

Streaming end-to-end speech recognition method and device, and electronic equipment
A speech recognition and streaming technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem of low activation point positioning accuracy, and achieve the effect of high accuracy, low mismatch and improved accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
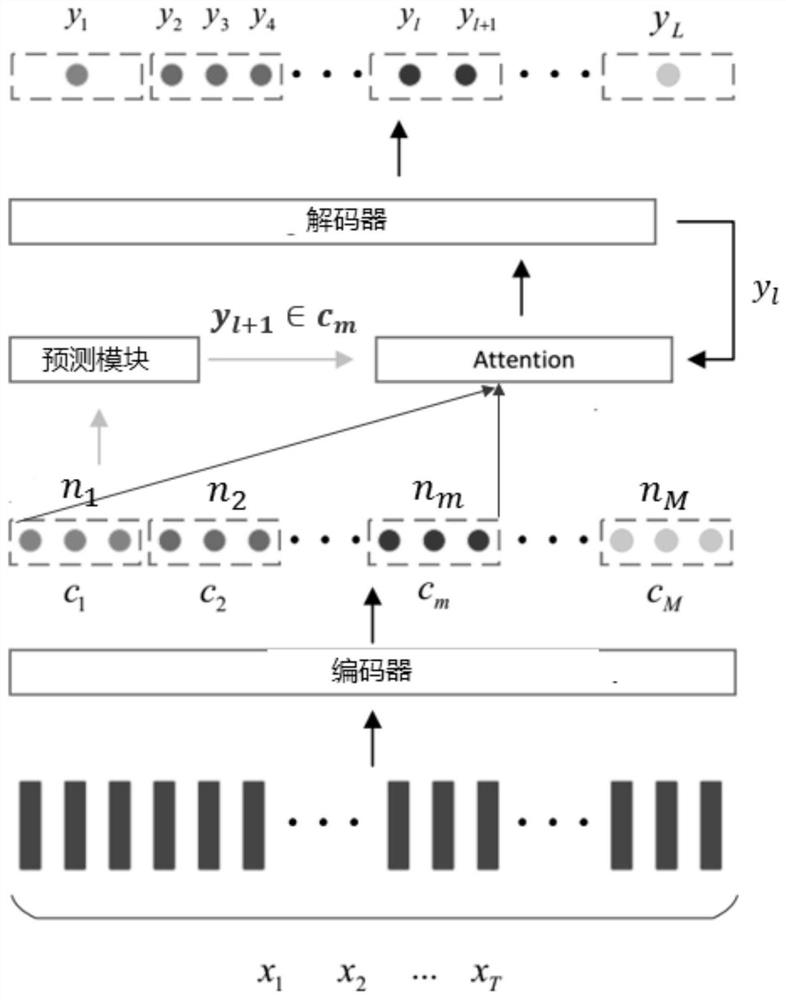
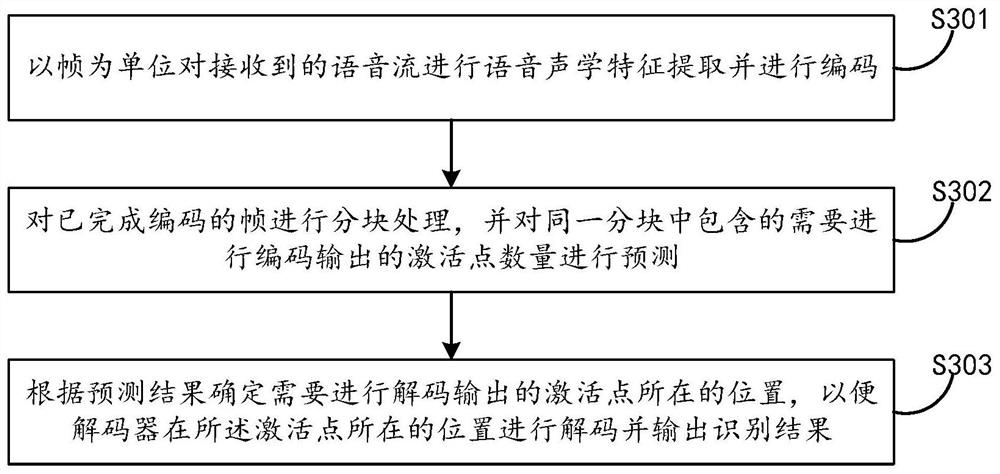
[0083] First, the first embodiment provides a flow-end speech recognition method, see image 3 ,include:
[0084] S301: a frame unit received voice stream and extracting acoustic features for speech encoding;
[0085] Performing the streaming voice recognition process, it is possible in voice frame units speech acoustic feature extraction stream, and in units of frames is encoded, the encoder outputs the encoded result of each frame. Further, since the input voice stream is continuous, therefore, the voice stream is encoded in operation may be continued. For example, suppose that is a 60ms frame, as received voice stream, every 60ms speech stream as a process for feature extraction and encoding. Wherein, the coding process is received speech acoustic feature was converted to a new higher level of expression of having to distinguish between the high-level expression may generally be present in the form of a vector. Thus, the encoder may specifically be a multilayer neural network, s...
