invention. Such as figure 2 As shown, the HDFS system for realizing distributed file big data storage includes: client node 1, name node 2, data nodes 3-1, 3-2...3-N. The stored data is used as a file, which is split into blocks by the client node 1 that uploads the file. The size of each block is 64M by default, and is stored in the data nodes 3-1, 3 of the HDFS system in blocks. - At least one data node in 2...3-N. The name node 2 registers a metadata item for each file, and the metadata stores the file identifier of the file, the block identifier of each block corresponding to the file, and the network address of the data node where each block is located. In the process of accessing data, the client node 1 that req...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More