

A method and system for visual human-computer interaction based on text generation video robot
A technology of robot vision and video generation, which is applied in the field of human-computer visual interaction, can solve the problems of poor semantic consistency between text and images, poor convergence of generative confrontation network, and poor image quality, so as to reduce instability, improve visual interaction ability, Improve the effect of diversity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
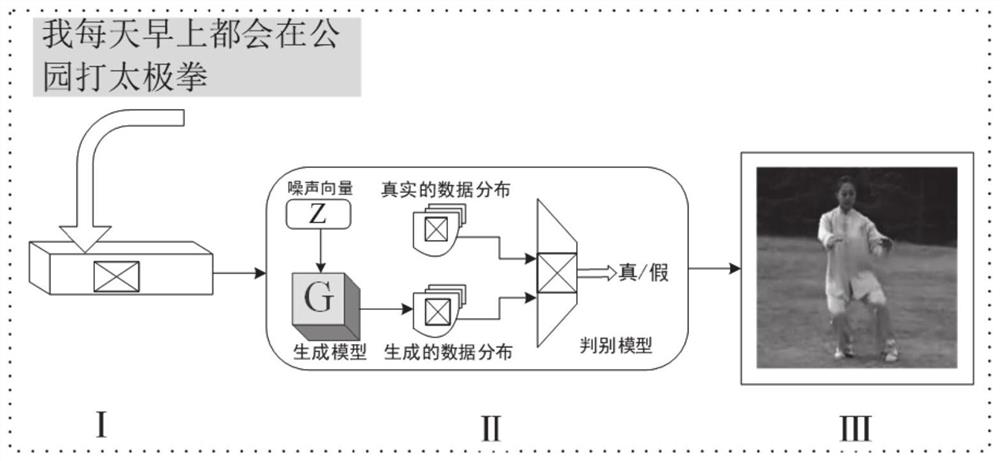
[0039] According to an embodiment of the present invention, a visual human-computer interaction method for a robot based on text generation video is disclosed, refer to figure 2 , including the following steps:
[0040] (1) Obtain the text information and source image to be recognized;
[0041] The text information to be recognized may be directly input text information, or may be text information converted from input voice information.
[0042] The source images can be old photos of people or photos collected on the spot, as a guide for model scene information generation.
[0043] (2) Retrieve the action database according to the text information, and select the action image sequence with the highest matching degree;
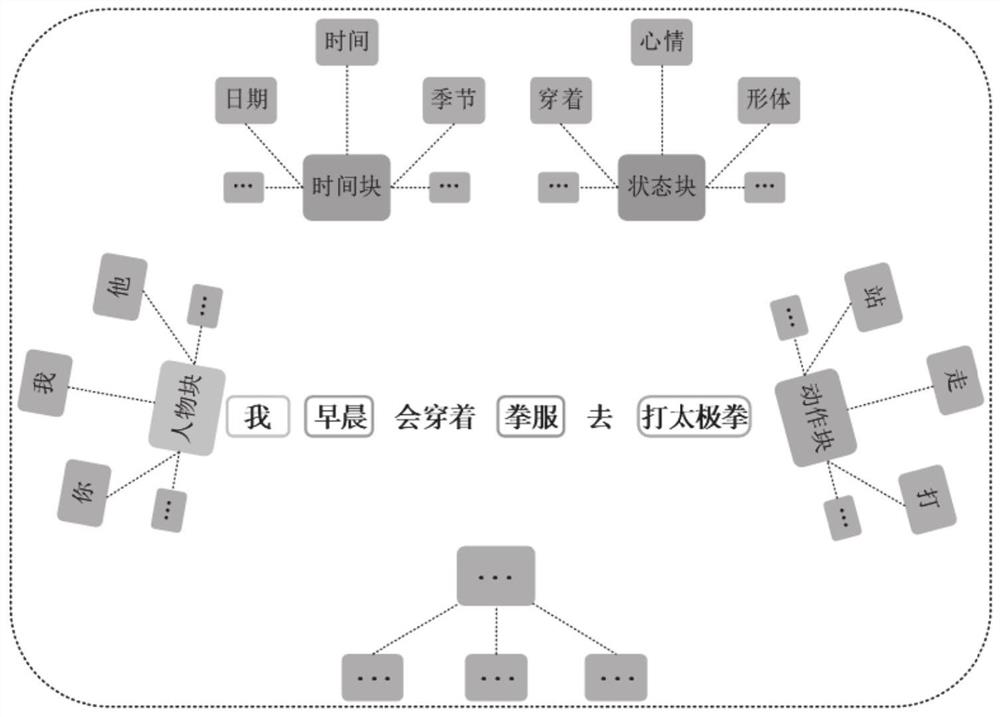
[0044] In traditional text-based image generation tasks, text information is processed through text embedding functions, and combined with specific source images in the form of tags. Label-based text information requires a lot of labor costs to label, conta...
