

Cache value-based Spark cache elimination method and system
A cache and value technology, applied in the field of big data computing, can solve problems such as ignoring future reuse times, inaccurate calculation costs, and weakened computing power, so as to improve computing speed, optimize memory resource utilization, and reduce running time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0040] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
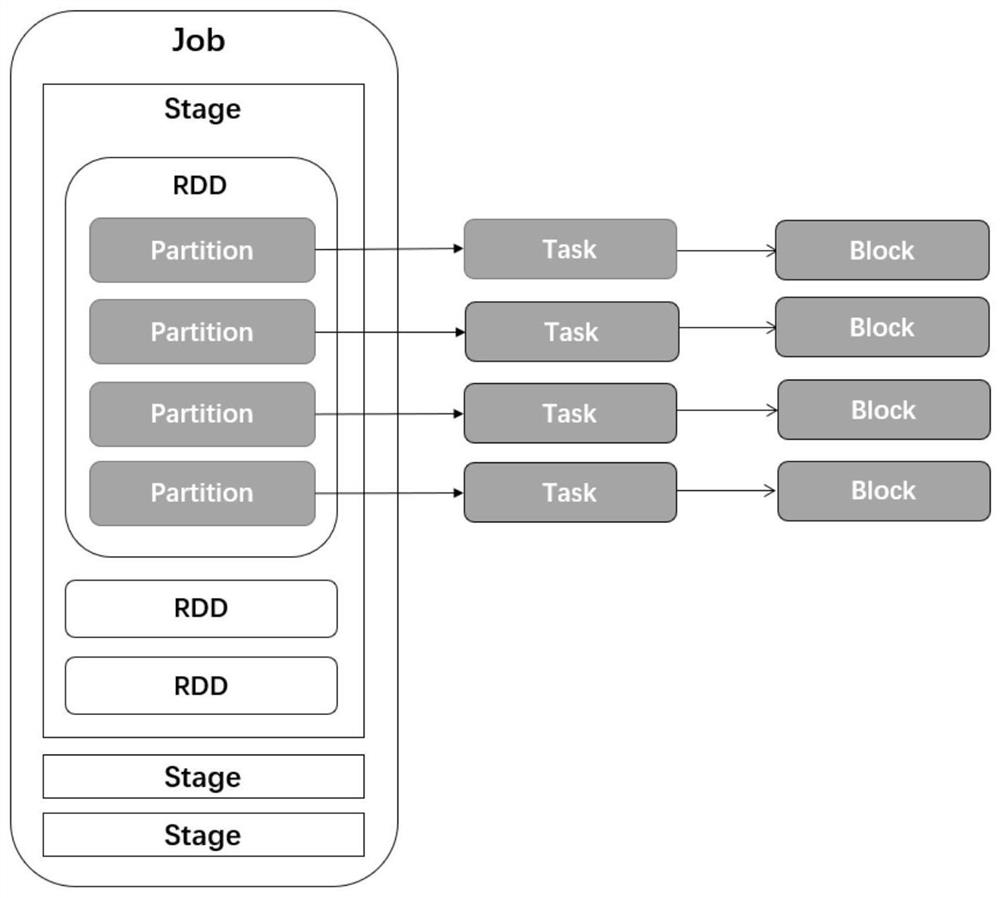
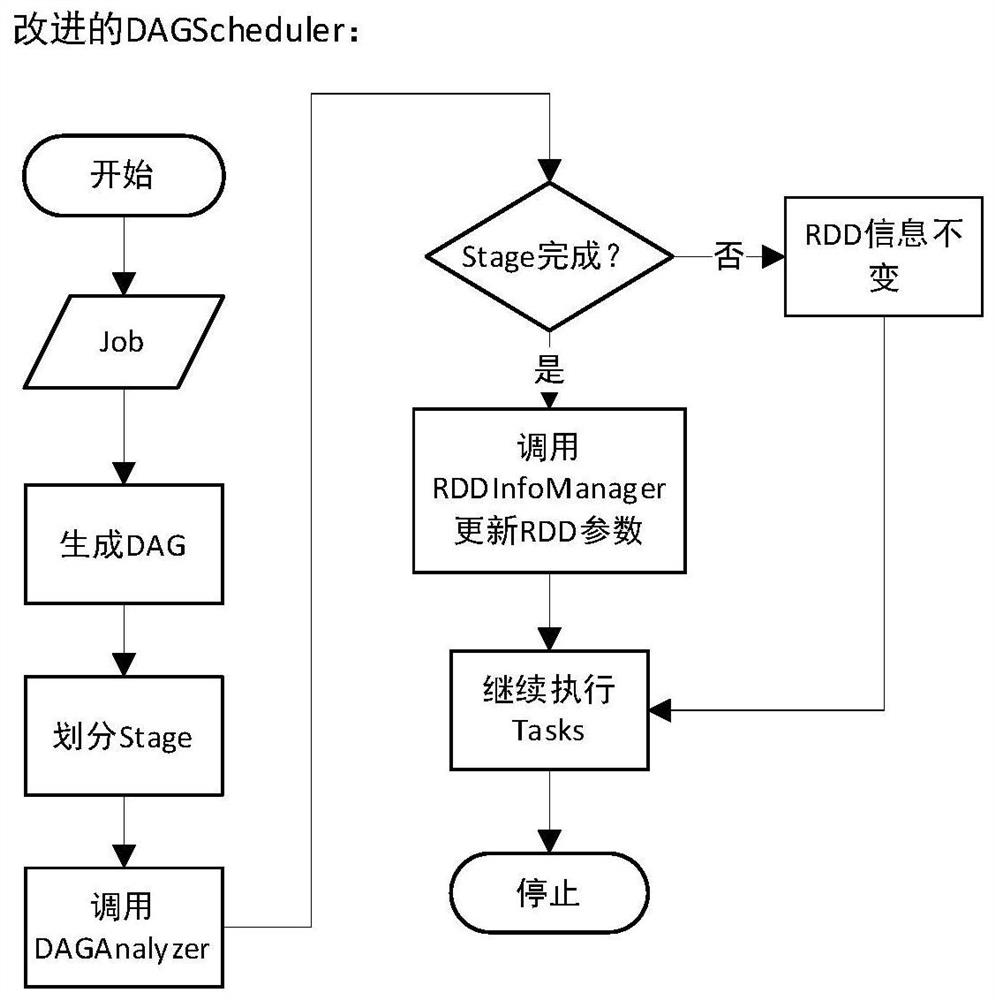
