Escalator passenger detection algorithm based on fast Adaboost training algorithm
A technology of escalators and training algorithms, applied in computing, computer parts, instruments, etc., can solve unrealizable problems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0108] The present invention will be further described below in conjunction with specific examples.
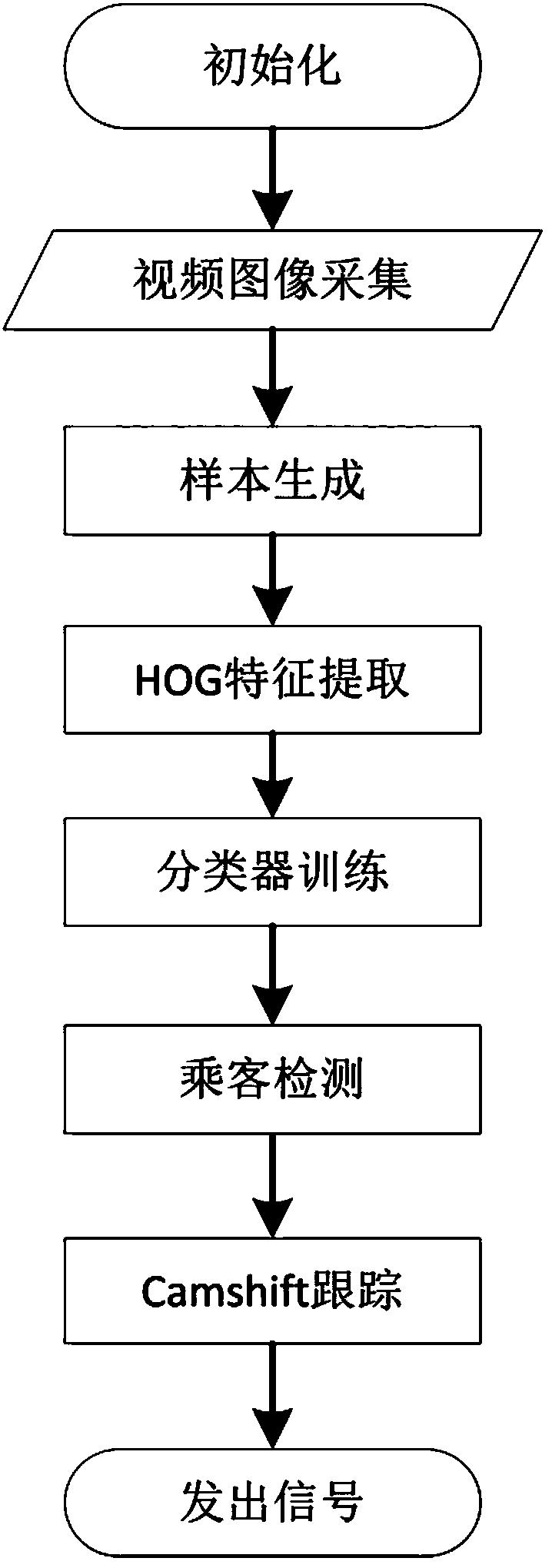
[0109] Such as figure 1 As shown, the escalator passenger detection algorithm based on the fast Adaboost training algorithm provided in this embodiment mainly collects video samples, extracts HOG features, quickly trains a classifier, and uses the classifier to detect passengers on the escalator. In this algorithm, the area of interest is the passenger area of the escalator. Therefore, the camera is installed obliquely above the moving direction of the escalator. The specific conditions are as follows:
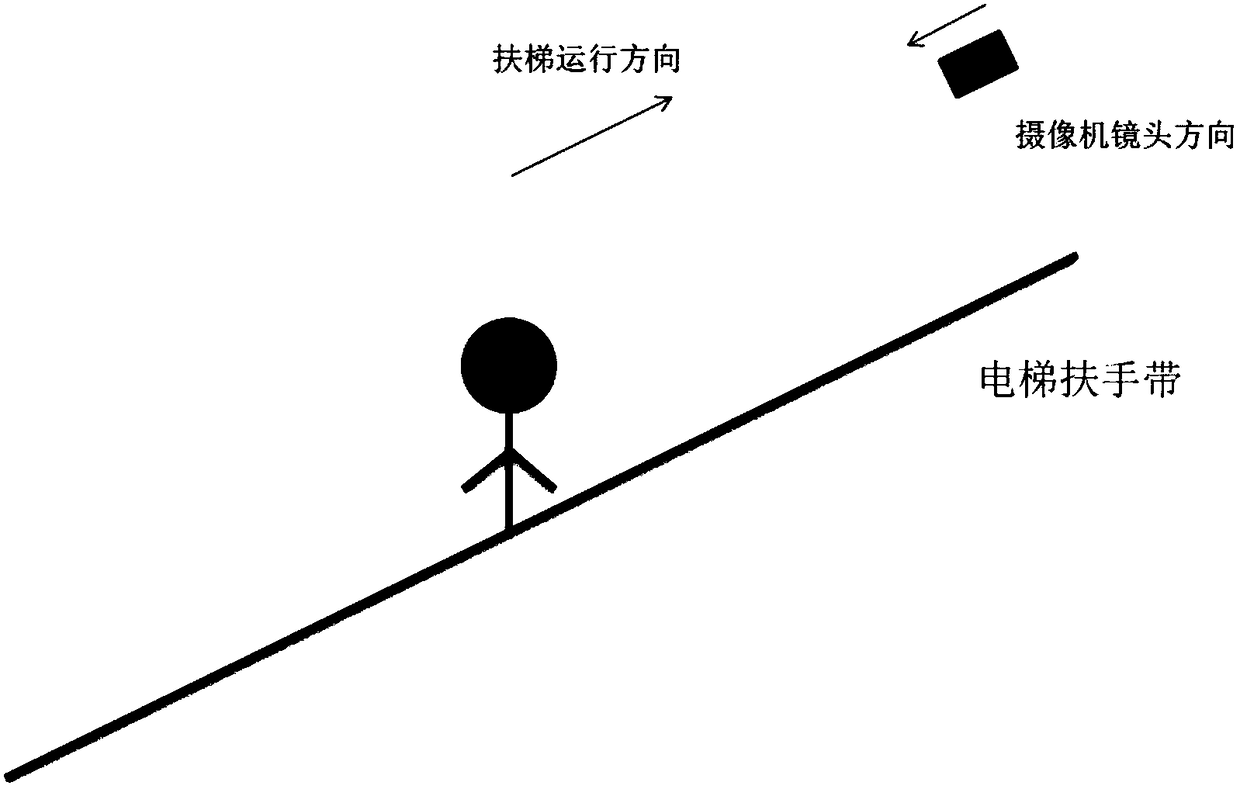
[0110] 1) The camera is used for image acquisition. The camera is installed obliquely above the moving direction of the escalator. Its viewing angle is required to cover the entire passenger area of the escalator and ensure that the passengers on the escalator are in the middle of the video. See figure 2 . The camera used is specifically a PAL standard-definition came...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



