

A distributed big data computing engine and an architecture method
A computing engine and distributed technology, which is applied in computing, digital data processing, program control design, etc., can solve the problems of fixed time granularity of built-in aggregation, inability to support larger granularity aggregation, and poor throughput, etc., to achieve development and deployment as well as Low maintenance cost, less component dependencies, and good real-time effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
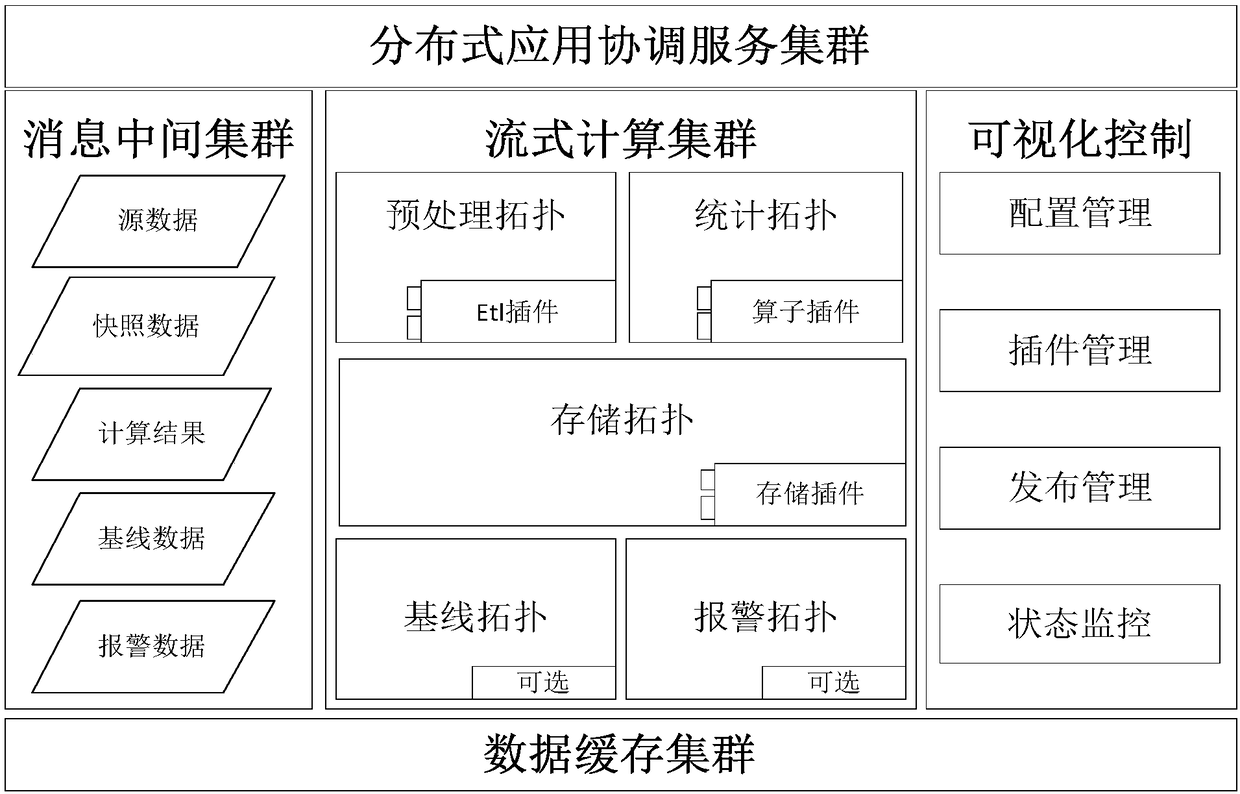
[0044] Such as figure 1 As shown, the distributed data engine framework is mainly composed of five parts: distributed coordination service cluster (ZooKeeper), message middleware cluster (Kafka), streaming computing cluster (Storm), data cache cluster (Redis), and visual control. ZooKeeper, Kafka, Storm, Redis, etc. are currently popular open source components. in,
[0045] Distributed coordination service cluster: ZooKeeper is a distributed application coordination service that provides efficient and reliable distributed coordination services for distributed applications, and provides distributed basic services such as configuration services, distributed synchronization, and node monitoring. In the distributed data engine, in addition to maintaining the state of the Kafka cluster and Storm cluster, we also use it to save related plug-ins and business schema.xml configuration files. Realized that the plug-in and schema.xml can take effect dynamically without restarting the t...
