

Method convenient for cleaning, integrating and storing massive multi-source heterogeneous data
A multi-source heterogeneous data and data caching technology, applied in structured data retrieval, electronic digital data processing, special data processing applications, etc., can solve problems such as the inability to integrate global factors, reduce the pressure of massive data, and improve robustness sex, reduce the effect of the degree of coupling
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
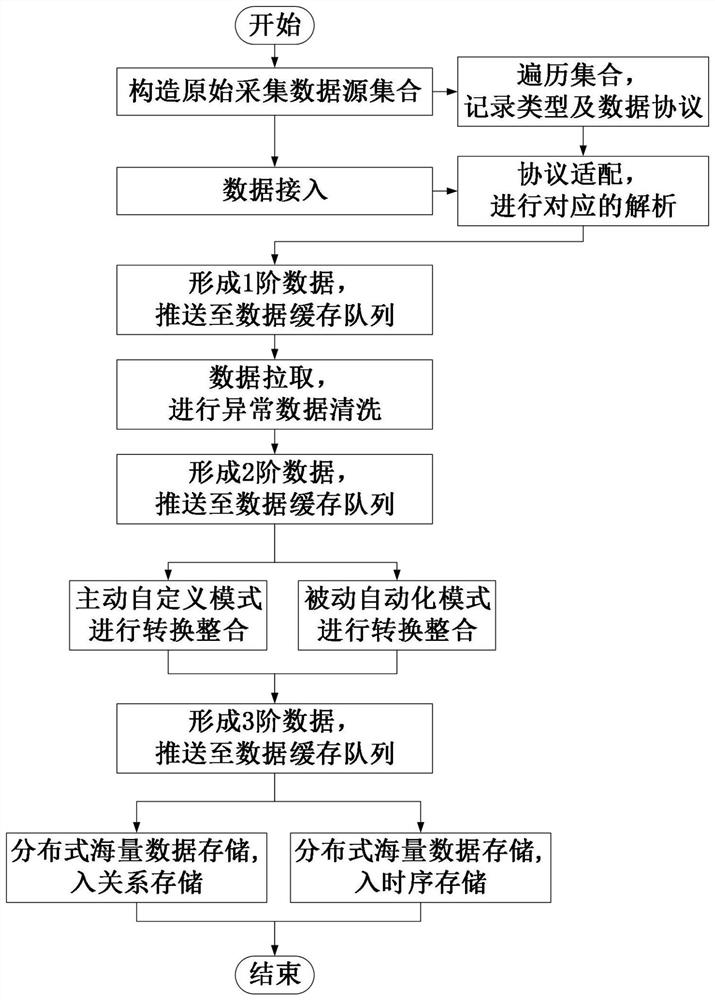
[0027] Specific implementation mode 1: a method for cleaning and integrating storage of massive multi-source heterogeneous data, the method includes the following steps: executing the construction of a data source collection; performing collection traversal, recording type and data protocol; performing data access; and then Through the protocol adaptation link, the first-order data is formed, and the cache queue is pushed; the first-order data is pulled, and the cleaning link is performed to form the second-order data, and the cache queue is pushed; the second-order data is pulled, and the active-passive hybrid mode conversion and integration link is formed to form The third-level data is pushed to the cache queue; the third-level data is pulled, and the distributed storage link is carried out to complete the final storage.
specific Embodiment approach 2
[0028] Specific implementation mode two: according to the method described in his implementation mode one, each step can also be refined into:
[0029] The link of constructing data source collection is to construct a collection of original collected data sources from massive multi-source heterogeneous data sources;
[0030] Traversing the collection link is to record the source type, source number, source dimension and source data protocol of each data source in the collection to form an array list;
[0031] The data access link is the access of data sources before data processing;
[0032] The protocol adaptation link is to perform the corresponding first analysis according to the source type and data protocol of each data source, and the parsed data forms first-level data, which is pushed to the first-level topic in the data cache queue;
[0033] In the cleaning process, firstly, the first-level data is pulled, and then abnormal and problematic data are cleaned and elimina...
specific Embodiment approach 3
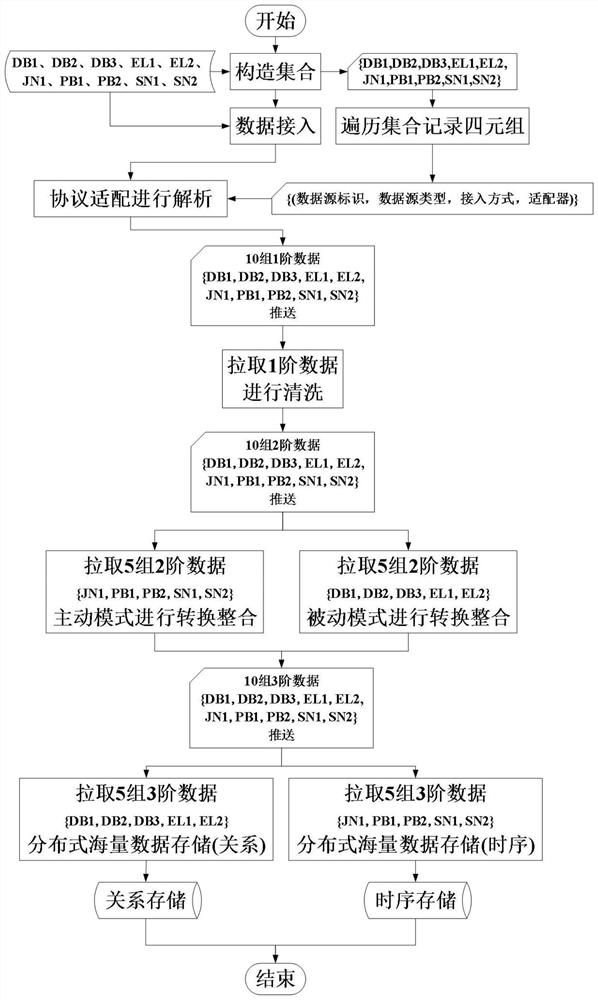
[0036] Specific implementation mode three: the embodiment provides a simulated application scenario. There are three existing database-type data sources: DB1, DB2, DB3, two excel-type data sources: EL1, EL2, one json-type data source: JN1, There are 2 protocol buffer data sources, PB1 and PB2, and 2 sensor data sources: SN1 and SN2. There are 5 types of data sources in total, and the number is 10. Now it is necessary to carry out the complete process of accessing-cleaning-integrating-storing the data of these 10 data sources, then implement the process according to the methods and methods:
[0037] First construct a data source collection, the number of elements in the collection is 10; traverse the collection, record (data source identification, data source type, access method, adapter) quadruples, and form a list:
[0038] {(DB1,DB,JDBC,JavaApi),(DB2,DB,JDBC,JavaApi),(DB3,DB,JDBC,JavaApi),(EL1,EL,FIO,Buffer),(EL2,EL,FIO,Buffer) ,(JN1,JSON,HTTP,Json),(PB1,PB,HTTP,Pb),(PB2,PB...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More