Transverse federation learning system optimization method and device and readable storage medium
A technology of learning system and optimization method, applied in the field of machine learning, can solve the problems of high consumption of computing resources and high cost of model training time, and achieve the effect of reducing interaction and improving generalization ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0035] It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
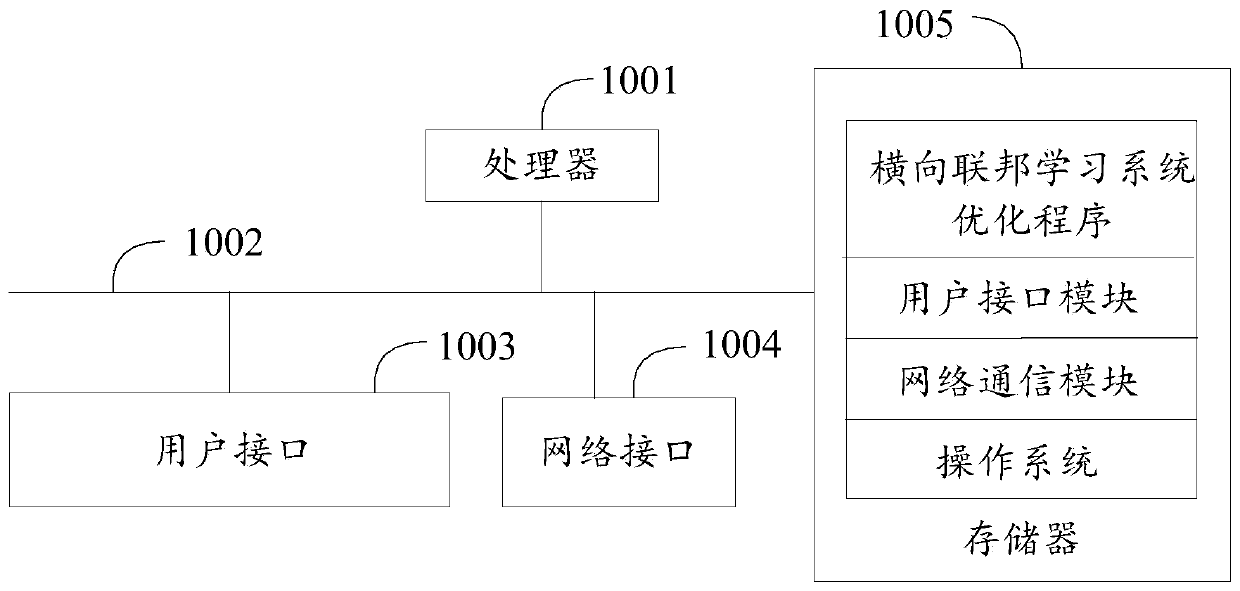
[0036] Such as figure 1 as shown, figure 1 It is a schematic diagram of the device structure of the hardware operating environment involved in the solution of the embodiment of the present invention.
[0037] It should be noted that the horizontal federated learning system optimization device in this embodiment of the present invention may be a smart phone, a personal computer, a server, etc., and no specific limitation is set here.
[0038] Such as figure 1 As shown, the horizontal federated learning system optimization device may include: a processor 1001 , such as a CPU, a network interface 1004 , a user interface 1003 , a memory 1005 , and a communication bus 1002 . Wherein, the communication bus 1002 is used to realize connection and communication between these components. The user interface 1003 may include ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com