A container-based parallel deep learning scheduling training method and system
A deep learning and training method technology, applied in the field of cloud computing and deep learning, can solve the problems of large amount of upper development, mutual influence, lack of scheduling ability, etc., to improve the utilization rate of computing resources, improve resource utilization rate, and accelerate iteration speed effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0053] The container-based parallel deep learning scheduling training method of the present invention utilizes Kubernetes containers to realize the configuration and scheduling of computing resources for tasks, provides multiple resource management mechanisms such as ResourceQuota and LimitRanger, and uses pod nodes in a container cluster through communication between pod nodes. Communication to achieve resource isolation between tasks; the same training node starts training pods and lifecycle management pods at the same time, and LCM performs unified resource job scheduling. The microservice architecture itself is deployed as a POD, relying on the latest version of Kubernetes to effectively mobilize GPUs Use, when the K8S job crashes due to any failure cause in OS, docker or machine failure, restart the microservice architecture and report the health of the microservice architecture; training jobs are scheduled in FIFO order by default, LCM supports job priority, For each trai...
Embodiment 2
[0057] In the container-based parallel deep learning scheduling training method of the present invention, the specific steps of the method are as follows:
[0058] S1. Pre-install Kubernetes containers (above 1.3) on the host, designate one pod as the scheduling node, one pod as the monitoring node, and n pods as the task node;
[0059] S2. The scheduling node is responsible for submitting job tasks, and a task node is designated for a round of iteration through the scheduling algorithm; the scheduling algorithm is as follows:
[0060] (1) When the threshold is exceeded, the newly allocated computing node will transfer the computing task, and a spare task node (Pod) will appear at this time;
[0061] (2) Based on the size of the resources (GPU) occupied by the spare task nodes, set the weight (weight),
[0062] (3) The larger the resource occupied, the greater the weight;
[0063] (4) When a new node is required to be allocated over the threshold again, it will be selected f...
Embodiment 3
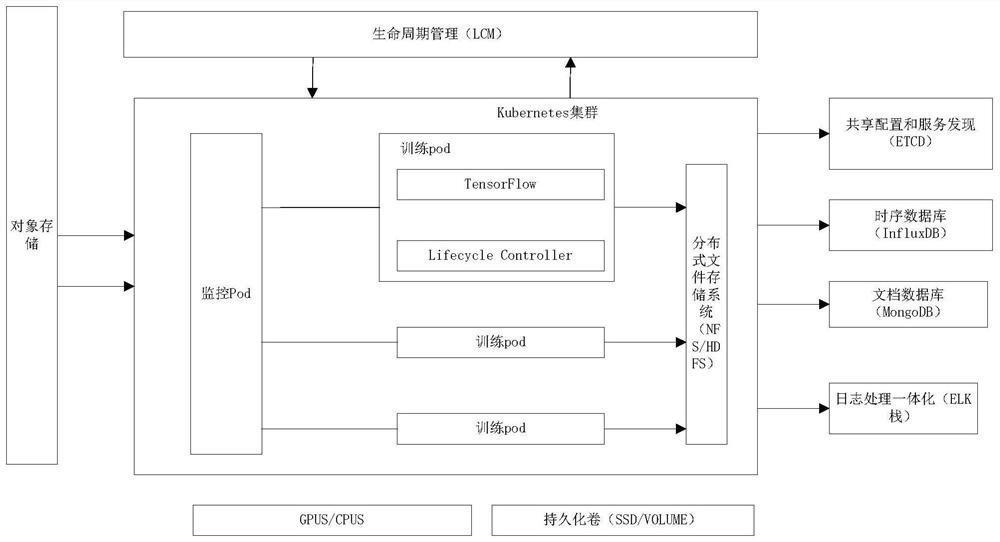
[0077] as attached figure 1 As shown, the container-based parallel deep learning scheduling training system of the present invention includes a micro-service architecture, learning and training (DL), container cluster management and life cycle management (LCM);
[0078] Among them, the microservice architecture is used to reduce the coupling between components, keep each component as single and as stateless as possible, isolate each other, and allow each component to independently develop, test, deploy, scale and upgrade; and through dynamic registration RESTAPI service instances to achieve load balancing;
[0079] Learning and training (DL) consists of a single learning node (Learning Pod) in a kubernetes container that uses GPUs, and user code instantiates the framework kubernetes service; usually, learning and training jobs use several GPUs / CPUs or are synchronized by several learning nodes. A centralized parameter service is used on MPI; users submit training tasks and ma...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com