Embodiment 2
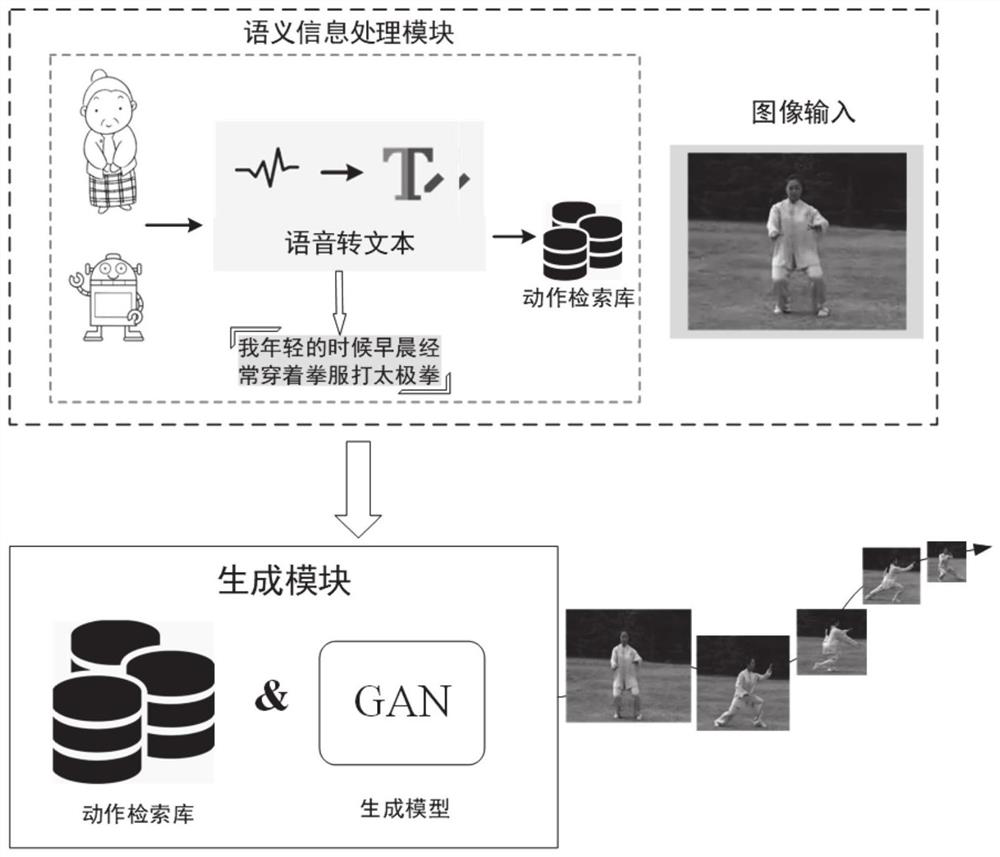
[0073] According to an embodiment of the present invention, an embodiment of a text-based video robot vision human-computer interaction system is disclosed, refer to figure 2 ,include:
[0074] The data acquisition module is used to acquire the text information and source image to be recognized;
[0075] The semantic information processing module is used to retrieve the action database according to the text information, and select the action image sequence with the highest matching degree;
[0076] The generation module is used to generate the model scene information based on the source image, combine the reference action image sequence obtained by matching, and generate the network model of the video task based on the text, and generate a video / image sequence that satisfies the semantic information and contains the source image scene information.
[0077]In this embodiment, the semantic information processing module mainly includes language information and image information...
Embodiment 3
[0080] According to an embodiment of the present invention, an embodiment of a terminal device is disclosed, which includes a processor and a memory, the processor is used for implementing each instruction; the memory is used for storing a plurality of instructions, the instructions are suitable for being loaded and executed by the processor The robot vision human-computer interaction method based on the text-generated video described in the first embodiment.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More