An on-demand clustering big data streaming clustering processing system and method
A data streaming and processing system technology, applied in the field of data processing, can solve problems such as not being able to effectively improve resource utilization efficiency, and achieve the effects of fast processing, enhanced scalability and sensitivity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 Embodiment approach
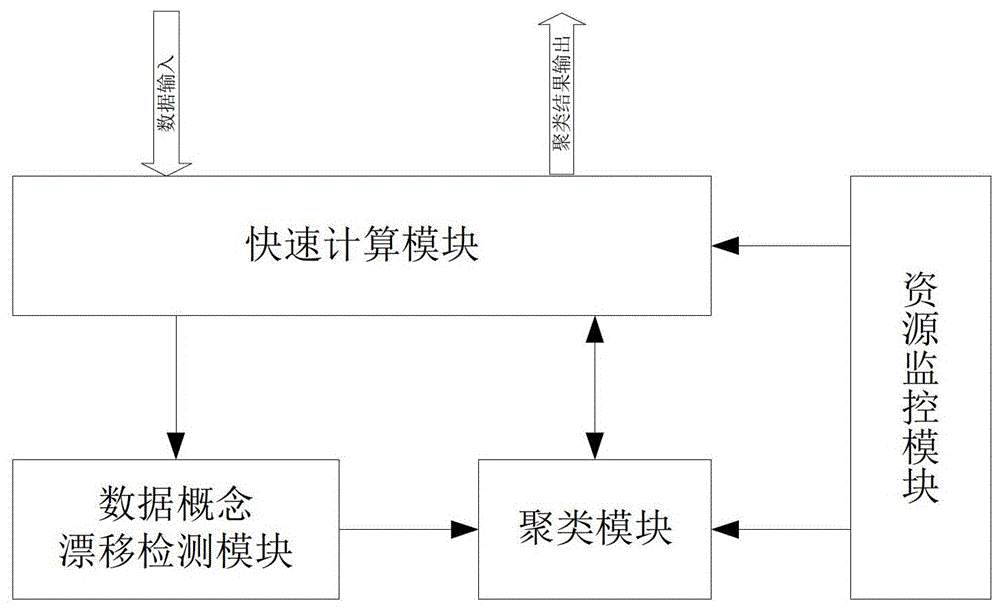
[0031] refer to figure 1 , the first embodiment of the present invention, a big data streaming cluster processing system for on-demand clustering, the system includes a fast calculation module, a data concept drift detection module and a clustering module, the fast calculation module The output terminal is connected to the first input terminal of the clustering module through the data concept drift detection module, and the clustering module is connected to the fast calculation module.
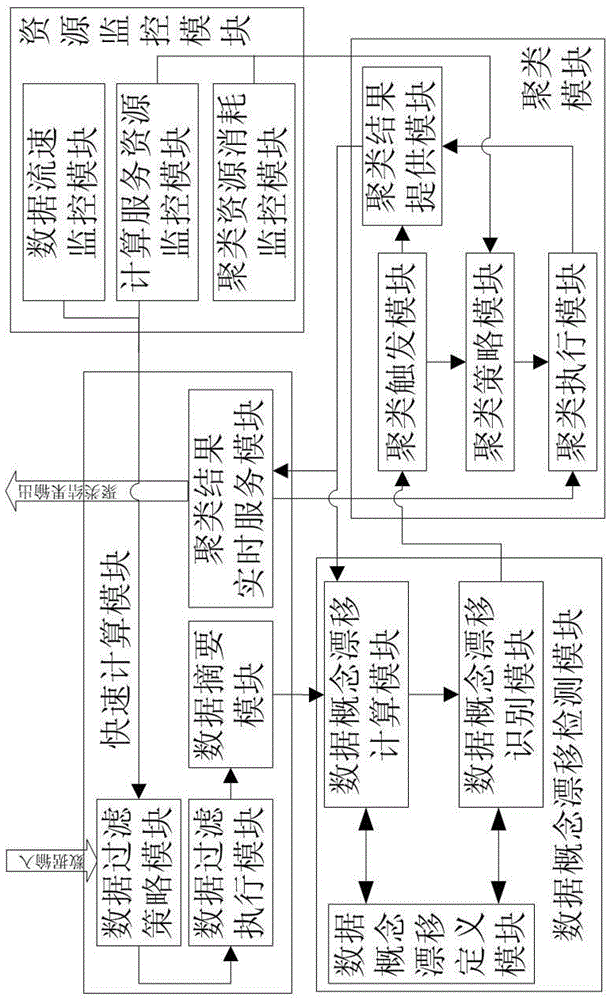
[0032] The fast calculation module is used to receive data input and provide output of clustering results. This module is responsible for fast and simple processing of data streams, and obtains fast calculation intermediate processing results for subsequent processing of other modules. Among them, there are two main solutions for fast processing: data stream data filtering and data feature extraction. The former is calculated by reducing the amount of data in the data stream, such as data fil...
no. 2 Embodiment
[0046] The second specific embodiment of the present invention is an on-demand clustering big data stream clustering processing method, the clustering processing method includes the following steps:
[0047] A. Perform filtering operations and data feature extraction on the input data stream data to obtain intermediate processing results;
[0048] The method performs corresponding data filtering operations according to the data filtering strategy, and calculates the amount of data in the process data flow through data filtering, data sampling, and unloading. Data feature extraction is the work of extracting abstracts according to data. The data in the data stream is complex, and the size of each data point may be large. In order to obtain better clustering results, it is necessary to extract the most important points from these data. Abstract information, by reducing the storage capacity of a single data, by extracting the characteristics of the data so that the subsequent pro...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More