

Real-time sound classification method and system based on FPGA
A classification method and sound technology, applied in speech analysis, biological neural network models, instruments, etc., can solve the problems of large amount of parameters, high power consumption of CPU platform, high computational complexity, etc., and achieve fast processing speed, low cost, and small size small effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
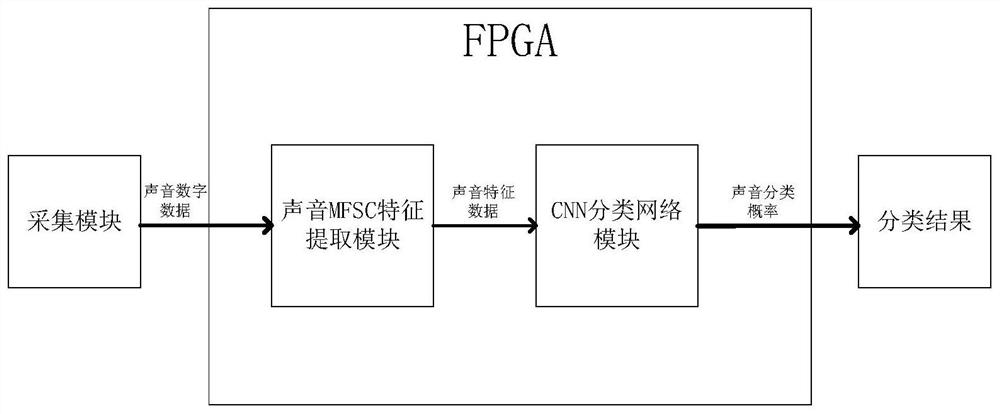
[0073] An FPGA-based real-time sound classification method, such as figure 1 shown, including the following steps:
[0074] S1. Acquiring sound digital data;
[0075] Connect the microphone to the FPGA to obtain sound digital data. The sound data sampling rate is 22050Hz, and the 1.61s sound data is processed as a block;
[0076] S2. Extracting sound features in the acquired sound digital data to obtain a sound feature map;
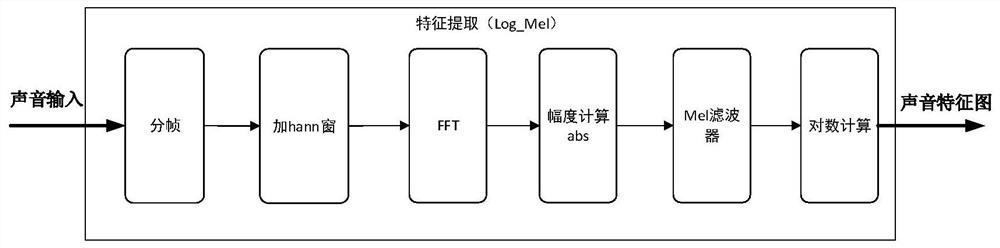
[0077] The sound digital data is first input into the sound feature extraction module in the FGPA, and the sound feature is extracted to obtain the MFSC sound feature map;
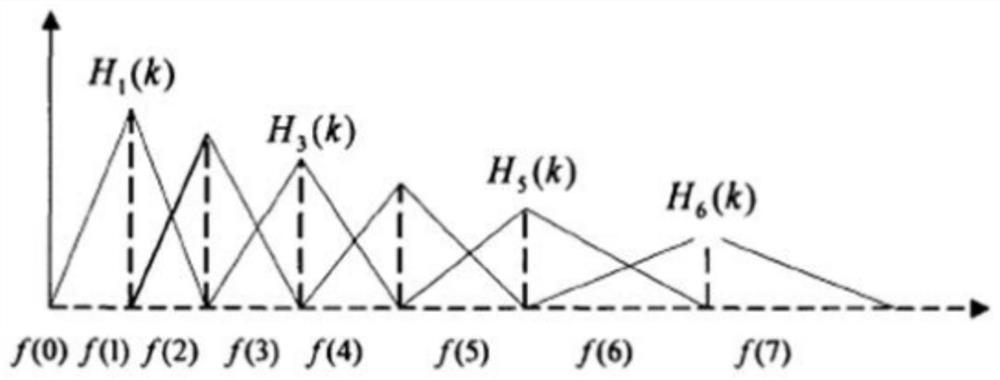
[0078] In this embodiment, the sound data is first input into the framing module, and the sound data is divided into data frames with a length of 512. The number of moving data points between frames is 220. The input is a pipeline operation, and the output is a data frame with a length of 512. Among them, in order to facilitate FFT processing, N points are usually taken as one fram...
Embodiment 2
[0110] A real-time sound classification system based on FPGA, including the following modules:
[0111] Acquisition module, is used for obtaining sound digital data;
[0112] The sound MFSC feature extraction module is used to extract the sound features in the acquired sound digital data, and obtain the sound feature map;
[0113] The CNN classification network module is used to obtain the sound feature map for classification calculation and obtain the sound judgment probability.
[0114] The output module is used to obtain the classification result of the sound according to the maximum probability of the sound judgment.
[0115] Further, the sound MFSC feature extraction module includes:
[0116] A framing module is used for framing the sound digital data to form a data frame;
[0117] Among them, the asynchronous FIFO is used to perform frame division operation on the input sound data.
[0118] A windowing module is used to add a hann window to the data frame to obtain t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More