Distributed scheduling analysis method, system and device for big data, and storage medium
A big data and distributed technology, applied in the field of data processing, can solve the problems of low efficiency of big data analysis and processing, poor standardization, and poor big data scheduling ability, and achieve the effect of improving job processing performance and data analysis efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment
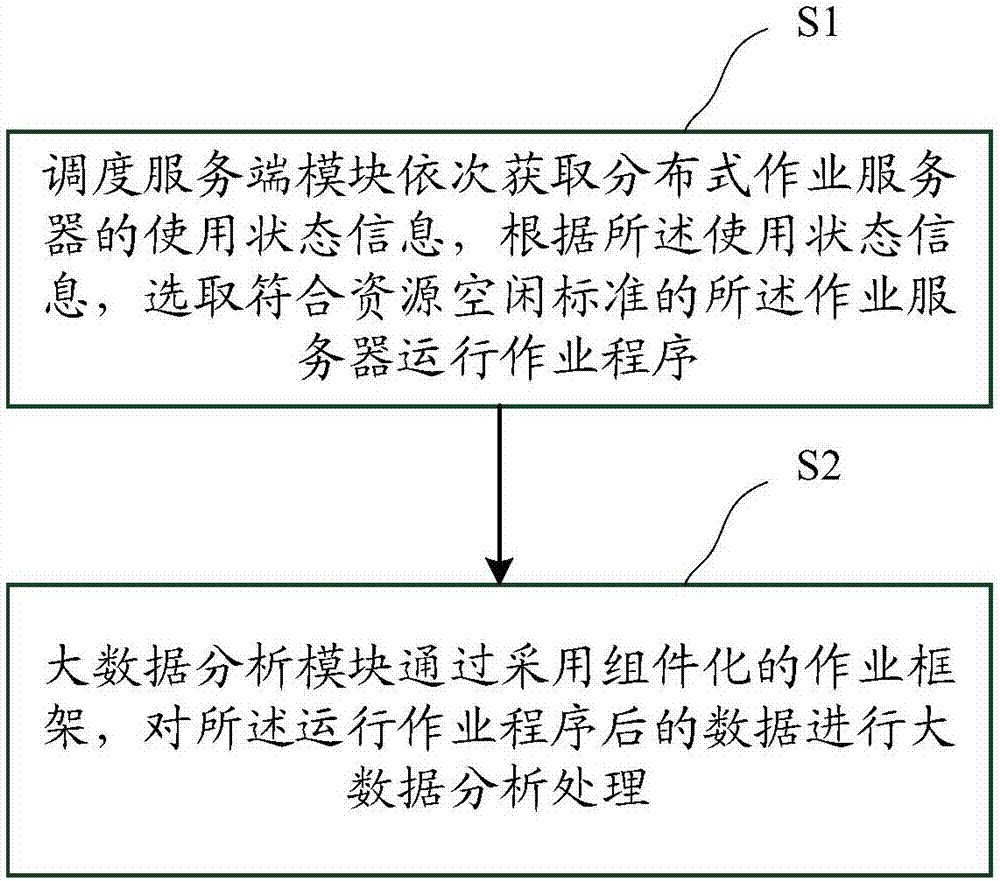
[0026] figure 1 It is a schematic flowchart of a big data distributed scheduling analysis method according to an embodiment of the present invention. refer to figure 1 , specific examples are as follows, the method includes:
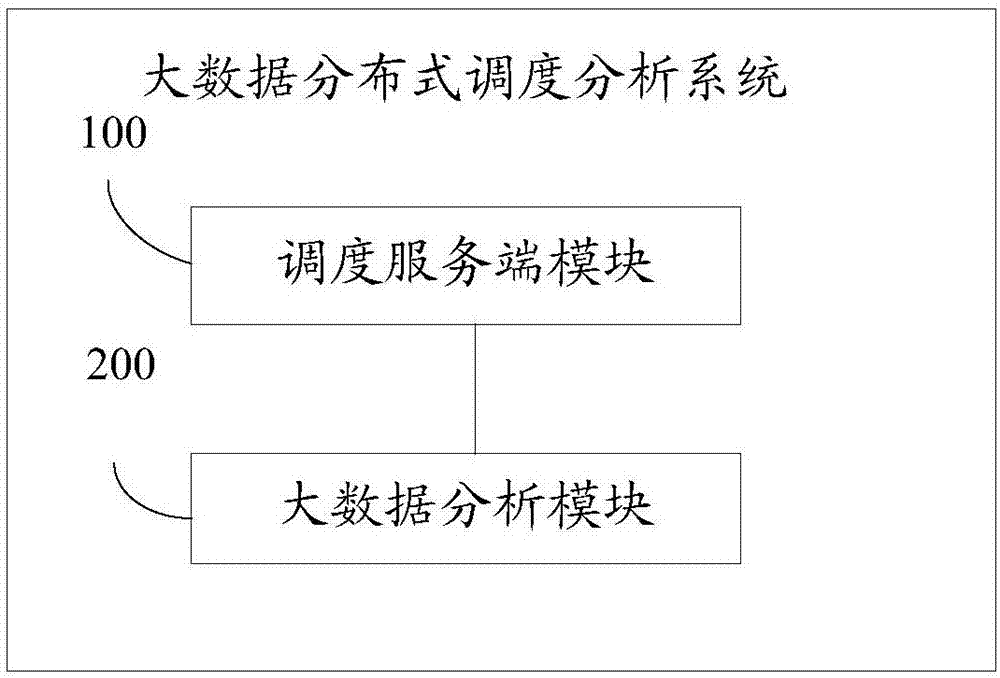
[0027] In step S1, the scheduling server module obtains the use status information of the distributed job servers in sequence, and selects the job server that meets the resource idle standard to run the job program according to the use status information. Among them, the ETL systems deployed on multiple job servers monitor their own status by regularly updating the database status to maintain stability.
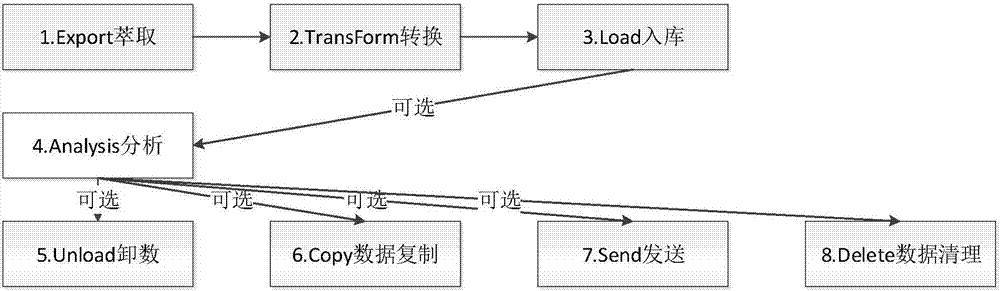
[0028] In step S2, the big data analysis module performs big data analysis and processing on the data after the operation program is run by using a componentized operation framework.
[0029] The present invention can effectively improve job processing performance and data analysis efficiency based on big data by adopting a distributed scheduling mod...
Embodiment 2
[0043] In another embodiment of the present invention, in addition to the above-mentioned processing method, the method further includes: adopting a dual monitoring mode to monitor and maintain the running process of the scheduling server module. In dual monitoring mode, check_monitor monitors monitor, and monitor also monitors check_monito. At the same time, the monitor monitors the ETL server process; it also scans version patches to maintain the version consistency of the ETL system.
[0044] By adopting the above-mentioned dual monitoring modules, the operation stability of each Server can be effectively improved and manual intervention can be reduced.
Embodiment 3
[0046] In another embodiment of the present invention, in addition to the above-mentioned processing method, the method further includes: the scheduling server module selects the corresponding language execution tool according to the job language category, and uses dynamic loading way to execute multilingual calling programs. The scheduling server module, as a core module, supports multilingual scheduling, refreshes through the Oracle status flag field, and realizes intercommunication between different Server states, between job flow states, and between job states; and loading jobs, adjusting Job relationship, complete job scheduling.
[0047] By supporting multi-language developers for collaborative development, developers can focus more on business logic rather than specific languages.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More