Embodiment 2
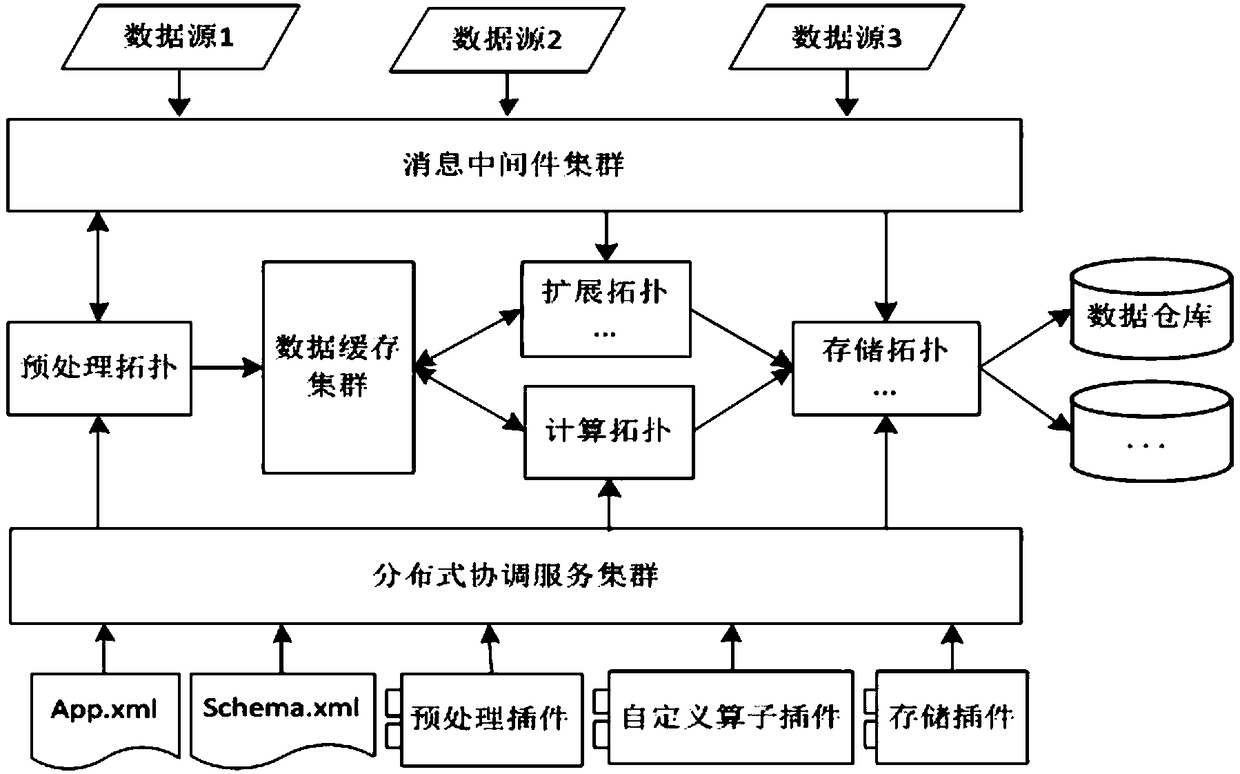
[0061] Such as figure 2 As shown, the implementation of the architecture includes the following steps:
[0062] (1) Clarify the source data format. Since the architecture itself has no restrictions on the format of the source data, the data sent to this architecture needs to be packaged in a unified format and marked with a data timestamp.
[0063] (2) Configure the Schema.xml file of the specific processing rules of each business data in the data source, and the operation and processing rules of all data indicators and dimensions are described by this file.
[0064] (3) Develop the data preprocessing plug-in by implementing the provided data preprocessing plug-in interface class, which runs in the data preprocessing topology and is responsible for implementing a specific cleaning strategy for each piece of raw data. When developing this plug-in, it is necessary to perform a cleaning strategy on each raw data received according to the configuration items in Schma.xml, and th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More