

Multi-mode voice separation method and system
A speech separation and multi-modal technology, applied in speech analysis, neural learning methods, character and pattern recognition, etc., can solve the problems of insufficient data effect, inability to flexibly change the number of inputs, etc., and achieve the effect of improving performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
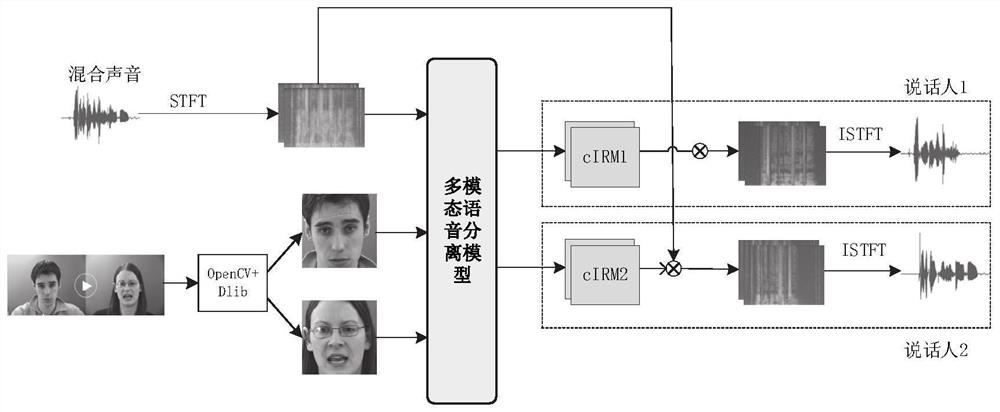
[0060] See attached figure 1 As shown, the present embodiment discloses a multimodal speech separation method, including:
[0061] Receive the mixed voice of the object to be identified and the facial visual information of the object to be identified, and obtain the number of speakers through face detection;
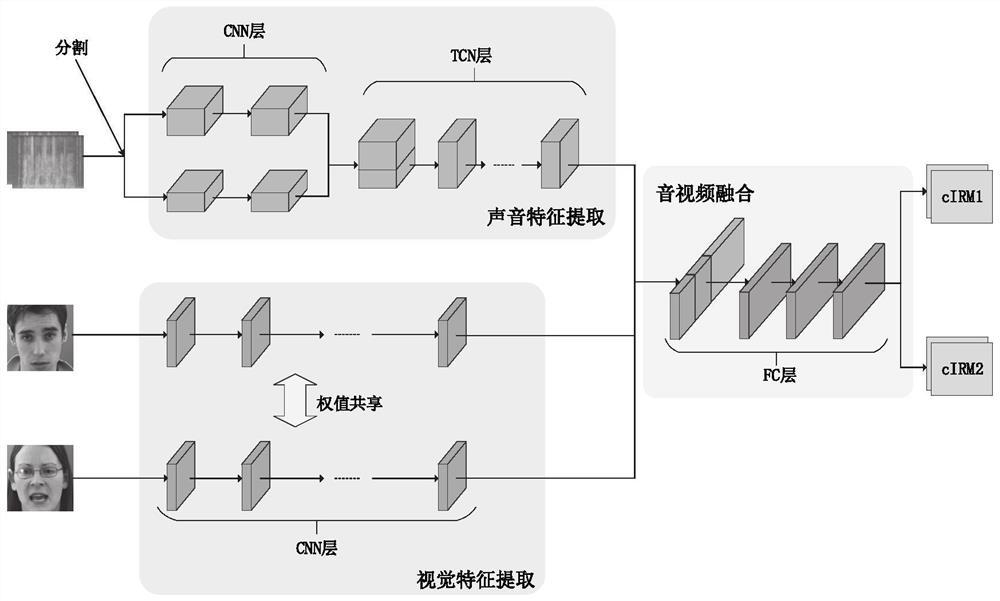
[0062] Process the above information to obtain complex language spectrograms and face images and transmit them to the multi-modal speech separation model, and use the number of speakers to dynamically adjust the structure of the model, wherein, during the training process, the multi-modal speech separation model, Use the complex domain ideal ratio masking cIRM as the training target, cIRM is defined in the complex domain as the ratio between the clean sound spectrogram and the mixed sound spectrogram, consisting of real and imaginary parts and including the amplitude and phase of the sound information;
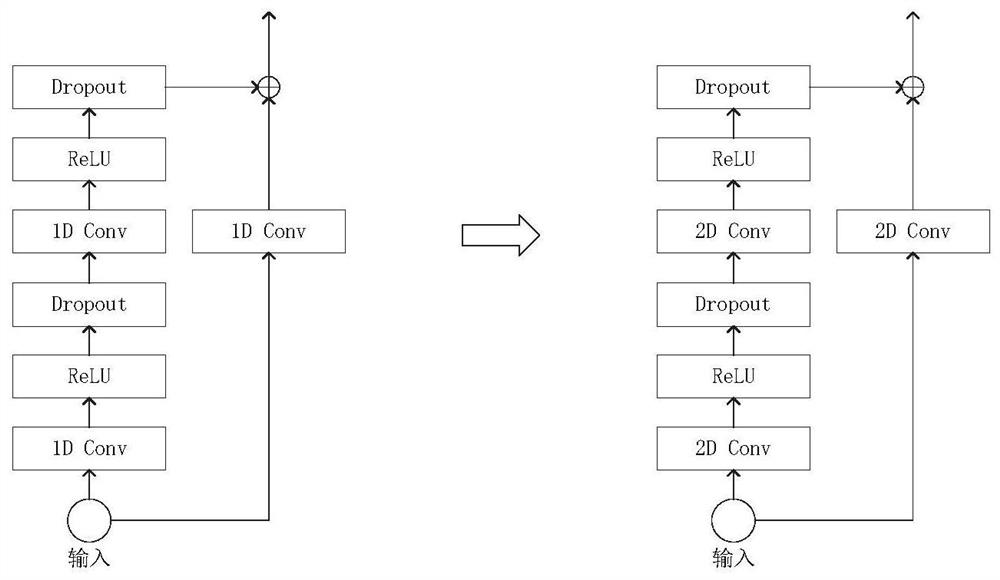
[0063] The multimodal speech separation model outputs a cIRM corr...
Embodiment 2
[0078] The purpose of this embodiment is to provide a computing device, including a memory, a processor, and a computer program stored in the memory and operable on the processor, and the processor implements the steps of the above method when executing the program.
Embodiment 3
[0080] The purpose of this embodiment is to provide a computer-readable storage medium.
[0081] A computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, the steps of the above-mentioned method are executed.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More