

Microblog rumor detection method
A detection method and rumor technology, applied in natural language data processing, unstructured text data retrieval, instruments, etc., can solve problems such as vector feature difference, distinction, and ignoring context word order features, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

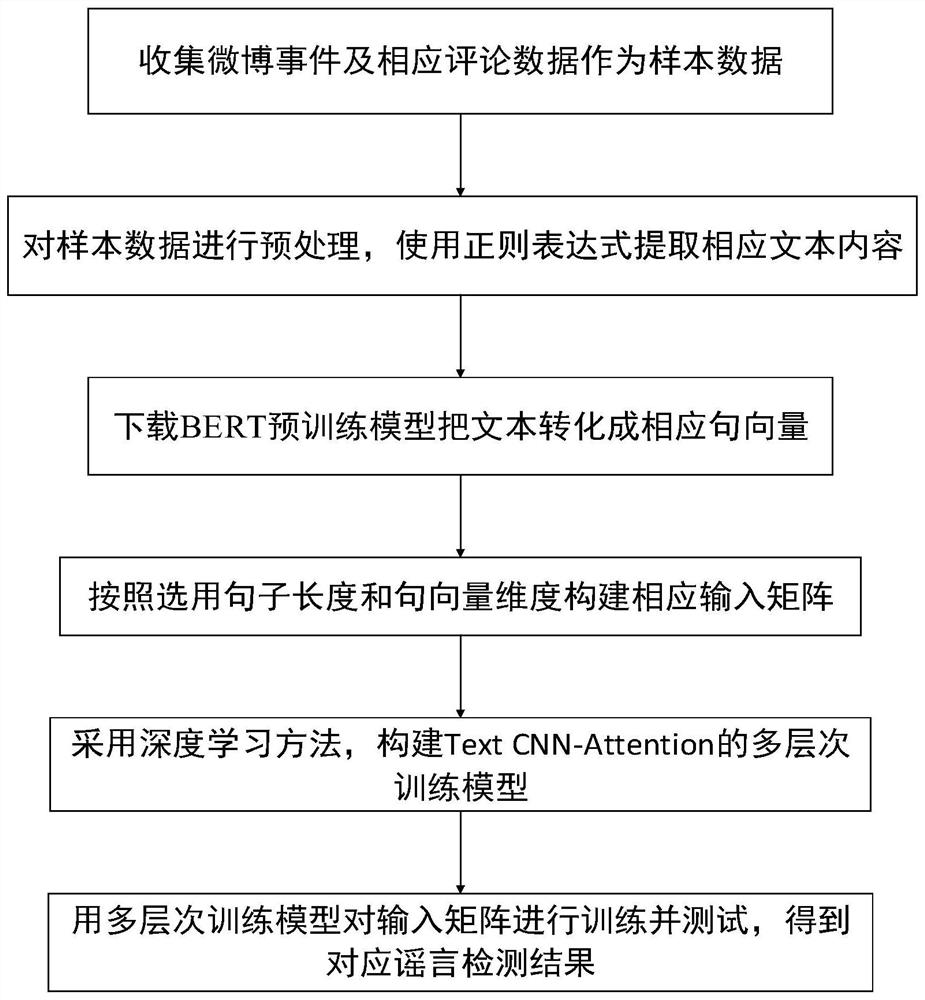
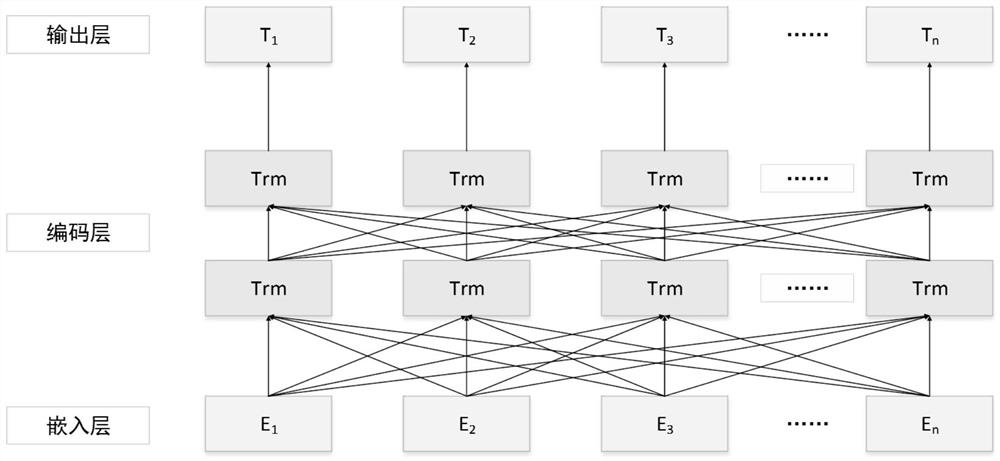
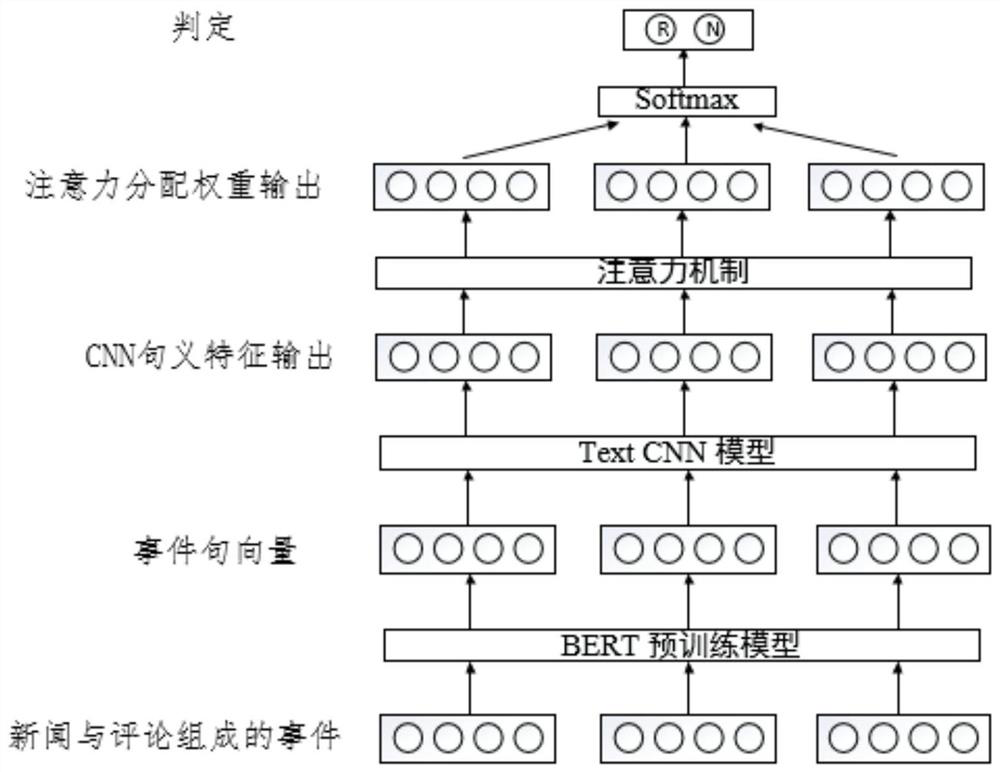
Examples
Embodiment 1
[0070] In order to prove the effectiveness of the present invention, we selected a series of event data based on Weibo platform compiled by Ma et al. and used in the paper. This data set is the original information captured through the Weibo API and all reposts and Reply, also grabbed general topic posts that were not reported as rumors and collected a similar number of rumor events, the detailed statistics are listed in the table below:
[0071]
[0072] We divide all the data according to the ratio of 4:1 between the training set and the test set. The specific division is listed in the following table:
[0073]
[0074]
[0075] The evaluation indicators we use to evaluate the effectiveness of the model are accuracy rate, precision rate, recall rate and F1 value. The results of prediction and actual results are listed in the following table:
[0076]
[0077] There are four baseline methods we use for comparison, namely SVM-TS, CNN-1, CNN-2, and CNN-GRU. The deta...
Embodiment 2
[0081] In order to prove the feasibility of our method, we also selected another Weibo dataset CED_Data set[23] for experimentation, and compared the accuracy rates obtained by using the sentence vectors obtained from the same pre-trained model to train on different training models. The data set contains 1538 rumor events and 1849 non-rumor events. We conduct experiments according to the ratio of 4:1 between the training set and the test set. The experimental data are listed in the table below. The MATLAB simulation diagram of the experimental results is as follows Figure 7 Shown:
[0082]
[0083] The experimental results show that the sentence vectors obtained through the BERT pre-training model will still have deviations in accuracy when trained on different training models, but the magnitude of the deviation is smaller than that of using different pre-training models before. Through experiments, it can be concluded that the accuracy rate of SVM-TS is about 86.7%, follo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More