

Speech synthesis system based on mixed hidden Markov model
A hidden Markov, speech synthesis technology, applied in speech synthesis, speech analysis, instruments, etc., can solve problems such as time domain over-flatness and inability to describe
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0037] The present invention will be further described below with reference to the accompanying drawings and examples, and the steps and processes for realizing the present invention will be better described through the detailed description of each component of the system with reference to the accompanying drawings. It should be noted that the described examples are to be considered for illustrative purposes only and are not intended to limit the invention.
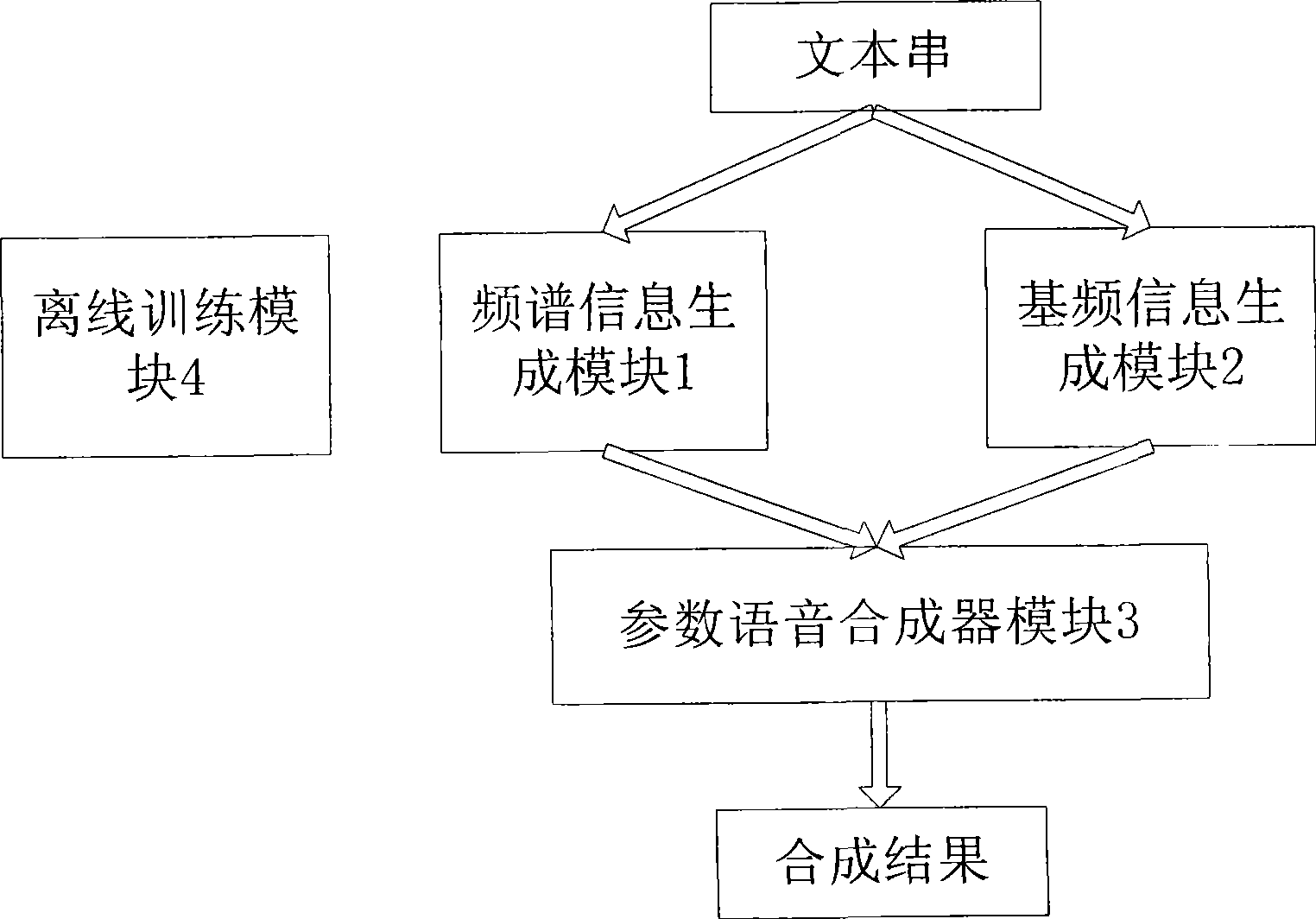
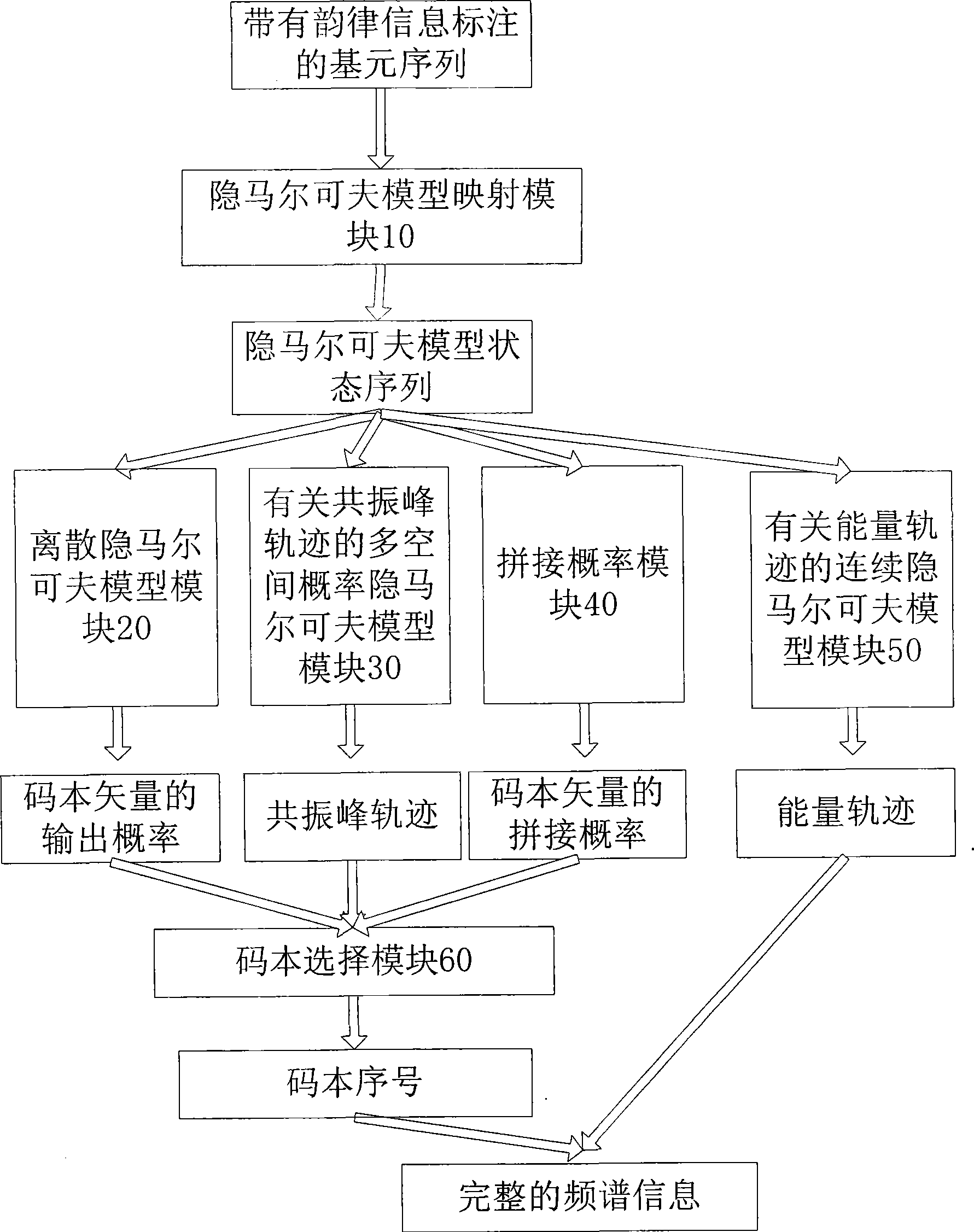
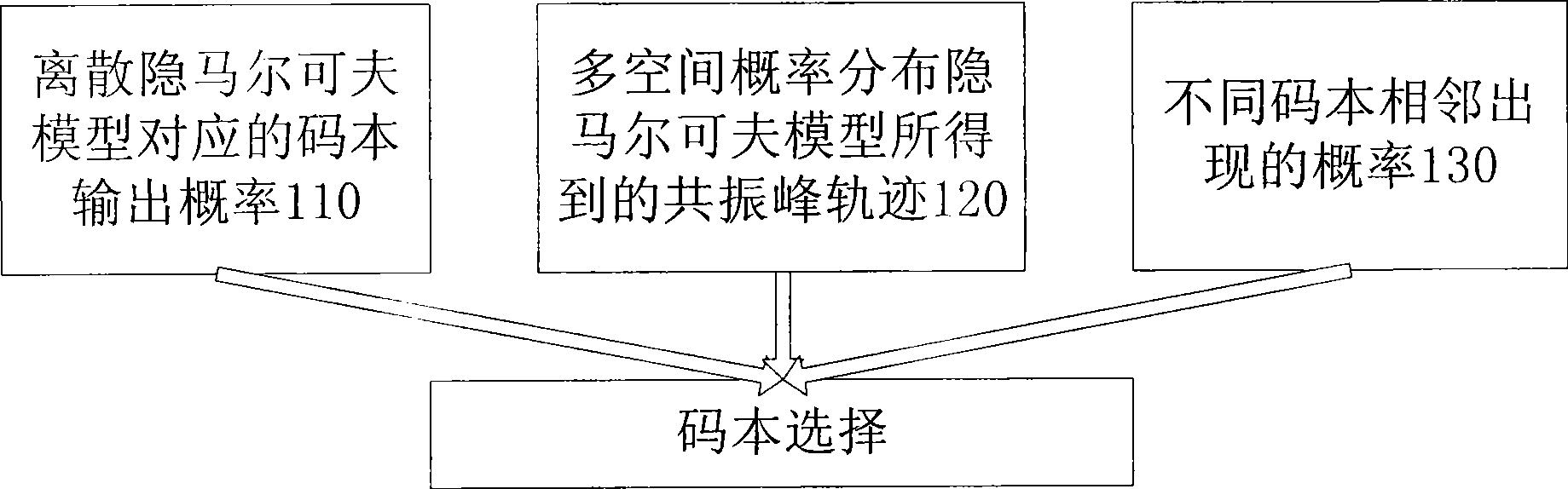
[0038] figure 1 It is a schematic diagram of the speech synthesis system based on the hybrid hidden Markov model of the present invention. The system is written in C language, and can be compiled and run using visual studio under the windows platform, and can be compiled and run under the linux platform using gcc. in the attached figure 1 In a preferred embodiment of the present invention, the system is divided into four parts: a spectrum information generation module 1, a fundamental frequency information generation mod...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More