A cloud storage system based on electric power data
A cloud storage system, power data technology, applied in transmission systems, electrical components, etc., to ensure data consistency, reduce management difficulty, and ensure stable operation.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
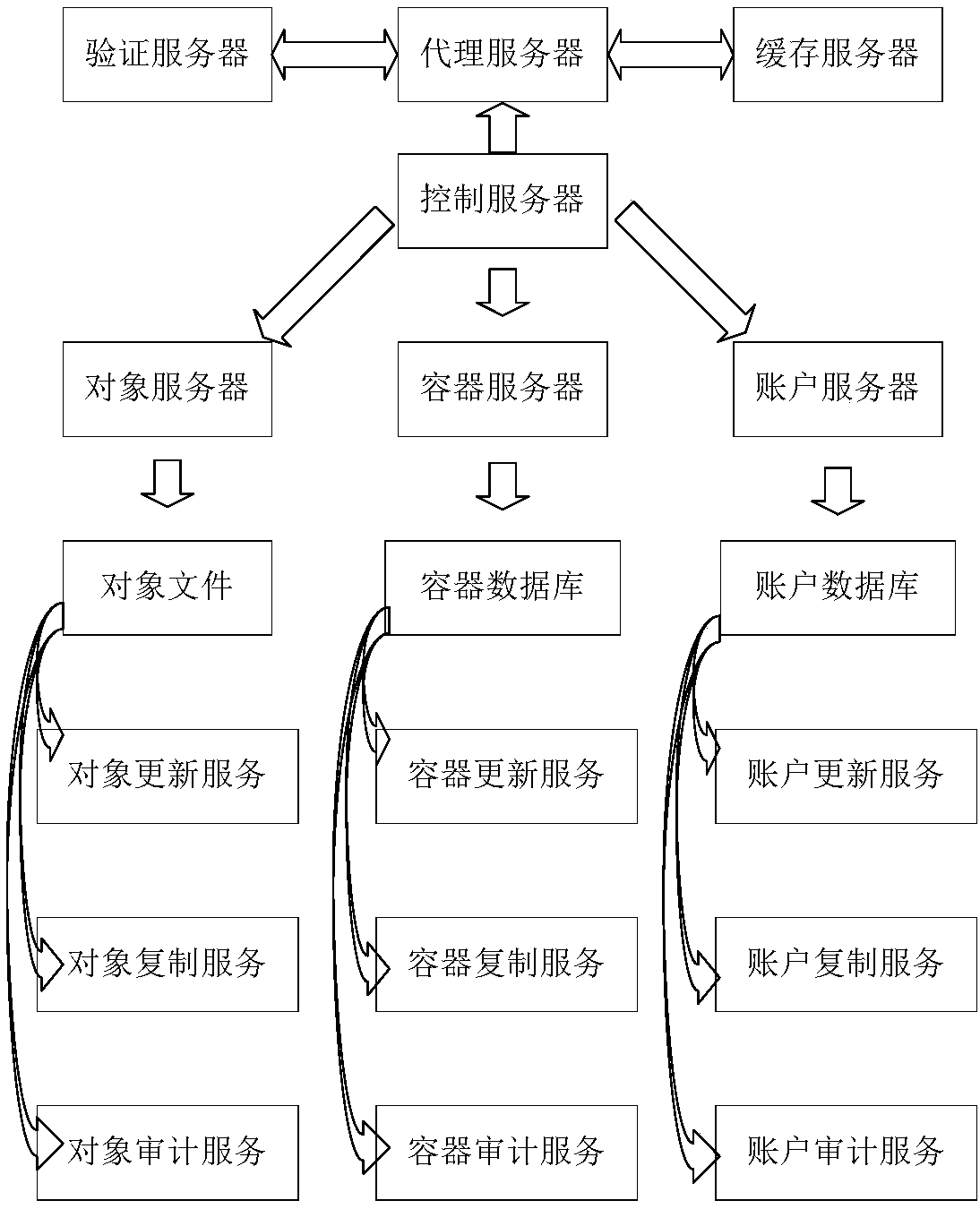
[0018] Aiming at the characteristics of huge amount of unstructured business data, high real-time requirements, and frequent concurrent access in the specific field of electric power, the present invention proposes a solution for massive data storage and related services based on cloud architecture, which is scalable and low-cost. Cost, high performance, ease of use and reliability. Experimental data shows that this solution can effectively improve data storage and response time under existing conditions.
[0019] Cloud storage is a distributed file system composed of a large number of ordinary computer clusters interconnected through a high-speed network. It is managed and maintained by administrators, and provides data storage and business access functions as a whole. The system uses API or API-based applications to provide external network access, which has the characteristics of scalability, low cost, high performance, and ease of use. In view of the characteristics of hu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



