

Method for intelligent automatic identification of transmission circuit parts
A transmission line and automatic identification technology, which is applied in scene recognition, computer parts, character and pattern recognition, etc., can solve the problem of large differences in the proportion of auxiliary components of transmission lines, without taking into account the accuracy of image space information and transmission line component recognition The efficiency needs to be improved and improved to achieve the effect of improving operation efficiency, improving the level of intelligence, and reducing labor intensity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
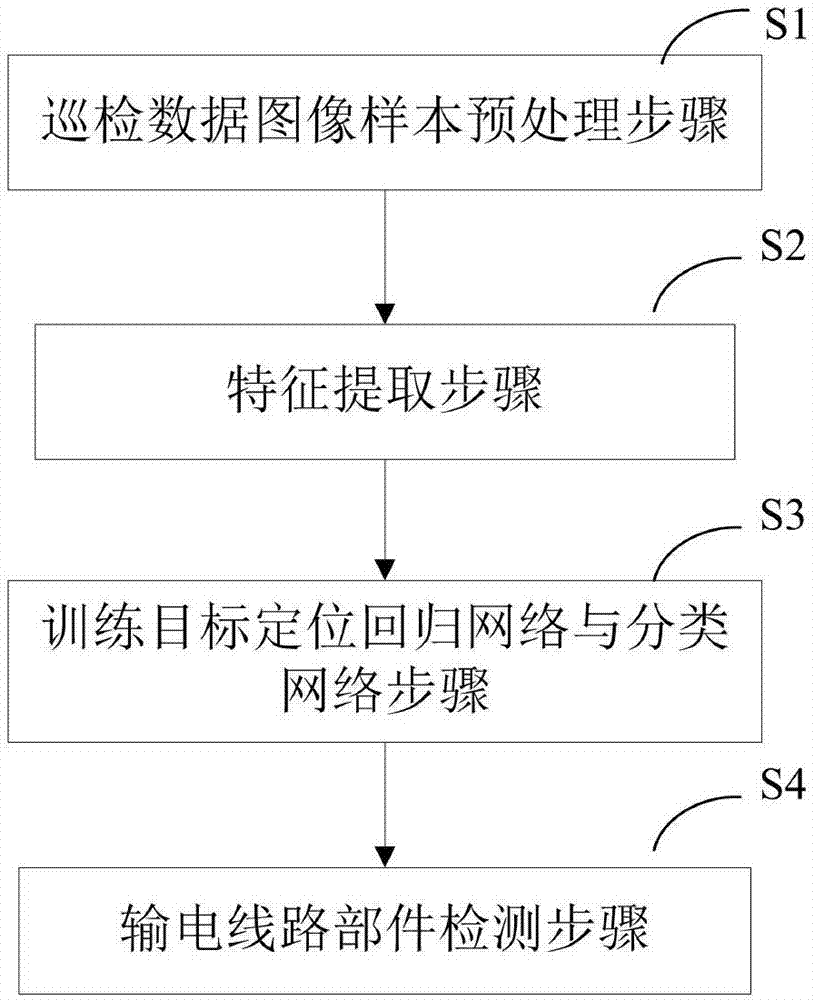
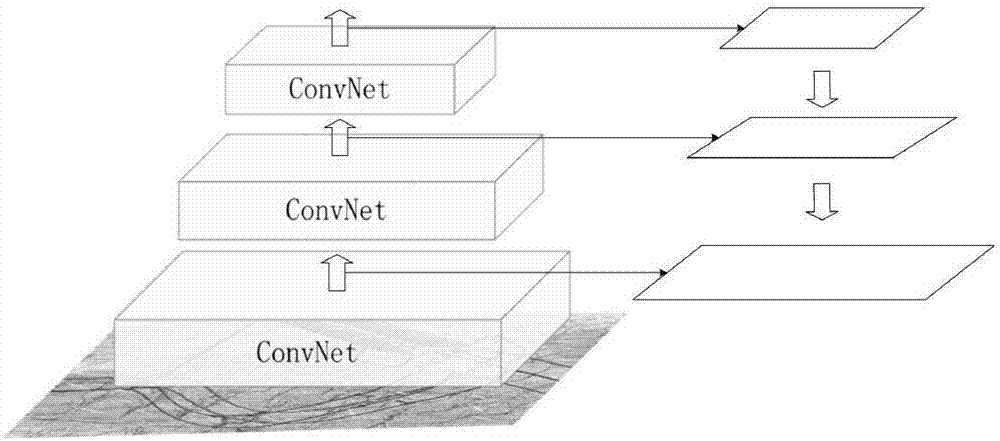
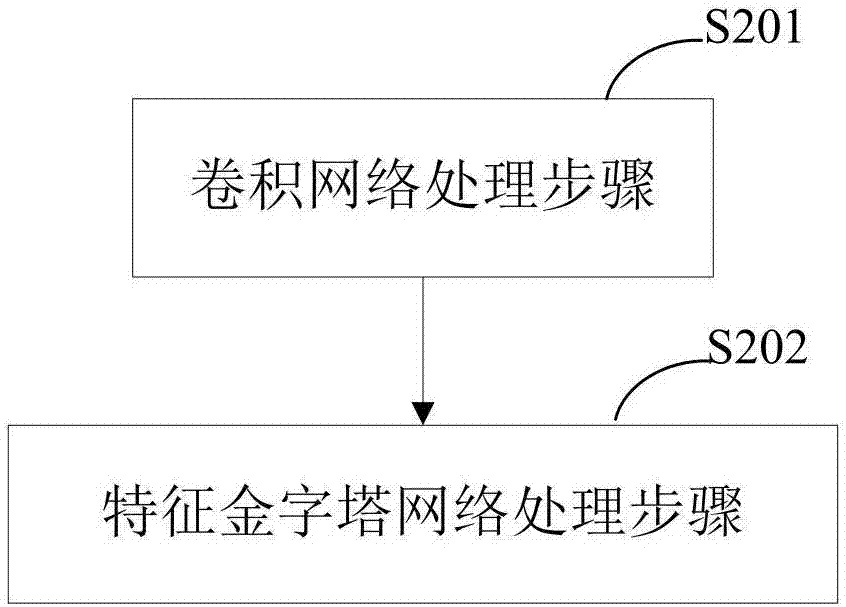
[0044]In order to clearly illustrate the technical features of the present solution, the present invention will be described in detail below through specific implementation methods and in conjunction with the accompanying drawings. To simplify the disclosure of the present invention, components and arrangements of specific examples are described below. Furthermore, the present invention may repeat reference numerals and / or letters in different instances. This repetition is for the purpose of simplicity and clarity and does not in itself indicate a relationship between the various embodiments and / or arrangements discussed. It should be noted that components illustrated in the figures are not necessarily drawn to scale. Descriptions of well-known components and processing techniques and processes are omitted herein to avoid unnecessarily limiting the present invention.
[0045] Such as figure 1 As shown, a method for intelligent automatic identification of transmission line c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More