Data processing method and device based on Spark Streaming, computer equipment and storage medium
A data processing and data storage technology, applied in the direction of electrical digital data processing, special data processing applications, computing, etc., can solve the problems of SparkStreaming throughput decline, processing request ability decline and other problems, to improve throughput, reduce the number of requests, improve The effect of stability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
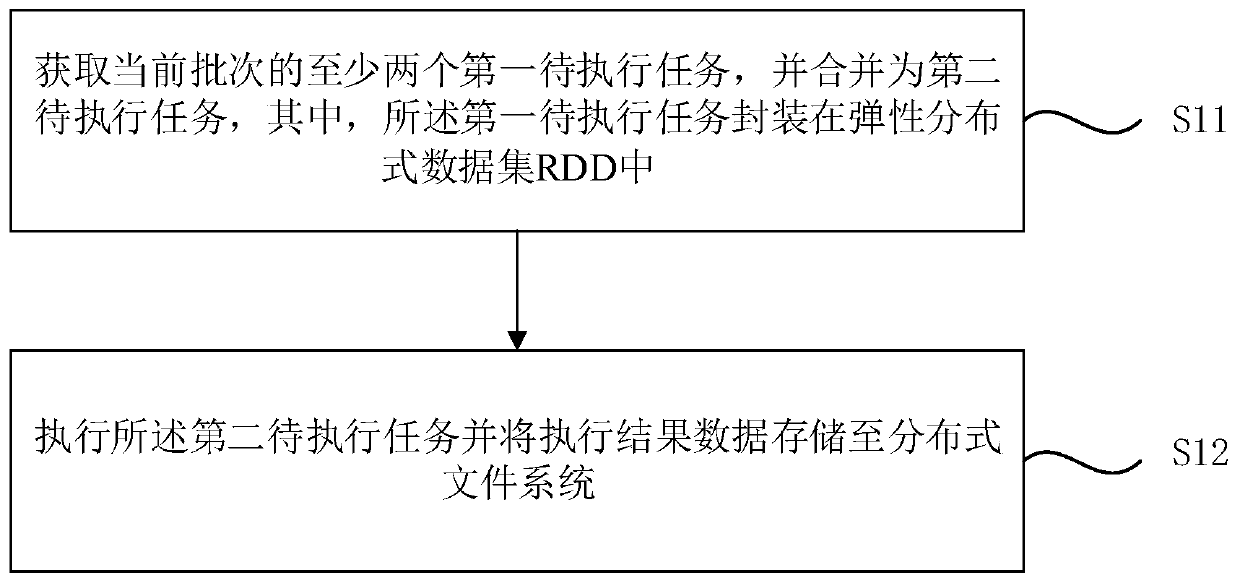
[0025] figure 1 It is a flow chart of the data processing method based on Spark Streaming provided by Embodiment 1 of the present invention. This embodiment is applicable to the situation where Spark Streaming is used for data processing for a long time, and the method can be executed by the data processing device based on Spark Streaming provided by the embodiment of the present invention, and the device can be implemented by hardware and / or software, Generally, it can be integrated into a computer device, such as a personal computer (Personal Computer, PC). Such as figure 1 As shown, it specifically includes the following steps:
[0026] S11. Obtain at least two first to-be-executed tasks of the current batch, and merge them into a second to-be-executed task, wherein the first to-be-executed tasks are encapsulated in an elastic distributed data set RDD.
[0027] Spark is a fast and general-purpose computing engine designed for large-scale data processing. It is an open-so...
Embodiment 2
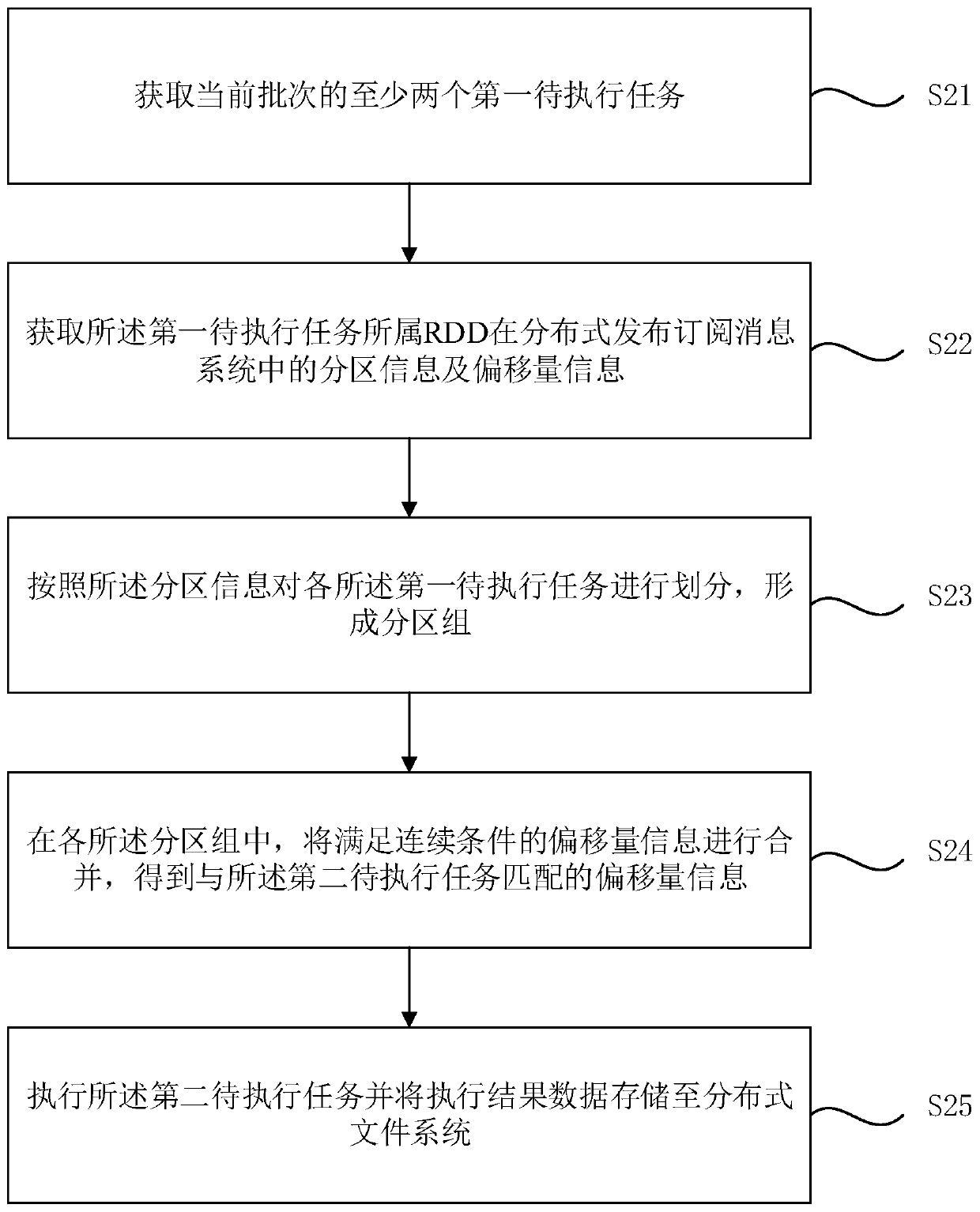
