Speaker identification method based on joint optimization of total variation space and classifier
What is AI technical title?
AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
A technology of joint optimization and identification, applied in the field of speaker identification, can solve the problems of affecting system identification performance, high error rate of speaker identification, unfavorable identification tasks, etc.
Active Publication Date: 2021-03-23
HARBIN INST OF TECH
View PDF7 Cites 0 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
However, the current total change space estimation methods do not consider the needs of the task, which is not conducive to the identification task, and then affects the recognition performance of the system, resulting in a high error rate in speaker identification.
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
specific Embodiment approach 1
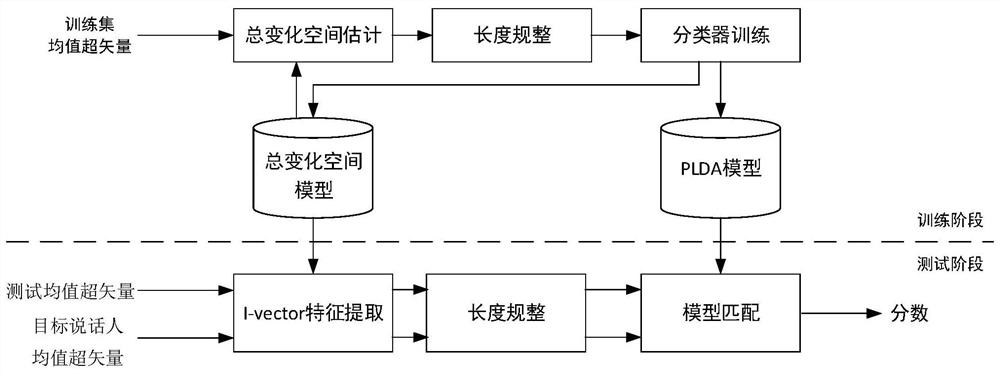
[0026] Specific implementation mode one: as figure 1 As shown, the speaker identification method based on the joint optimization of the total variation space and the classifier described in this embodiment comprises the following steps:
[0027] Step 1. Input the Mel cepstral coefficients of each segment of speech in the training set into the general background model, and use the maximum a posteriori probability method on the general background model to adapt to obtain the Gaussianmixture model corresponding to each segment of speech. Using the Gaussianmixture model Obtain the mean supervector corresponding to each segment of speech in the training set;
[0028] Then the mean supervector corresponding to each segment of speech in the training set forms the mean supervector set;
[0029] Step 2, calculate the covariance matrix Φ of the mean value m of the mean value supervector corresponding to all segments of speech in the training set and the corresponding mean value super...
specific Embodiment approach 2
[0044] Specific embodiment two: the difference between this embodiment and specific embodiment one is: the Gaussianmixture model is used to obtain the mean supervector corresponding to each section of speech in the training set, and its specific process is:
[0045] Suppose the training set contains a total of S 0 speaker's speech, and the total number of speech segments containing the sth speaker is H s , s=1,2,...,S 0 ;
[0046] According to the mean value μ of all Gaussian components corresponding to the h-th segment of speech of the s-th speaker c , c=1,2,...,C, obtain the mean supervector M corresponding to the h segment of the s speaker's speech s,h ,M s,h The expression is:
[0047]
[0048] Among them: C represents the number of mean values of the Gaussian components corresponding to the h-th segment of the s-th speaker’s speech, μ 1 Represents the mean value of the first Gaussian component corresponding to the h-th segment of speech of the s-th speaker;
...