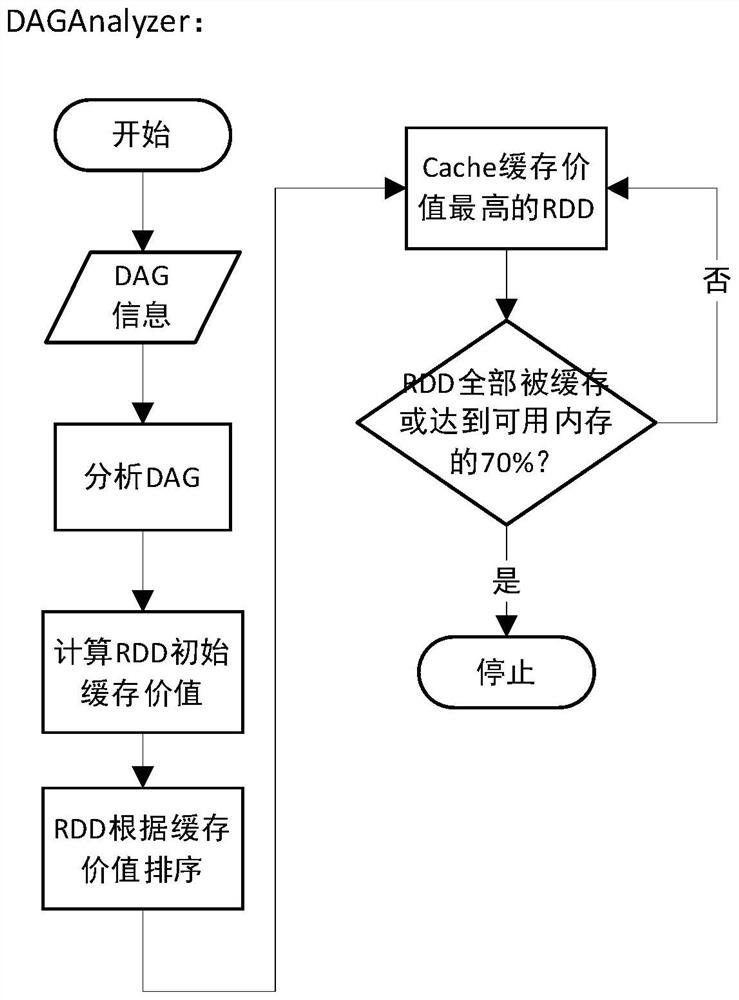
[0041] The present invention provides a Spark cache elimination method and system based on cache value. According to the DAG graph of Spark Job, the usage of RDD and Block in Job is obtained, and the cache value of RDD and Block is defined. The cache value referred to in this specification is high Including: the RDD or Block that is most frequently used and the closest calculation has a high cache value; if the cache value of a Block is zero, it means that the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More