

Redis-based mass data classified storage method and system
A mass data and storage system technology, applied in the computer field, can solve problems such as increasing response timeout rate, increasing query time, and difficulty in meeting the continuous growth of user data volume, and achieve the effect of reducing memory fragmentation and memory occupation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
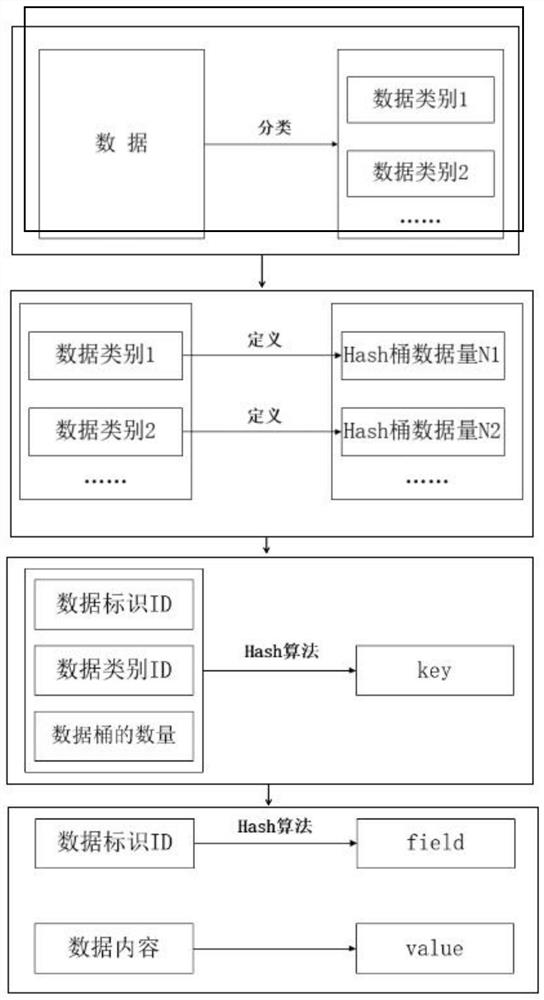
[0053]According to a kind of Redis-based mass data classification storage method provided by the present invention, comprising:
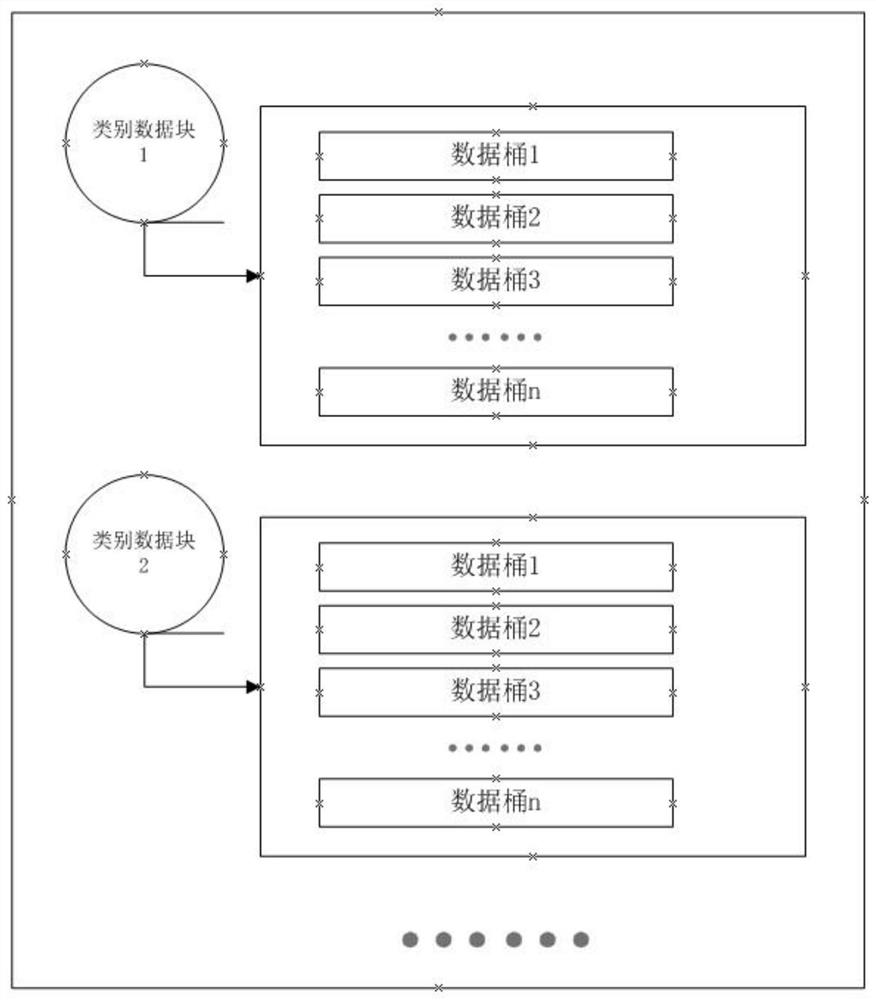
[0054] Step S1: classify the data, and define a data category ID for each category of data;
[0055] Step S2: For each data type, calculate the number N of hash buckets according to the data scale of the corresponding actual business; according to the characteristics of redis, the ziplist data structure storage method with the most space-saving hash type data requires hash buckets ( That is, the field data stored in a hash key) is less than 512. Therefore, the calculation formula for the number N of hash buckets is: N=total data volume / 512, and rounded up.
[0056] Step S3: Use the data identification ID, data category ID, and the number N of data buckets as input factors, perform hash calculation, and obtain hash key and field;
[0057] Step S4: use the data content corresponding to the data identification ID as the hash value;
[0058] Step S5: ...
Embodiment 2
[0090] Embodiment 2 is a preferred example of embodiment 1
[0091] The present invention classifies and stores massive data into redis after hash calculation and processing, so as to save memory, improve access speed, and enable classification and independent maintenance.
[0092] The present invention provides a method for classifying and storing massive data based on Redis, comprising:
[0093] Step 1: Define user data category ID by business category;
[0094] Step 2: Define the number N of user data buckets according to the data magnitude corresponding to the data category ID;
[0095] Step 3: Using the hash algorithm A to calculate an integer-type hash result A using the string-type user data identifier, the data category ID, and the number N of the data buckets as factors;
[0096] Step 4: using the integer type hash result A as the hash key of the hash data type of redis;
[0097] Step 5: Using the user data identifier of the string type as the unique factor again, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More