

Data storage method and terminal based on consistent hash algorithm
A hash algorithm and data storage technology, applied in the direction of electrical digital data processing, digital data information retrieval, special data processing applications, etc., can solve the problems of uneven distribution of nodes, it is difficult to ensure continuous uniformity, etc., and achieve enhanced redundancy security performance, improving usage efficiency, and improving search efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0088] Please refer to figure 1 and image 3 , Embodiment 1 of the present invention is:
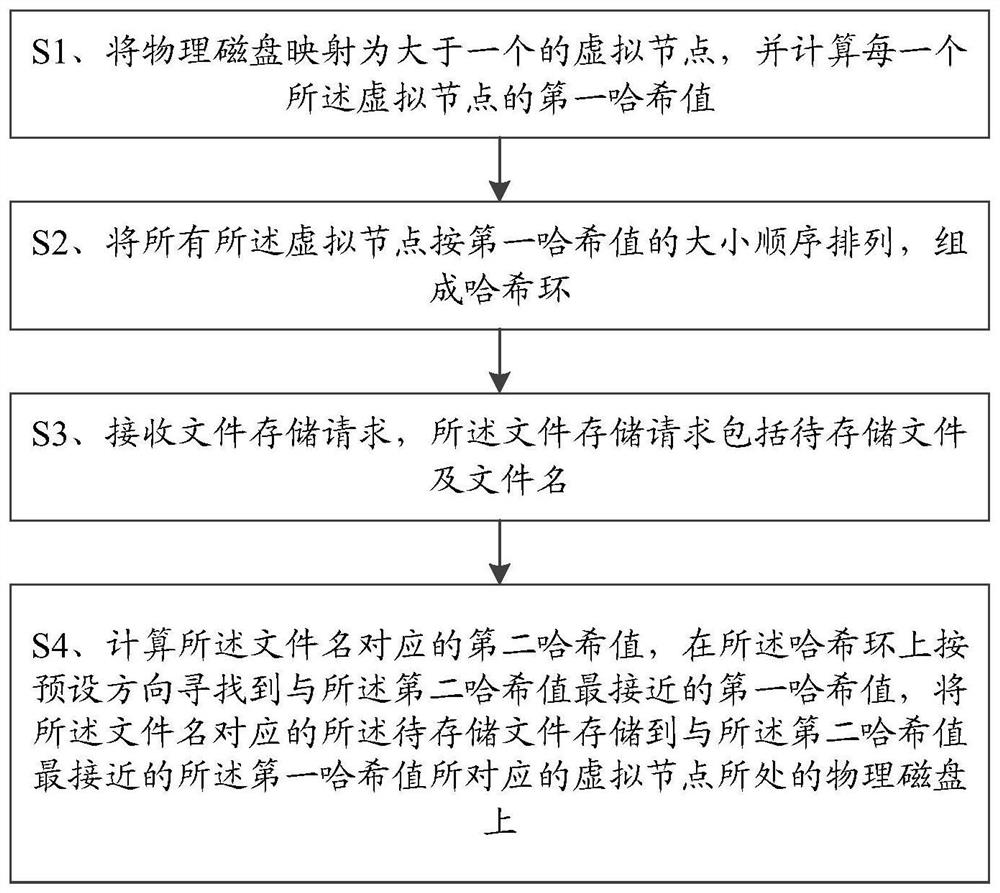
[0089] A data storage method based on a consistent hash algorithm, comprising steps:
[0090] S1. Construct a physical disk sequence table, and map each physical disk in the physical disk sequence table to more than one virtual node;
[0091] S2. Arranging all the virtual nodes corresponding to all the physical disks in the physical disk sequence table according to the order of the first hash value to form a hash ring;
[0092] In an optional implementation manner, the hash ring, that is, the topology logic structure of each virtual node is a chord ring;
[0093] S3. Receive a file storage request, the file storage request includes a file to be stored and a file name, and uses the file name as a storage key (key value);
[0094] S4. Calculate the second hash value corresponding to the file name, find the first hash value closest to the second hash value on the hash ring according to ...
