

Asynchronous distributed deep learning training method, device and system
A technology of deep learning and training methods, applied in neural learning methods, transmission systems, special data processing applications, etc., can solve the problems that cannot be directly applied, cannot solve the bottleneck of asynchronous stochastic gradient communication, etc., and achieve the effect of reducing the amount of communication
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

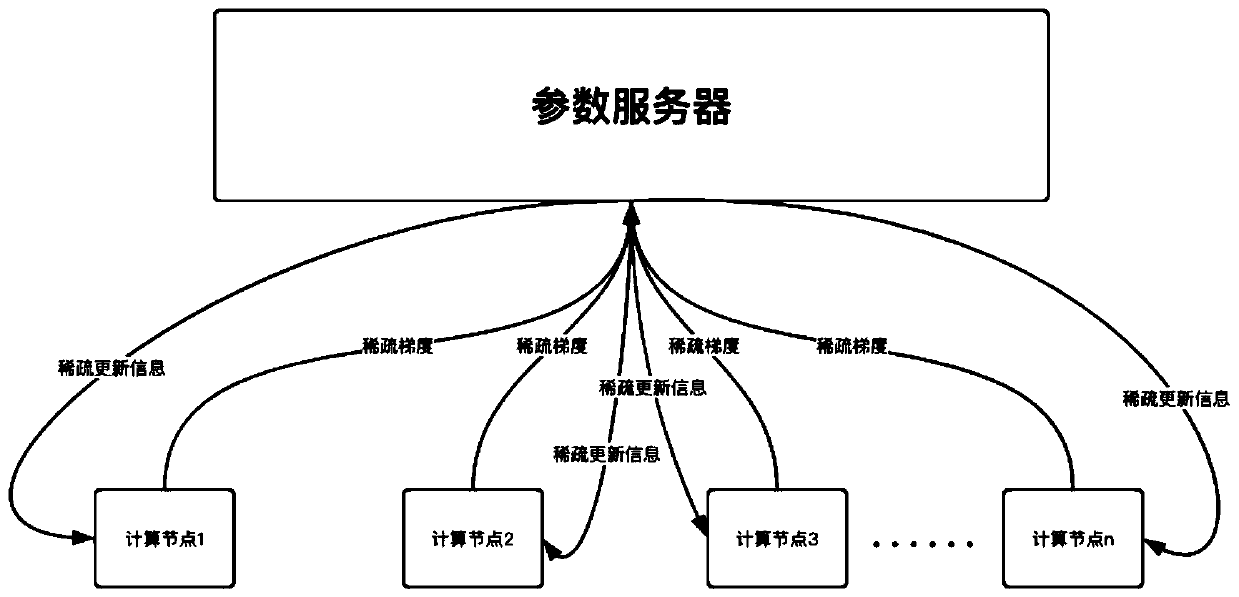
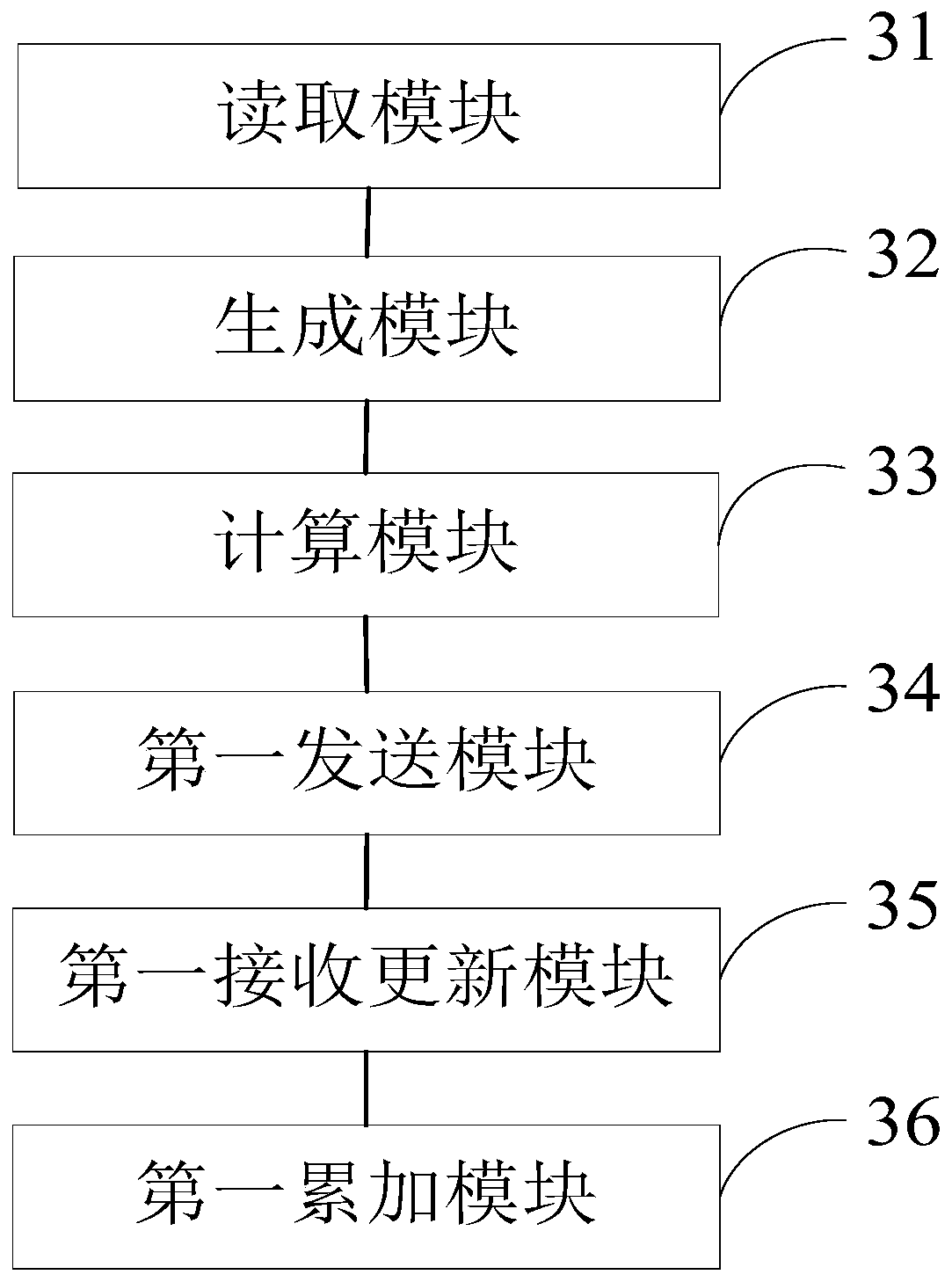
Examples
Embodiment Construction
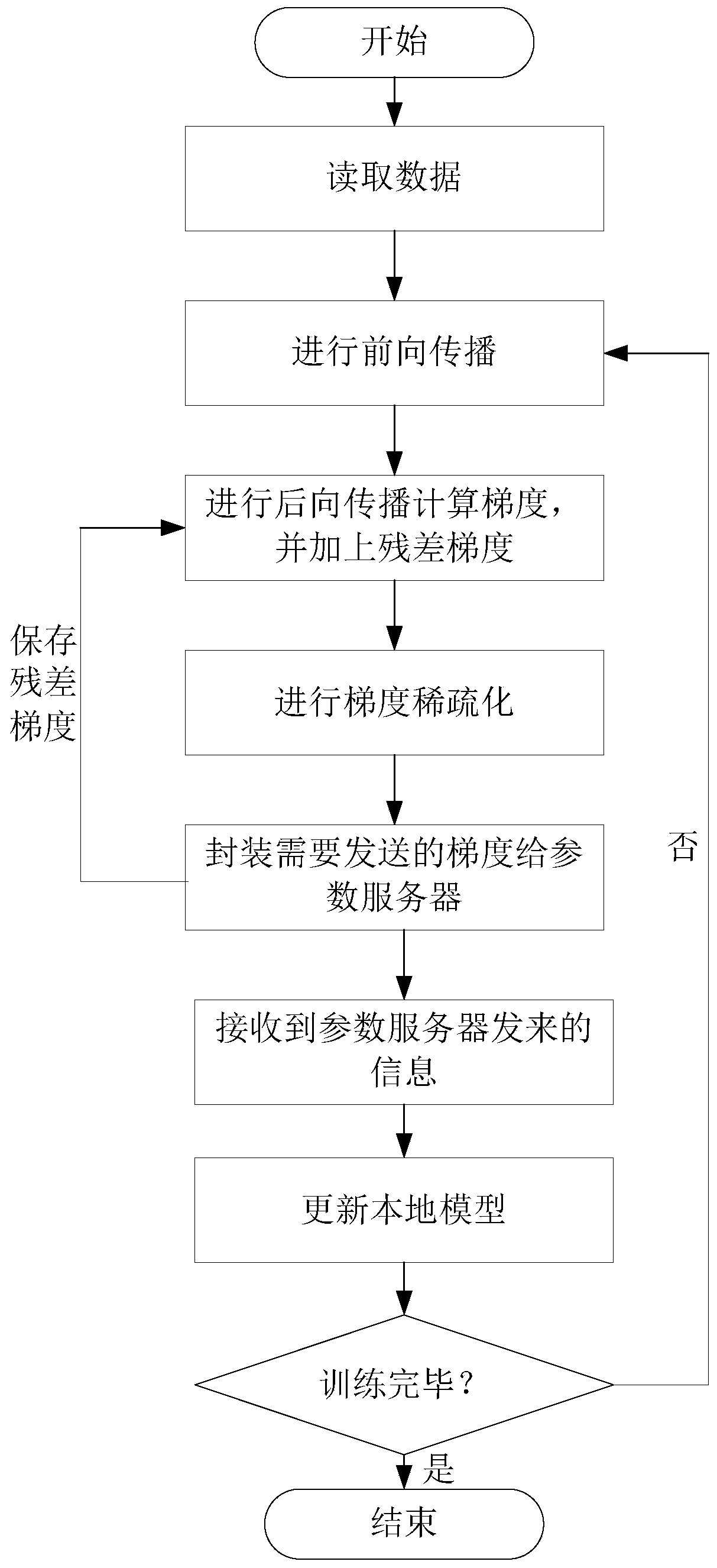
[0064] Exemplary embodiments of the present disclosure will be described in more detail below with reference to the accompanying drawings. Although exemplary embodiments of the present disclosure are shown in the drawings, it should be understood that the present disclosure may be embodied in various forms and should not be limited by the embodiments set forth herein. Rather, these embodiments are provided for more thorough understanding of the present disclosure and to fully convey the scope of the present disclosure to those skilled in the art.
[0065] In order to facilitate the description of the parameters used in the embodiments of the present invention, the following descriptions are given first:
[0066] x: model parameter;
[0067] t: model parameter version number t;
[0068] t sync : The parameter version number when the model is soft-synchronized;
[0069] k: the kth computing node;
[0070] gradient vector;
[0071] i-th gradient element;
[0072] σ: co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More