

Multi-speaker voice separation method based on convolutional neural network and depth clustering
A convolutional neural network and speech separation technology, applied in biological neural network models, speech analysis, neural architecture, etc., can solve the problem that the system model cannot use three-speaker mixed signal speech separation, and the separation model cannot use speaker speech separation , can not expand the speaker voice separation and other problems, to achieve the effect of less parameters, reduce parameters, and improve performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
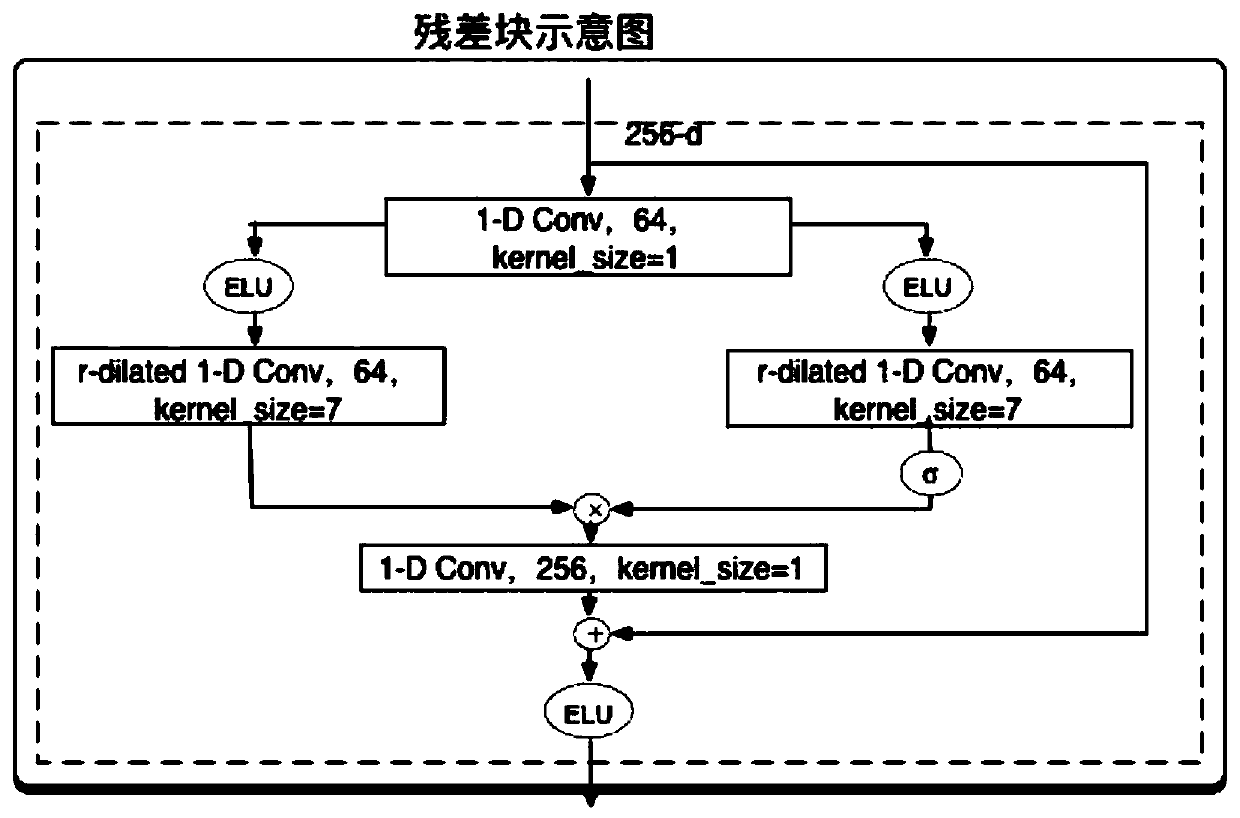
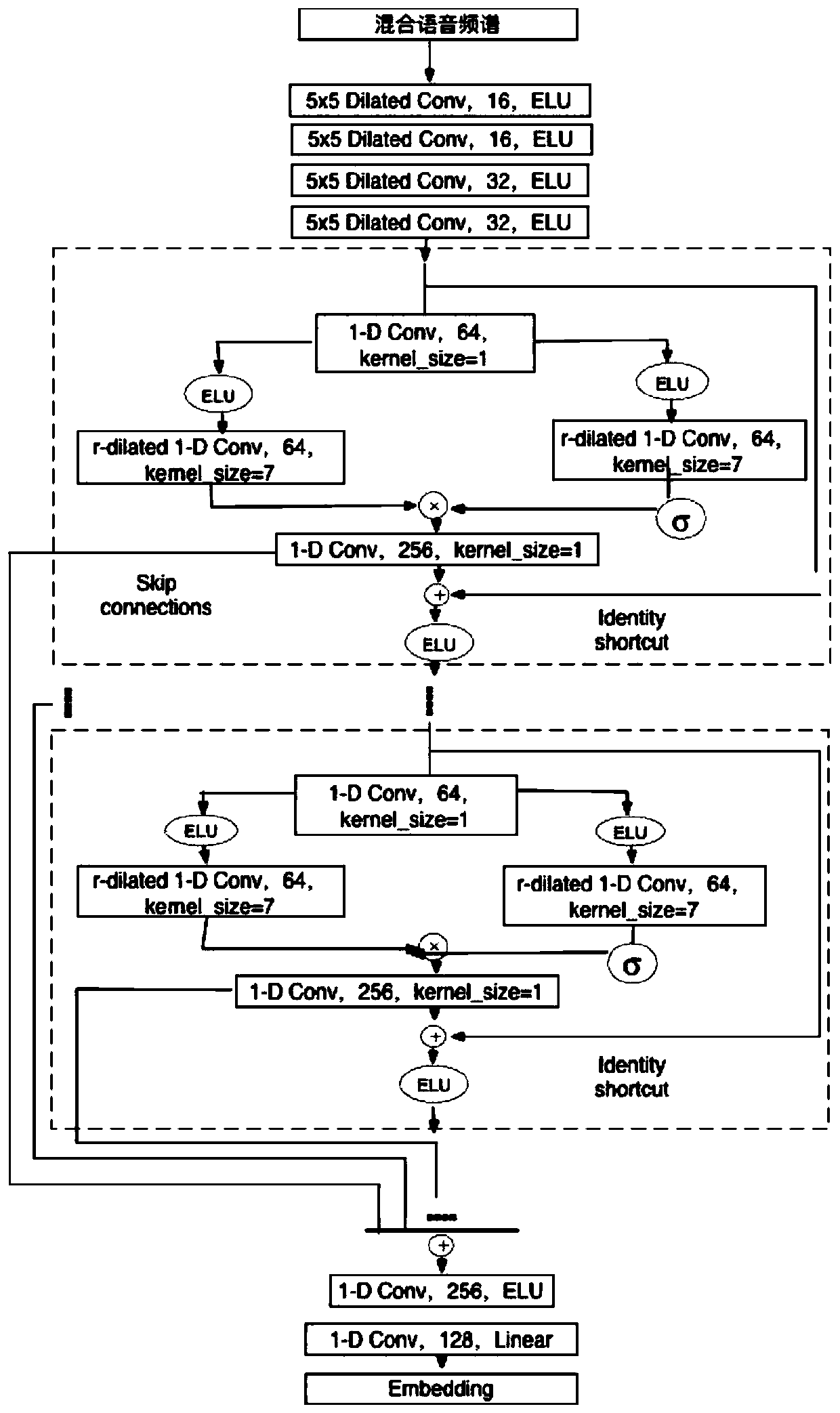
[0042] The embodiment of the present invention provides a multi-speaker speech separation method based on convolutional neural network and deep clustering, which includes two steps during implementation: training the separation network model and using the separation network to realize single-speaker speech separation. figure 1 It is a flow chart of the multi-speaker speech separation method based on convolutional neural network and deep clustering. This process is followed when training the separation network model and using the separation network to achieve single-speaker speech separation. Only when training the network model, it needs to be calculated according to The model continuously updates the network parameters, while the network parameters remain unchanged when the speech separation system is running to separate the mixed speech from single-speaker speech; in addition, when training the network, execute figure 1 Mixed speech features--threshold expansion convolutional...
Embodiment 2
[0065] Specific description of the speech separation problem