specific Embodiment approach 3
[0050] Specific implementation mode three: the difference between this implementation mode and specific implementation mode two is: the specific process of said step two is:
[0051]
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
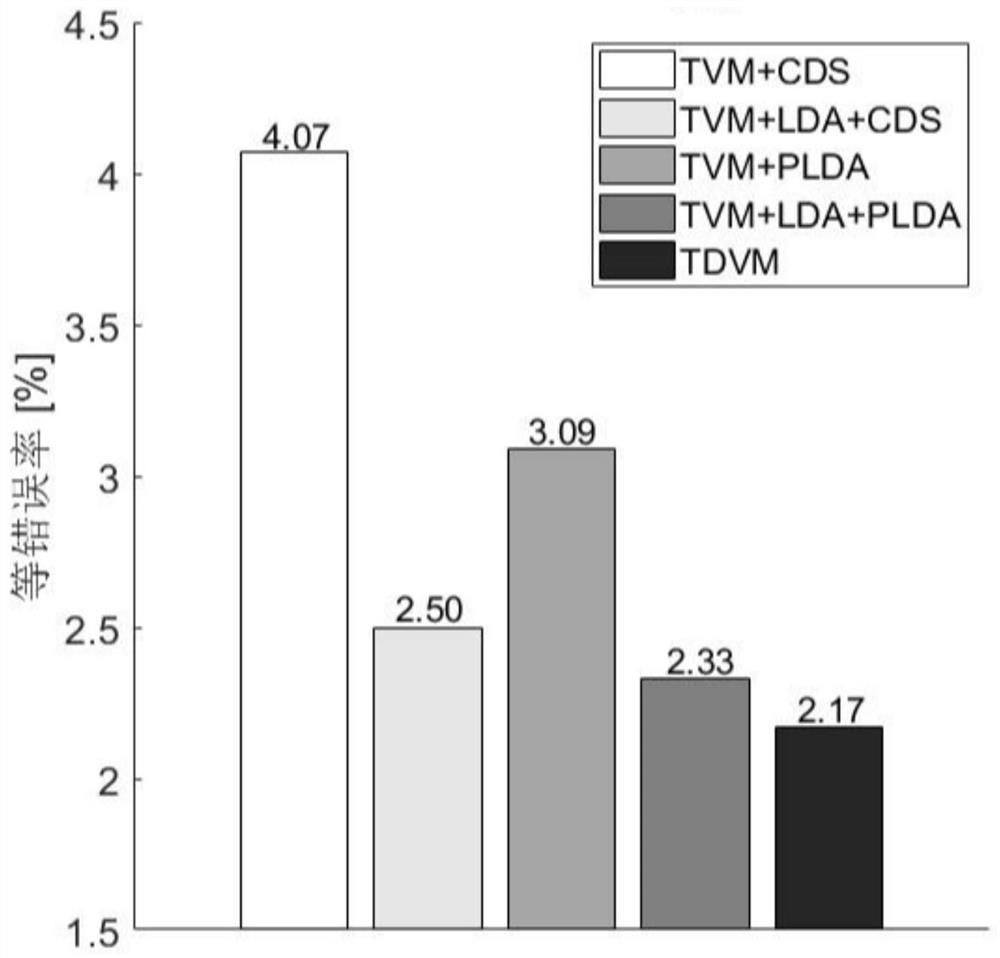
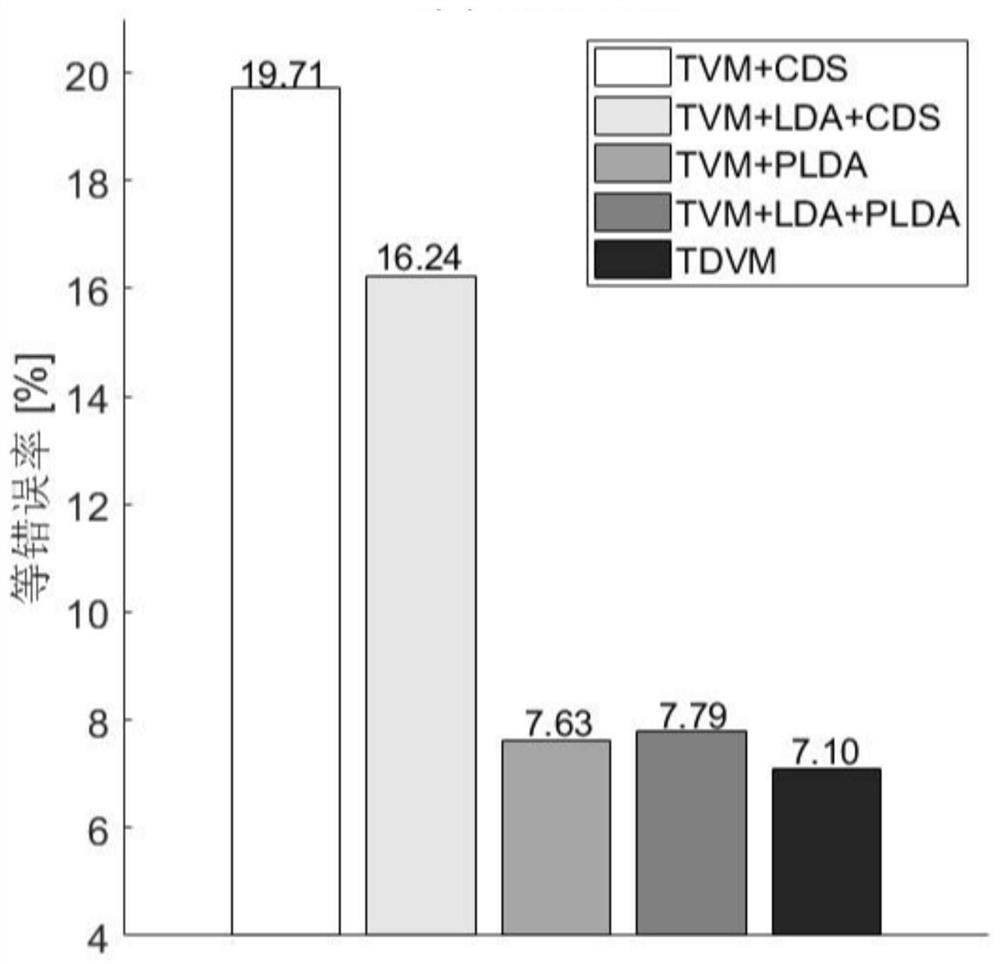
The invention discloses a speaker identity recognition method based on combined optimization of a total change space and a classifier, and belongs to the technical field of speaker identity recognition. The speaker identity recognition method solves the problem that a current total change space estimation method is high in equal error rate for speaker identity recognition. The speaker identity recognition method comprises the steps that firstly, the representation of a training set mean value hyper vector in an initial total change space is obtained; then the length of the representation is normalized and input to the classifier PLDA; then, under the supervision of the classifier PLDA, the parameters of the classifier and parameters of the total change space are updated, the steps are repeated until the set maximum number of iterations is reached, and the final classifier parameters and the total change space parameters are obtained; and during the test, the mean hyper vector of a testspeech and the mean hyper vector of a target speaker are used for calculating the representation of the mean hyper vectors in the total change space, then the length of the representation is normalized, and the joint probability density of the mean hyper vectors on the classifier is calculated as the basis for final classification. The speaker identity recognition method can be applied to the technical field of speaker identification.
Description
technical field [0001] The invention belongs to the technical field of speaker identification, and in particular relates to a speaker identification method based on joint optimization of a total variation space and a classifier. Background technique [0002] Speech is an important information carrier for human beings to communicate emotion and cognition, and it is the most basic and natural way of communication in life and work. With the development of information technology, it is possible to identify the identity of the speaker by analyzing the personal characteristics in the speech signal. Speaker identification technology also has a broad space for development because of its good accuracy, economy and scalability. Among many speaker identification technologies, the speaker identification method based on the identity-vector (i-vector) framework is the most widely used due to its excellent performance and high efficiency. [0003] The core technology of the I-vector fram...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More