

Hadoop-based mass log data processing method
A data processing and log technology, which is applied in the direction of electronic digital data processing, special data processing applications, structured data retrieval, etc., can solve problems such as inability to log to support cross-node query, incapable infrastructure, and inability to solve problems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
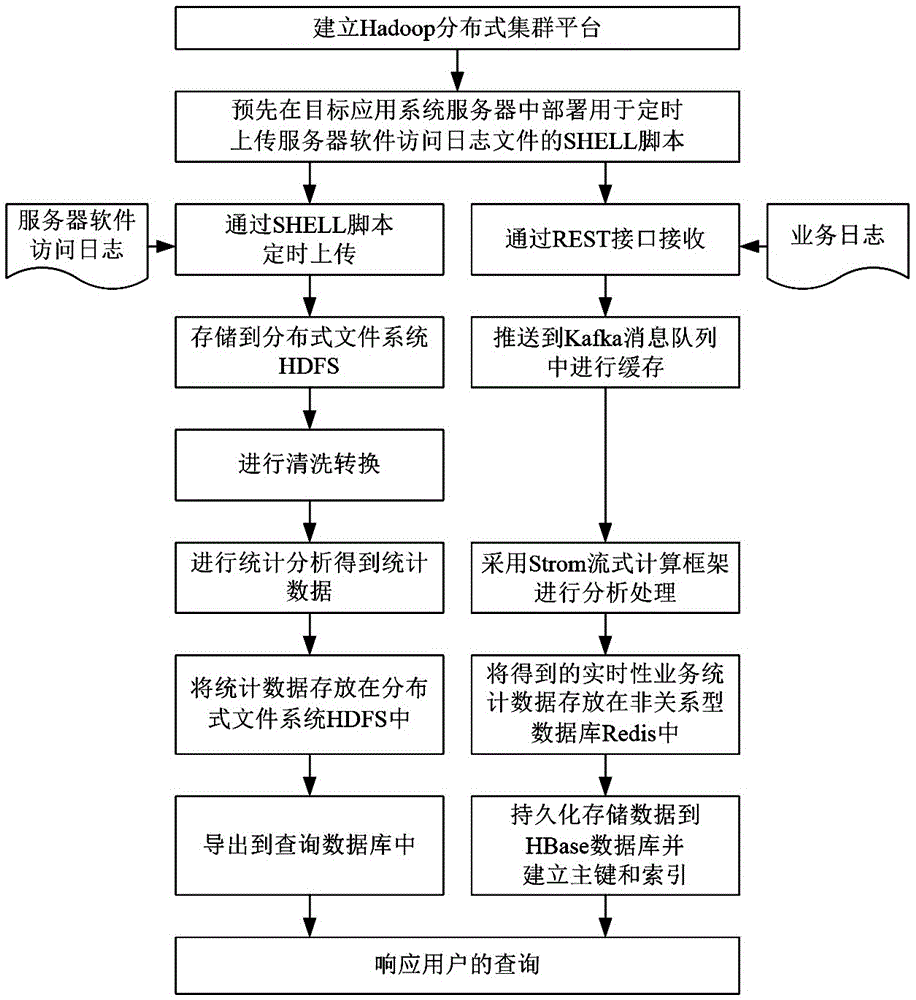
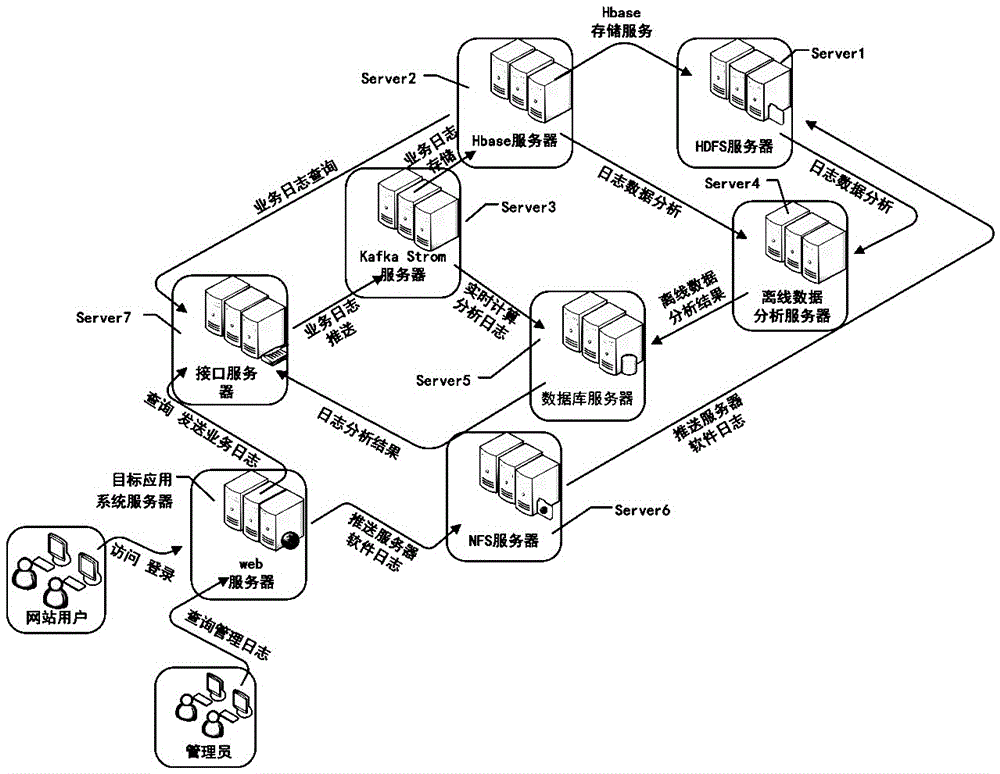
[0018] Such as figure 1 As shown, the implementation steps of the Hadoop-based massive log data processing method in this embodiment include:
[0019] 1) Establish Hadoop distributed cluster platform, Hadoop distributed cluster platform is installed with distributed file system HDFS, non-relational database Redis, Mysql database, HBase distributed database, Kafka distributed message cache system, REST interface and Strom streaming computing Framework; connect the target application system server to be processed with massive logs to the Hadoop distributed cluster platform, and pre-deploy the SHELL script for regularly uploading server software access log files in the target application system server;
[0020] 2) For the server software access log and business log in the target application system server, upload and push the server software access log files to the Hadoop distributed cluster platform regularly through the SHELL script, and the Hadoop distributed cluster platform w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More