

Lung sound classification method and system based on deep learning, and storage medium
A technology of deep learning and classification methods, which is applied in the field of biomedical signal recognition, can solve the problems that the function has not been extended to lung sounds, and the training feature value is single, so as to ensure the accuracy of classification and improve the effect of recognition
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
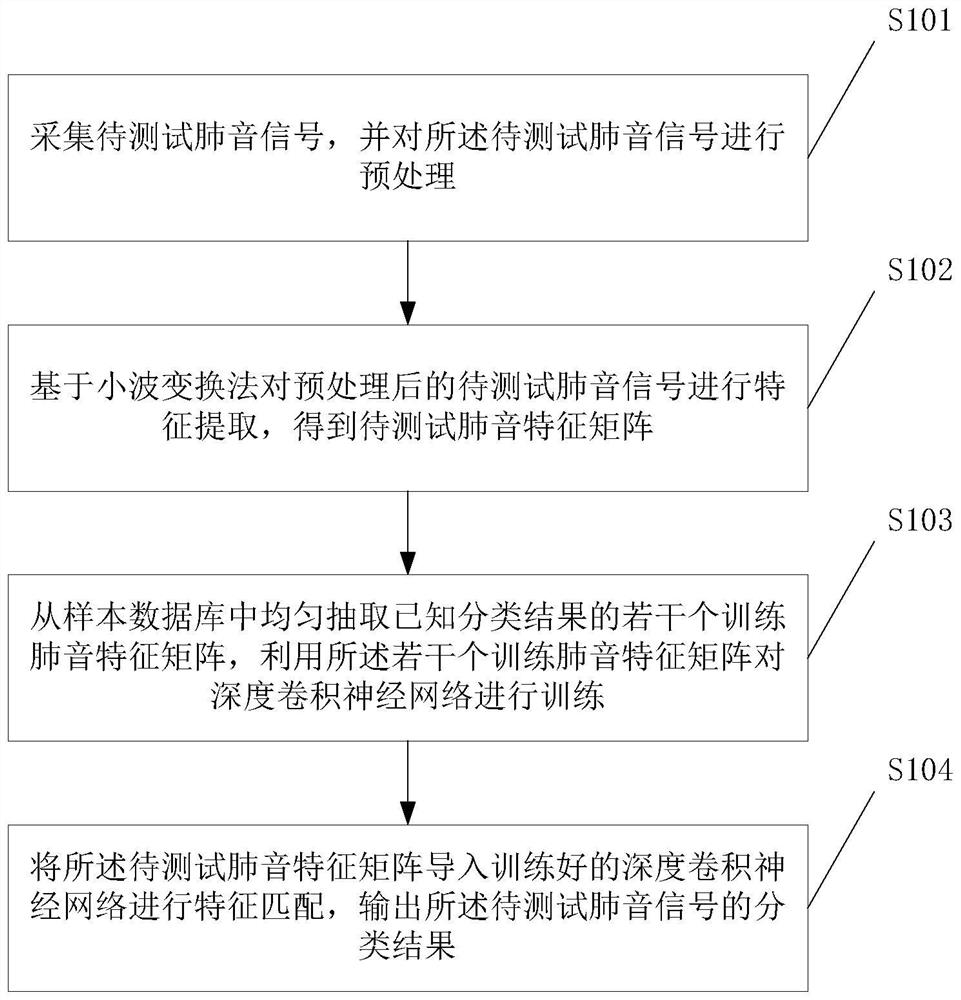
[0043] see figure 1 , figure 1 A schematic flow chart of a lung sound classification method based on deep learning in an embodiment of the present invention is shown.
[0044] Such as figure 1 Shown, a kind of lung sound classification method based on deep learning, described method comprises the steps:
[0045] S101. Collect the lung sound signal to be tested, and preprocess the lung sound signal to be tested;
[0046] The implementation process of the present invention comprises:
[0047] (1) collect the first lung sound signal of the human body in the inhalation state and the second lung sound signal in the exhalation state, and package the first lung sound signal and the second lung sound signal as a test Lung sound signals, and the acquisition time lengths of the first lung sound signal and the second lung sound signal are the same;
[0048] (2) Pre-emphasize the high-frequency part of the lung sound signal to be tested by using a first-order high-pass filter, and th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More