

A near similarity fast searching method based on local sensitive hash
A local-sensitive hashing and fast technology, applied in the field of computer algorithms, it can solve the problems of increased time overhead, empty result set, and increased minimum similarity, and achieve the effect of increasing space and meeting business requirements.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0032] The present invention will be further described below in conjunction with the accompanying drawings.
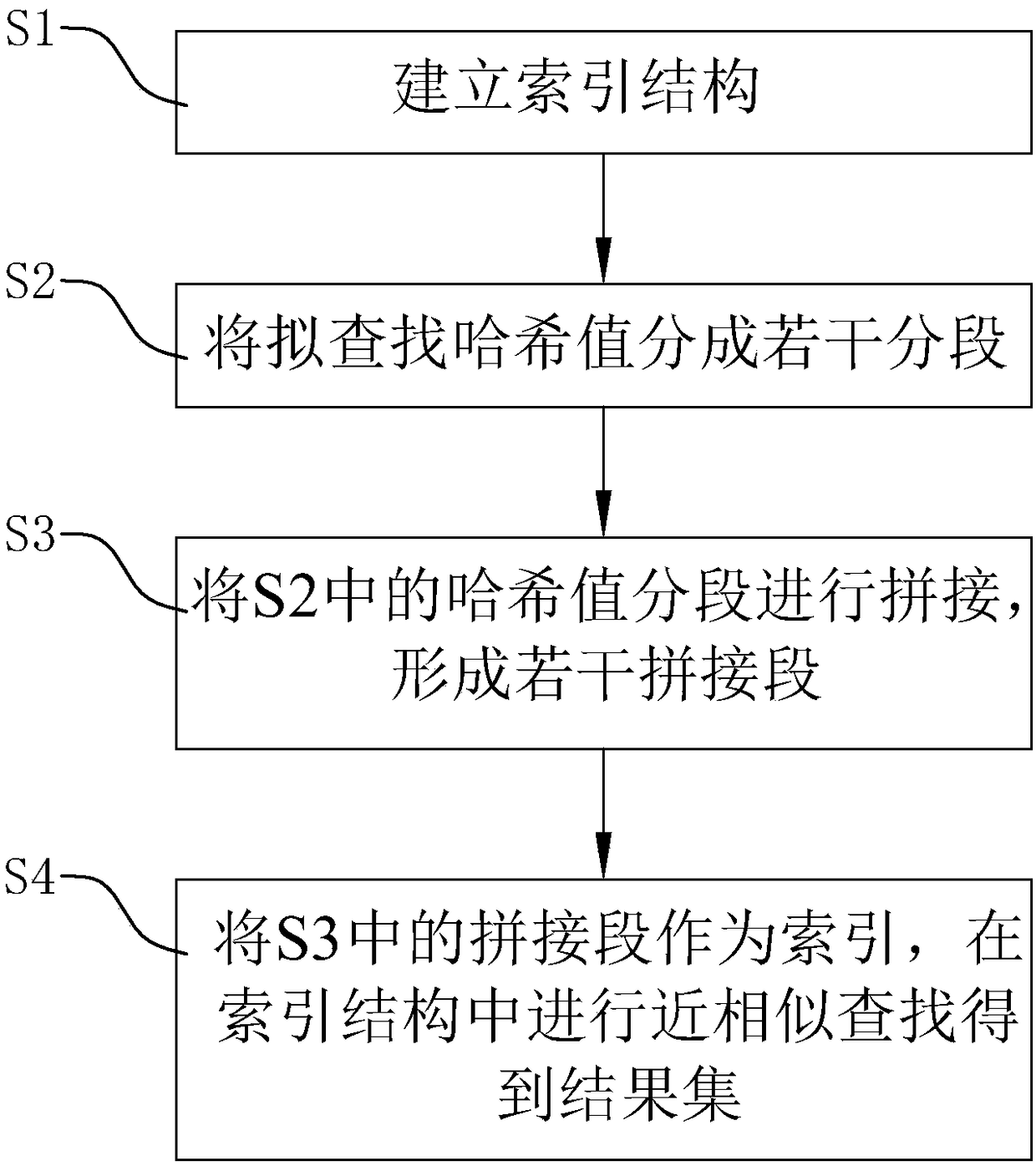
[0033] Such as Figures 1 to 3 The shown near-similar fast search method based on local sensitive hashing includes the following steps:
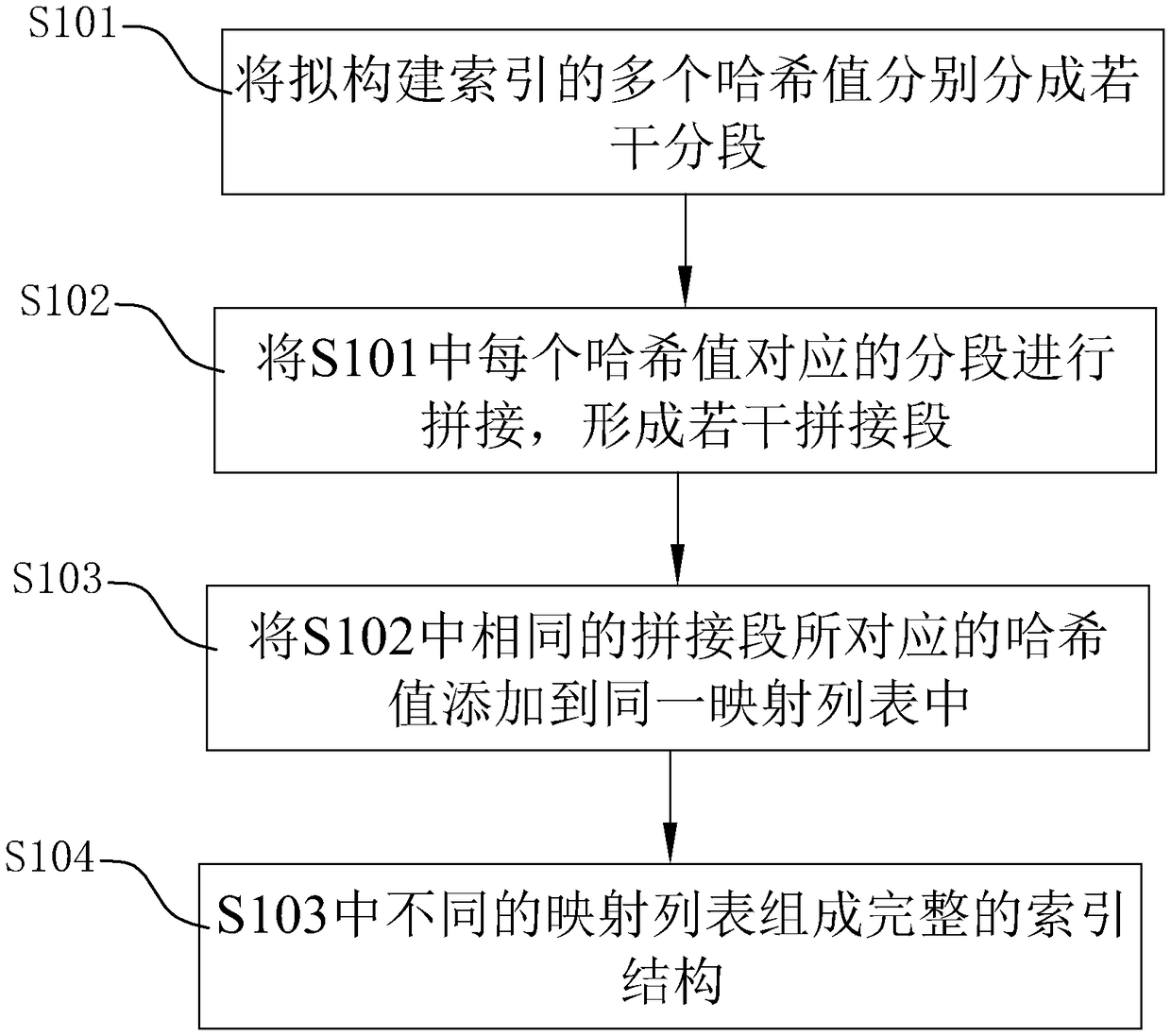