[0051] figure 2 It is a flow chart of the data processing method based on Spark Streaming provided by Embodiment 2 of the present invention. The technical solution of this embodiment is further refined on the basis of the above-mentioned technical solution. In this embodiment, the situation of selecting the distributed publish-subscribe message system Kafka for the data source is further explained, and the technical solution is refined by using the unique structure of Kafka . Such as figure 2 As shown, it specifically includes the following steps:
[0052] S21. Obtain at least two first to-be-executed tasks of the current batch.
[0053] For the current batch, the first task to be executed, etc. in this embodiment, reference may be made to the description of the foregoing embodiments.
[0054] S22. Obtain partition information and offset information of the RDD to which the first task to be executed belongs in the distributed publish-subscribe message system.
[0055] Th...
Embodiment 3
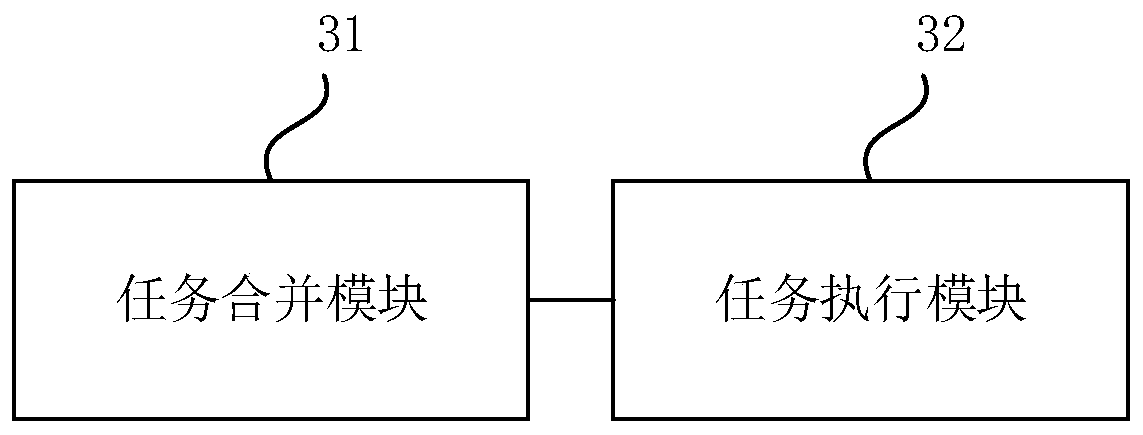
[0075] image 3 A schematic structural diagram of a data processing device based on Spark Streaming provided by Embodiment 3 of the present invention. The device can be realized by means of hardware and / or software, and generally can be integrated into computer equipment, such as a personal computer (Personal Computer, PC). Such as image 3 As shown, the device includes:
[0076] A task merging module 31, configured to obtain at least two first to-be-executed tasks of the current batch and merge them into a second to-be-executed task, wherein the first to-be-executed task is encapsulated in the elastic distributed data set RDD;
[0077] The task execution module 32 is configured to execute the second to-be-executed task and store the execution result data in the distributed file system.
[0078] In the technical solution provided by the embodiment of the present invention, the acquired tasks of the current batch are combined and then executed, and the execution result data ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com