Embodiment 2
[0107] This second embodiment provides a method for the prediction model, see Figure 4 The method may specifically include:
[0108] S401: obtaining the training sample set, said training set comprising a plurality of block data and the label information, wherein each block frame comprises multiple data streams encoded frame of speech encoding results respectively, each of said label information comprises sub-blocks need to be included in the number of active points of decoded output;
[0109] S402: the training set is input to the trained predictive model in the model.
[0110] In specific implementation, the training set may comprise the same multi-frame modeling unit corresponding to the voice stream is divided into different sub-blocks in the case, which can be the same text like modeling unit is divided into a plurality of different block access to accurate forecast when the situation was the result of training, which encountered the same situation during the test.
Embodiment 3
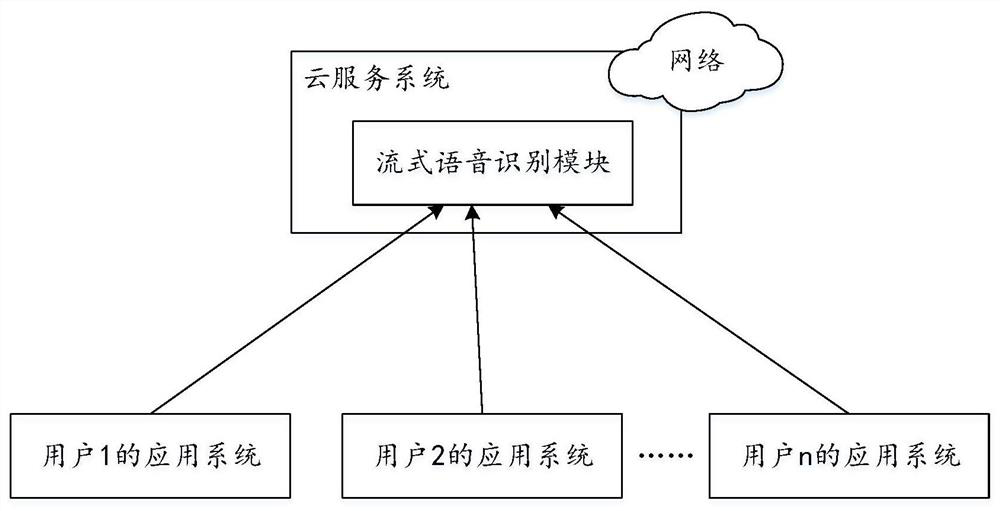
[0112] The third embodiment is directed to the scenario in the cloud service system provided in the cloud service system, and provides a method of providing a speech recognition service from the angle of the cloud server, and See Figure 5 This method can include:
[0113] S501: After the cloud service system receives the call request of the application system, the voice stream provided by the application system is received;
[0114] S502: Extract the voice sound of the received voice in units of frames and encoded;
[0115] S503: Multiple block processing of completed coded frames and predicts the number of activation points that encode output in the same block need;
[0116] S504: Determine the location where the active point of the decoded output is determined according to the forecast results, so that the decoder decodes the position of the speech to obtain the speech recognition result;
[0117] S505: Returns the speech recognition result to the application system.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More