

Pre-stack seismic data random noise suppression method and system
A random noise, pre-stack seismic technology, applied in the field of geophysical exploration technology and deep learning, can solve the problems of unseen research literature, model training takes a long time, manual intervention, etc., to improve training efficiency and avoid training data volume And the high requirements of the neural network scale, to achieve the effect of effective suppression
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
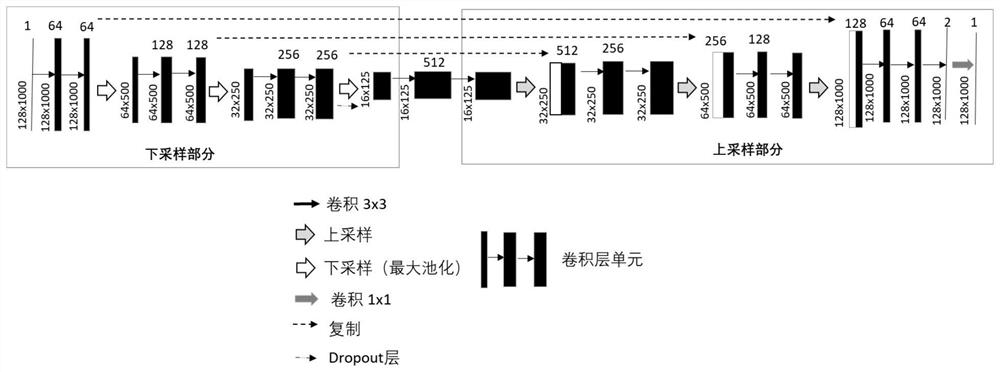
[0062] Such as Figure 11 As shown, the random noise suppression method of pre-stack seismic data based on U-NET network includes the following steps:
[0063] (1) Prepare data sets using actual seismic data and forward modeling data of pre-stack shots: A key step in deep learning processing is the production of label data sets. In order to ensure the generalization ability of the training network, intelligent noise suppression technology Quality label data source can be composed of two parts: 1. Data analysis and extraction of high-quality denoised seismic data in typical exploration areas: actual data label is an important part of improving the generalization ability of deep network, so data selection should cover a variety of practical Typical detection areas, and select data with high-quality denoising effects to improve the robustness of the data set; 2. Pre-stack shot set forward modeling simulation data: the actual data denoising effect is largely affected by the denois...
Embodiment 2
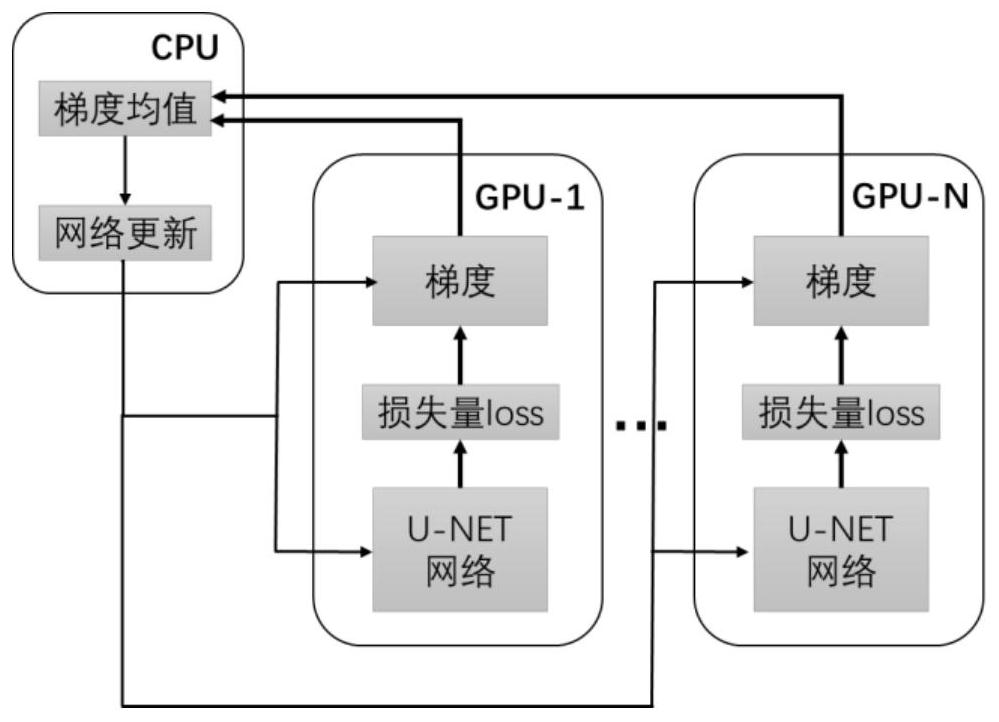
[0071] Such as Figure 12 As shown, the system includes:
[0072] A data set preparation unit 10 is used to prepare a data set using actual seismic data and pre-stack shot set forward modeling data, and divide the data set into a training data set and a verification data set;
[0073] The network design training unit 20 is connected with the data set preparation unit 10 for designing the network, and utilizes the GPU and the training data set to carry out parallel training on the network to obtain the trained network;
[0074] The verification unit 30 is connected with the network design training unit 20, and is used to verify the trained network by using the verification data set to obtain the verified intelligent random noise suppression network;
[0075] The noise suppression unit 40 is connected with the verification unit 30, and is used to collect pre-stack seismic data, and input the pre-stack seismic data into the verified intelligent random noise suppression network t...
