

Data parallelism-based deep learning processor architecture and method
A processor architecture and deep learning technology, applied in the field of deep learning processor architecture, can solve problems such as energy loss, inability to optimize energy consumption, consume power consumption and data bandwidth, etc., to achieve improved utilization, optimized storage structure, The effect of reducing system latency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
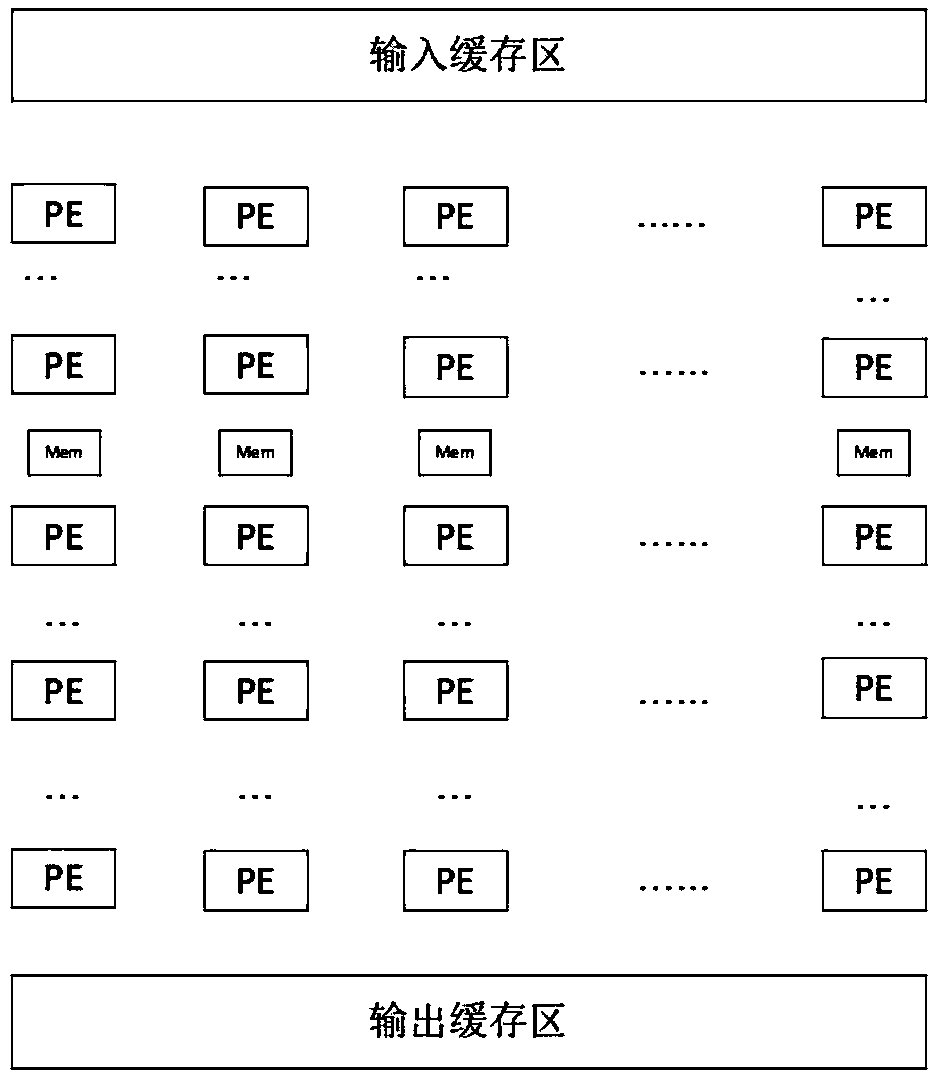
[0037] A deep learning processor architecture based on data parallelism, such as figure 1 As shown, it includes an input buffer area (In_Buf), a PE array, several on-chip buffer areas (SRam), and an output buffer area (Out_Buf). A group of on-chip buffer areas is arranged between two adjacent PE arrays;
[0038] Since the reading and writing of data from off-chip to on-chip consumes a lot of energy, the off-chip data is written into the input buffer area for temporary storage and pre-read, so that when the PE array reads the data in the input buffer area, the The input buffer area reads data from off-chip synchronously; it increases the continuity of data read and write.
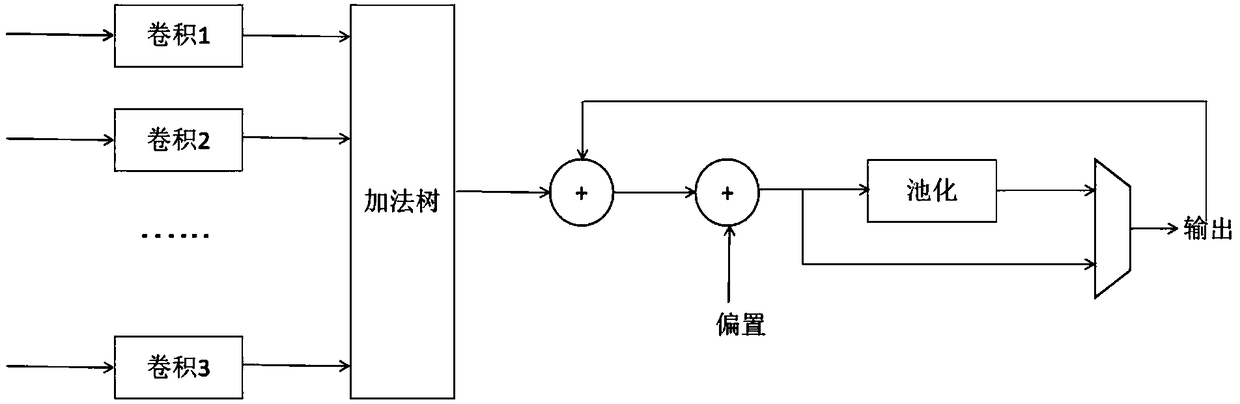
[0039] The PE array is used to read the input buffer data and perform data convolution and pooling calculations;
[0040] The on-chip buffer area is used to store temporary data processed by the PE array; it does not return to off-chip storage to reduce power consumption.