[0034] S1. Establishing an index structure: All the multiple hash values that need to establish an index structure are segmented, and each hash value is divided into multiple segments. Partial segments are taken out from multiple segments of a hash value and spliced to form several spliced segments. The splicing segment is mapped, and the hash values corresponding to the splicing segment with the same mapping are added to the same mapping list, and the index structure is composed of different mapping lists.
[0035] S2. Segment the hash value to be searched by the same segmentation method as the hash value in S1 above, and divide it into several segments.
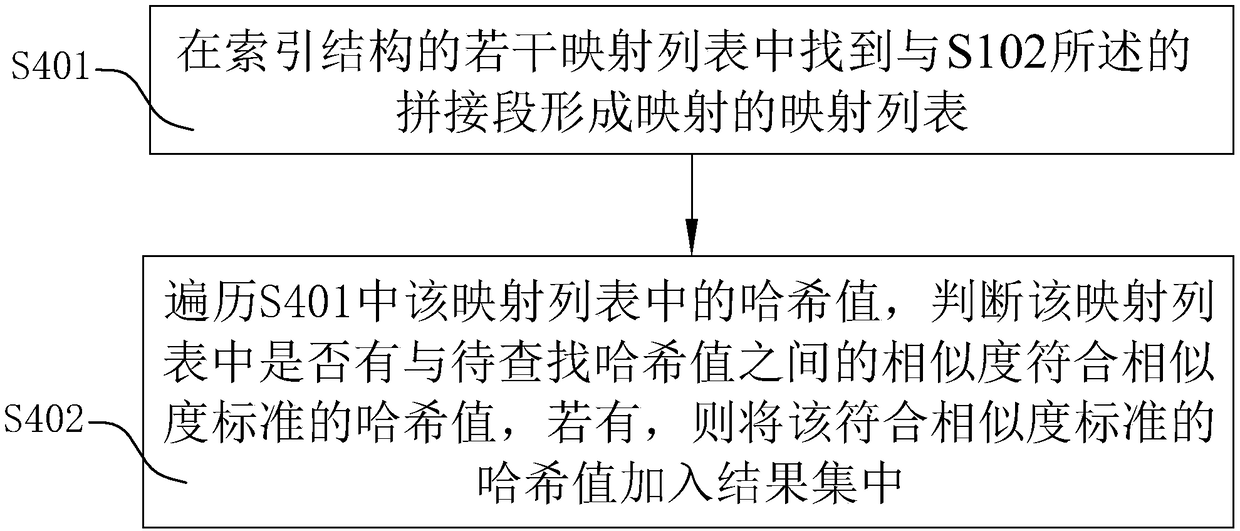
[0036] S3. Splicing the segments in step S2 to form several splici...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More