

Spark-based large-scale distributed DataFrame query method
A query method and distributed technology, which is applied in the field of large-scale distributed DataFrame query, can solve the problems of DataFrame lack of flexible and easy-to-use query functions, and achieve good scalability, good ease of use, and improved query performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
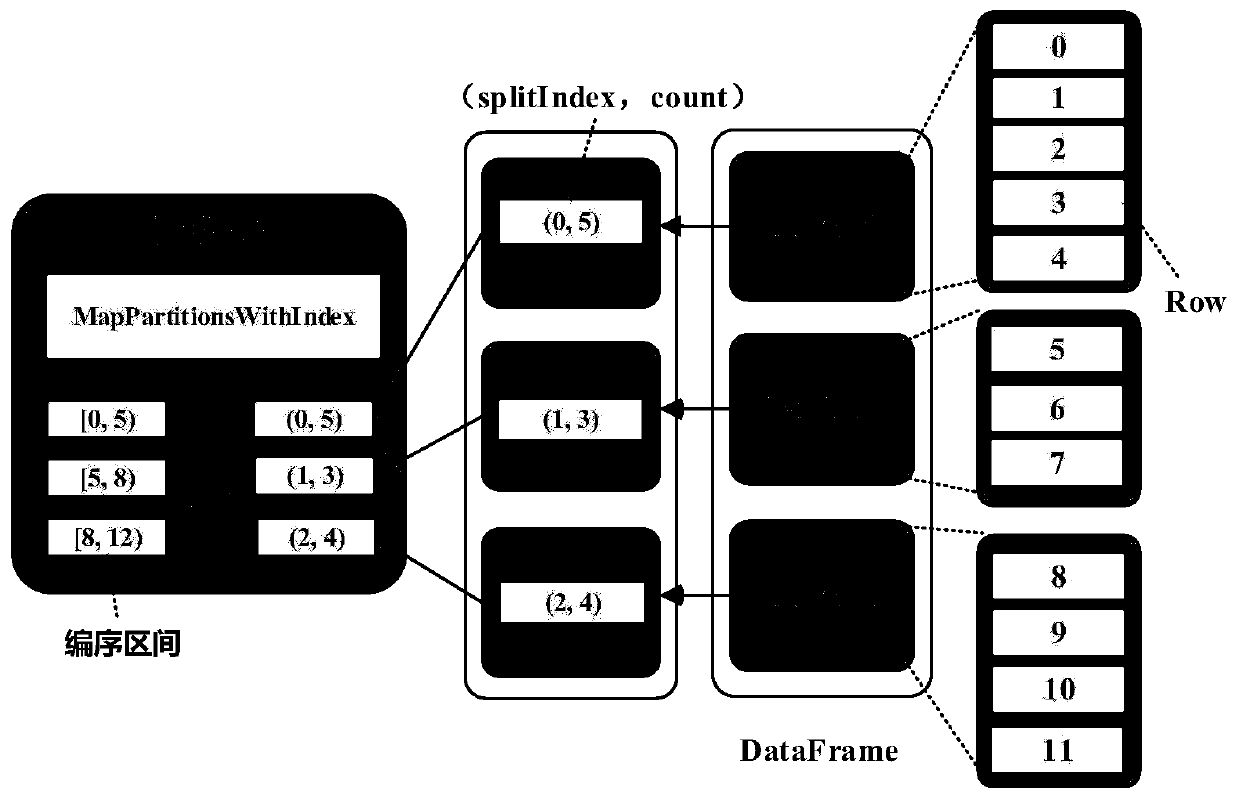
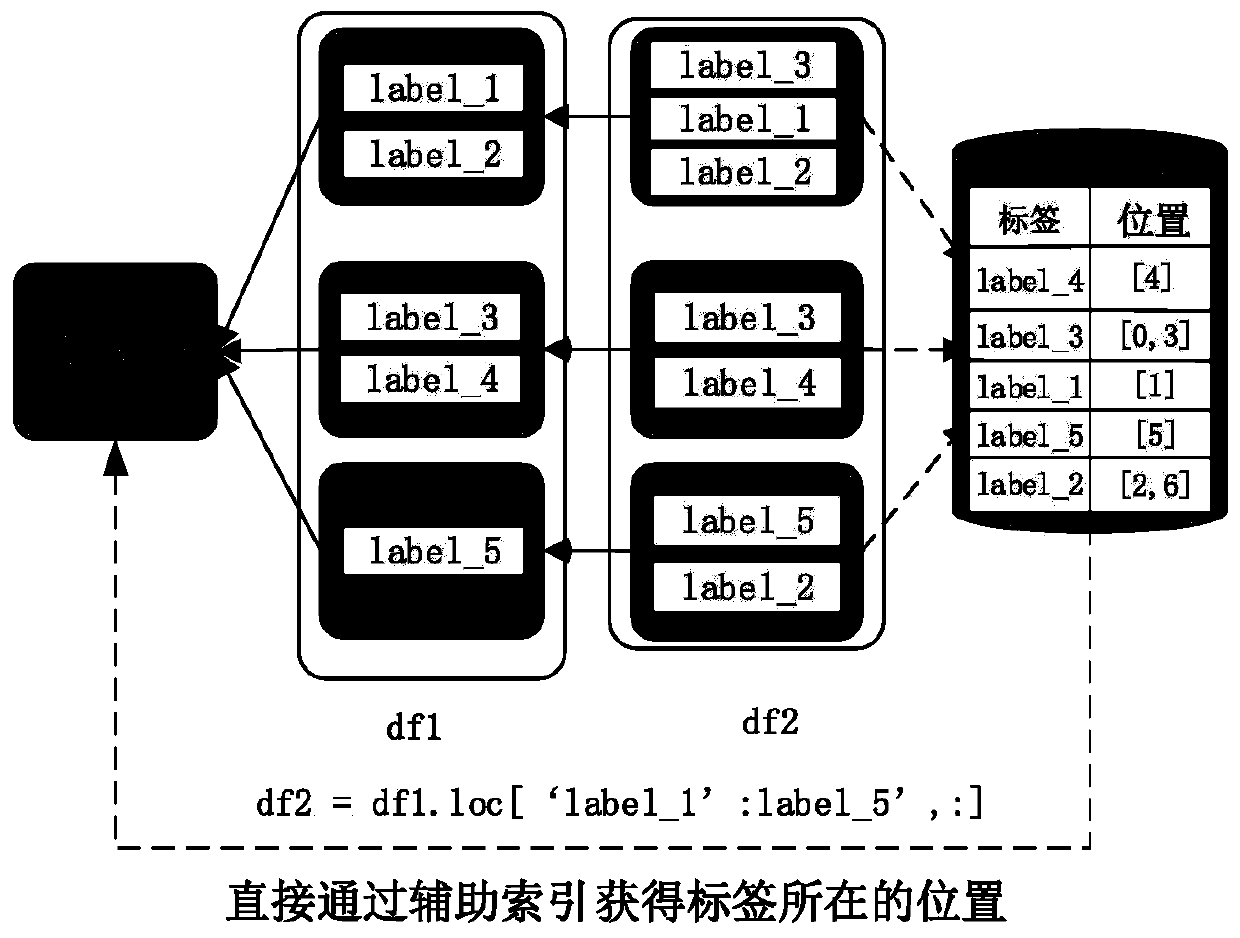
[0024] Below in conjunction with accompanying drawing and specific embodiment, further illustrate the present invention, should be understood that these embodiments are only for illustrating the present invention and are not intended to limit the scope of the present invention, after having read the present invention, those skilled in the art will understand various aspects of the present invention Modifications in equivalent forms all fall within the scope defined by the appended claims of this application.
[0025] The technical scheme of the present invention is mainly based on the distributed big data processing system Spark for distributed computing, and the distributed memory database Redis and the shared memory object storage database Plasma Store for storage. The distributed big data processing system Spark is an open source system of the Apache Foundation (project homepage http: / / spark.apache.org), and this software does not belong to the content of the present inventi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More