[0041] The output buffer area i...
Embodiment 2
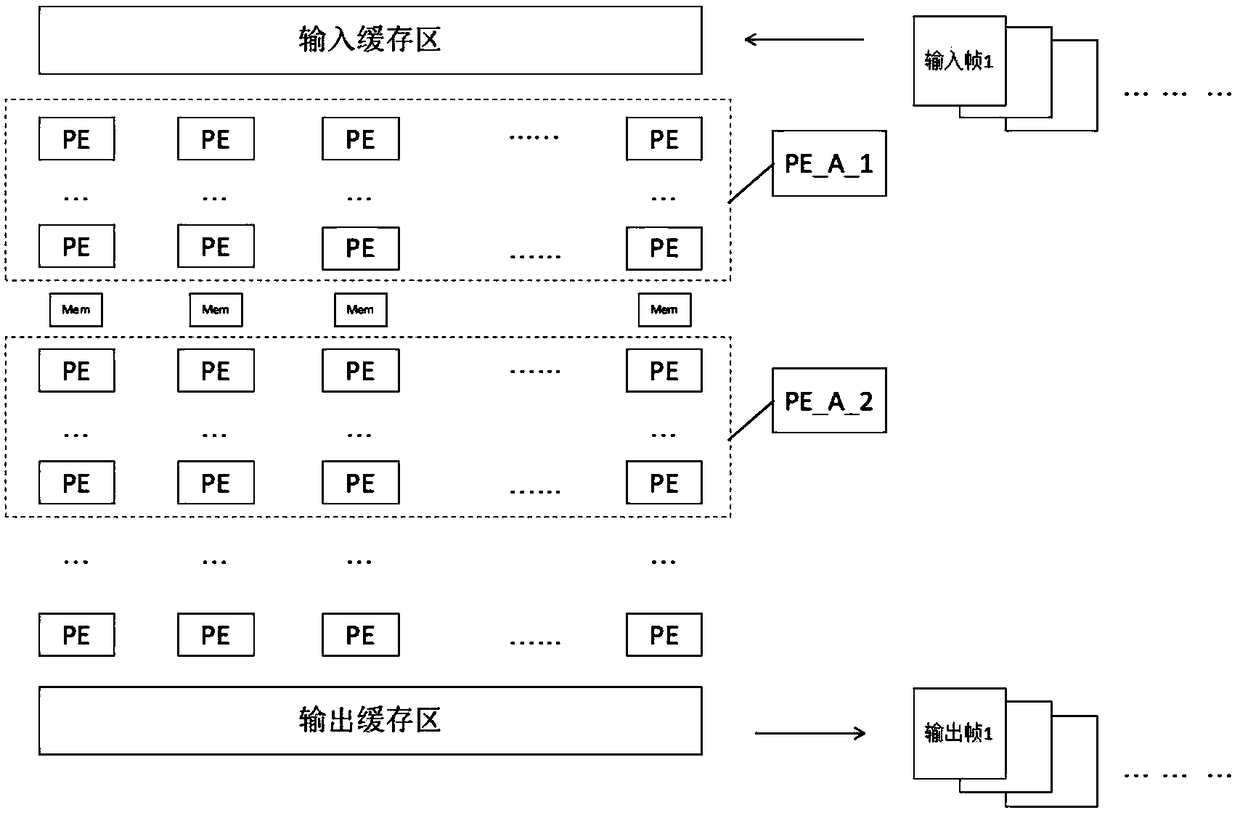
[0044] According to the data parallel-based deep learning processor architecture described in Embodiment 1, the difference is that the PE array includes N*N PE units. Such as figure 2 shown.
[0045] The data is written into the PE unit by the input buffer for processing. Since the amount of data read each time cannot be determined, the number of PE units required needs to be determined according to the amount of data read each time.
Embodiment 3
[0047] The processor framework described in embodiment 1 or 2 is based on the deep learning method of data parallelism, such as image 3 As shown, it is set that m frames of data need to be processed, m frames of data are stored in the input buffer area, and the PE array is set to include: {PE_A_1 matrix, PE_A_2 matrix...PE_A_k-2 matrix, PE_A_k-1 matrix, PE_A_k matrix}, PE_A_i matrix has N columns, 1≤i≤k, PE_A_1 matrix, PE_A_2 matrix...PE_A_k-2 matrix, PE_A_k-1 matrix, PE_A_k matrix The sum of rows is N; for example, divide the 5*5 matrix into rows 2*5 matrix (including the first row and the second row), 2*5 matrix (including the third row and the fourth row), 1*5 matrix (including the fifth row); including:
[0048] (1) In the first calculation cycle, the first frame of data is read from the input buffer into the PE_A_1 array for the first layer of convolution calculation, and the calculated feature sequence is stored in the SRAM of the PE_A_1 array;
[0049] (2) In the seco...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More