Embodiment 3
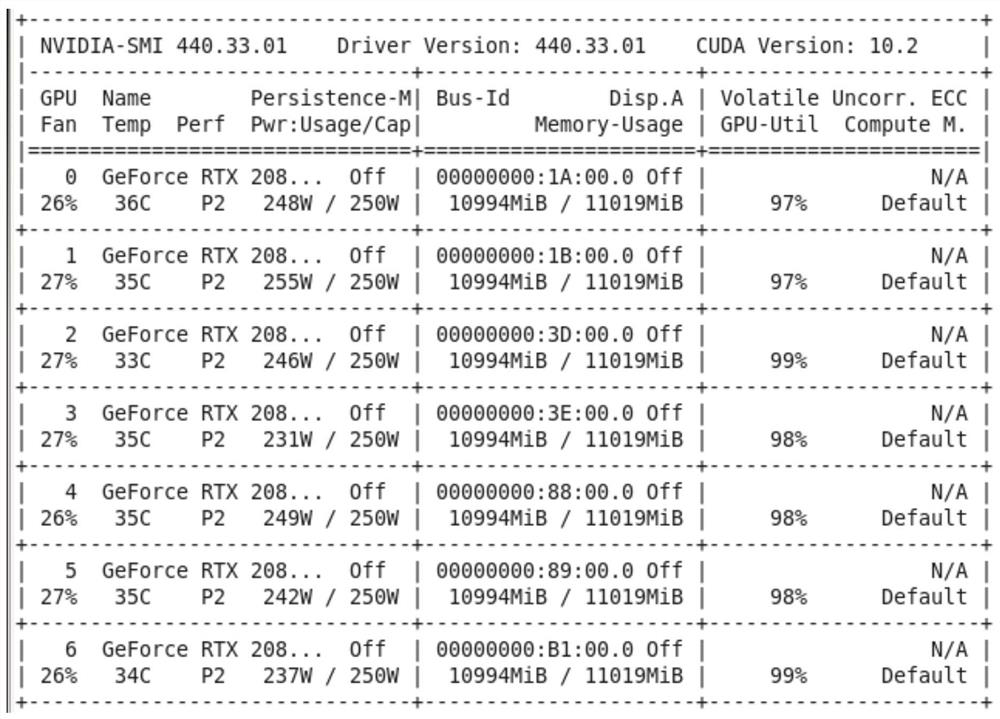
[0078] The training input data size is 128x1000, among which, a data set containing 100,000 single-shot results was prepared. Establish the above-mentioned U-NET network, and set the learning rate to 0.001. During the training process, in order to further improve the generalization ability of the network, 5% Gaussian noise is further added for data enhancement. In addition, the batch_size is set to 20, and the number of learning rounds is set to Set at 15 rounds. In addition, the cluster GPU used in this test is RTX 2080Ti with a memory size of 11G, and the number of GPU cards used for training is seven cards. The running status of the GPU cards during the model training process is as follows: image 3 As shown, it can be seen from the figure that all 7 GPU cards have a high utilization rate, which effectively improves the efficiency of network training.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More