

Expert System And Data Analysis Tool Utilizing Data As A Concept
a data analysis and expert system technology, applied in the field of data, can solve problems such as not always having domain expertise, and achieve the effects of improving data discovery, aggregating and analysing data, and high quality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
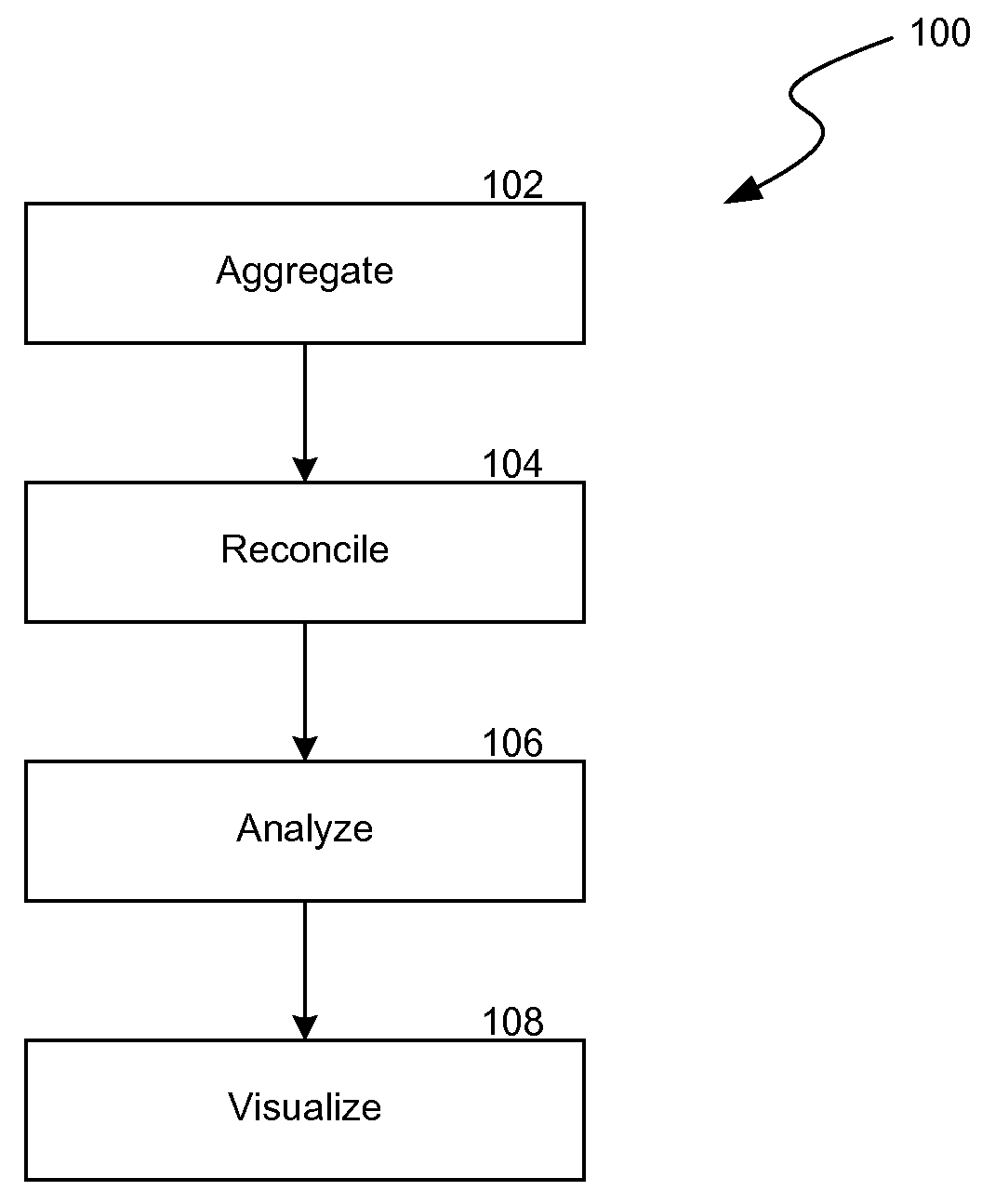
[0056]Various embodiments of the present invention are directed to methods and systems for learning concepts and relationships associated with different data to simplify the analysis of the data, tracking and storing the analysis techniques used to manipulate the data, and visualizing and filtering the analyzed data. In particular, the Datavore tool, described herein, may be able to learn concepts and relationships associated with different data types to simplify the analysis of the data and to allow data analysis experts to more efficiently work with the data. The tool may be able to combine the learned concepts and relationships with user defined concepts and relationships associated with the different data types. The tool may be able to track and the data analysis experts' data analysis techniques (work data flows). The tool may also allow for the visualization and filtering of the analyzed data. Although multiple references are made herein to a user (e.g., data analysis expert) ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More