[0066] The goal of mono speech separation is to estimate individual source signals that are mixed together and overlapped in a mono signal. The S source signal sequences are denoted as x in the time domain s (t), s=1,..., S, and express the mixed signal sequence in the time domain as:
[0067]
[0068] Framing, windowing, and short-time Fourier transform are performed on the speech signal to obtain the spectrum of the speech signal. Specifically, take 32ms sampling points as a frame signal, if the sampling rate is 8kHz, then one frame is 256 sampling points, if the sampling frequency is 16kHz, then one frame is 512 sampling points, if the length is less than 32ms, first The number of sampling points is zero-padded to 256 or 512; then, windowing is performed on each frame signal, and the windowing function adopts a Hamming window or a Hanning window. The corresponding short-time Fourier transform (STFT) is X ...
Embodiment 3
[0108] Experimental results show that the present invention adopts the separation network model based on convolutional neural network and deep clustering, even for the situation that the speaker's voice in the mixed voice has the same energy (such as the WSJ0 corpus), and for the presence of non-participating in the voice to be separated The case where the model is trained on speakers (i.e. the model is "speaker-agnostic") also performs well. Experimental results show that the trained network model can effectively separate single speaker speech. The deep learning model learns acoustic cues, which are neither speaker nor language-independent, for source separation and account for the property of amplitude spectrogram region correlation.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More