Embodiment 2
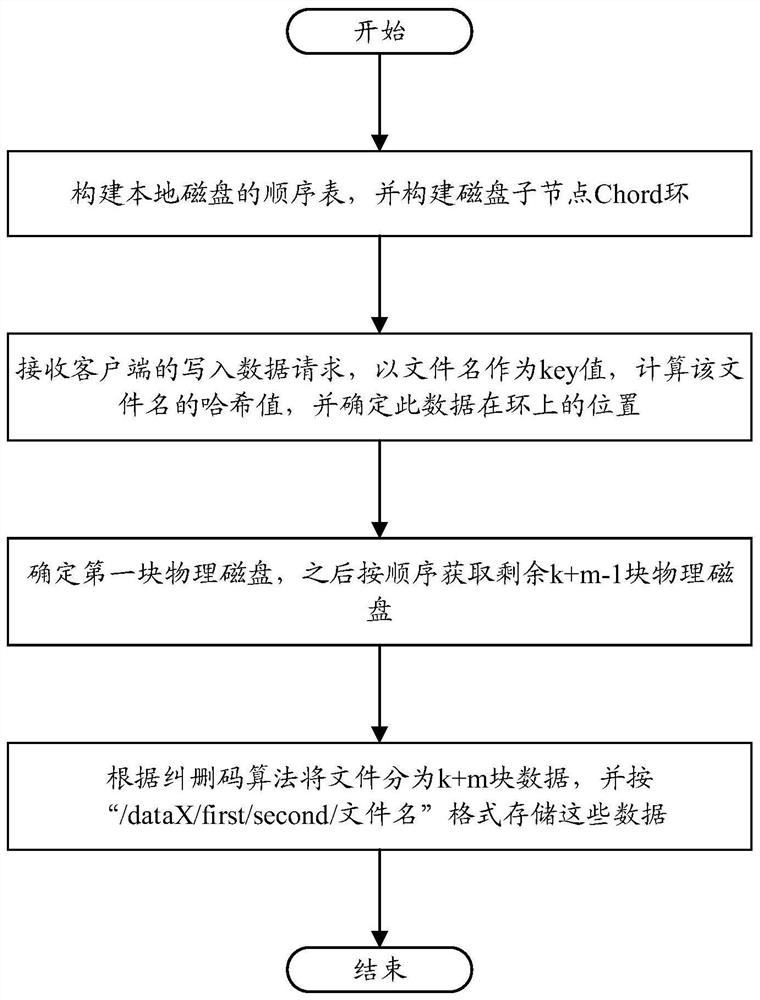
[0103] Please refer to Figure 7 , the second embodiment of the present invention is:
[0104] A data storage method based on a consistent hash algorithm, which differs from Embodiment 1 in that:
[0105] Also includes expansion:
[0106] Adding a third physical disk to the physical disk sequence table, mapping the third physical disk to more than one child node, and calculating a third hash value of each of the child nodes;
[0107] Put each of the child nodes into the hash ring according to the third hash value;
[0108] Obtain an adjacent virtual node adjacent to the child node, and obtain an adjacent hash value corresponding to the adjacent virtual node;
[0109] Calculating the second hash value of all stored files, and storing the files to be stored whose second hash value is within the interval between the third hash value and the adjacent hash value into the third physical disk;
[0110] Also includes removing physical disks:
[0111] Delete the fourth physical di...
Embodiment 3
[0121] Please refer to Figure 3 to Figure 6 , Embodiment three of the present invention is:
[0122] Apply the above-mentioned data storage method based on the consistent hash algorithm to the actual scene:
[0123] (1) if image 3 As shown, construct the local disk sequence table A, B...N with a total of N disks;
[0124] (2) Map each disk into several disk sub-nodes (virtual nodes), such as mapping to 10 virtual nodes, the virtual nodes of disk A are A1, A2...A10, and the virtual nodes of disk B are B1, B2...B10 , the virtual nodes of disk N are N1, N2...N10; calculate the hash value of all the above virtual nodes, and place each virtual node on a consistent hash table such as a chord ring according to its hash value. When performing data query, Store all the data on the physical node (disk) corresponding to the virtual node. For example, for data query, the storage location is AX, all are placed on disk A;
[0125] (3) When storing a file, receive the write data reques...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More