

Language model pre-training method
A language model and pre-training technology, applied in the artificial field, can solve problems such as hindering Chinese migration, unbalanced samples, random effects of training effects, etc., to achieve the effect of improving prediction accuracy and improving prediction results.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
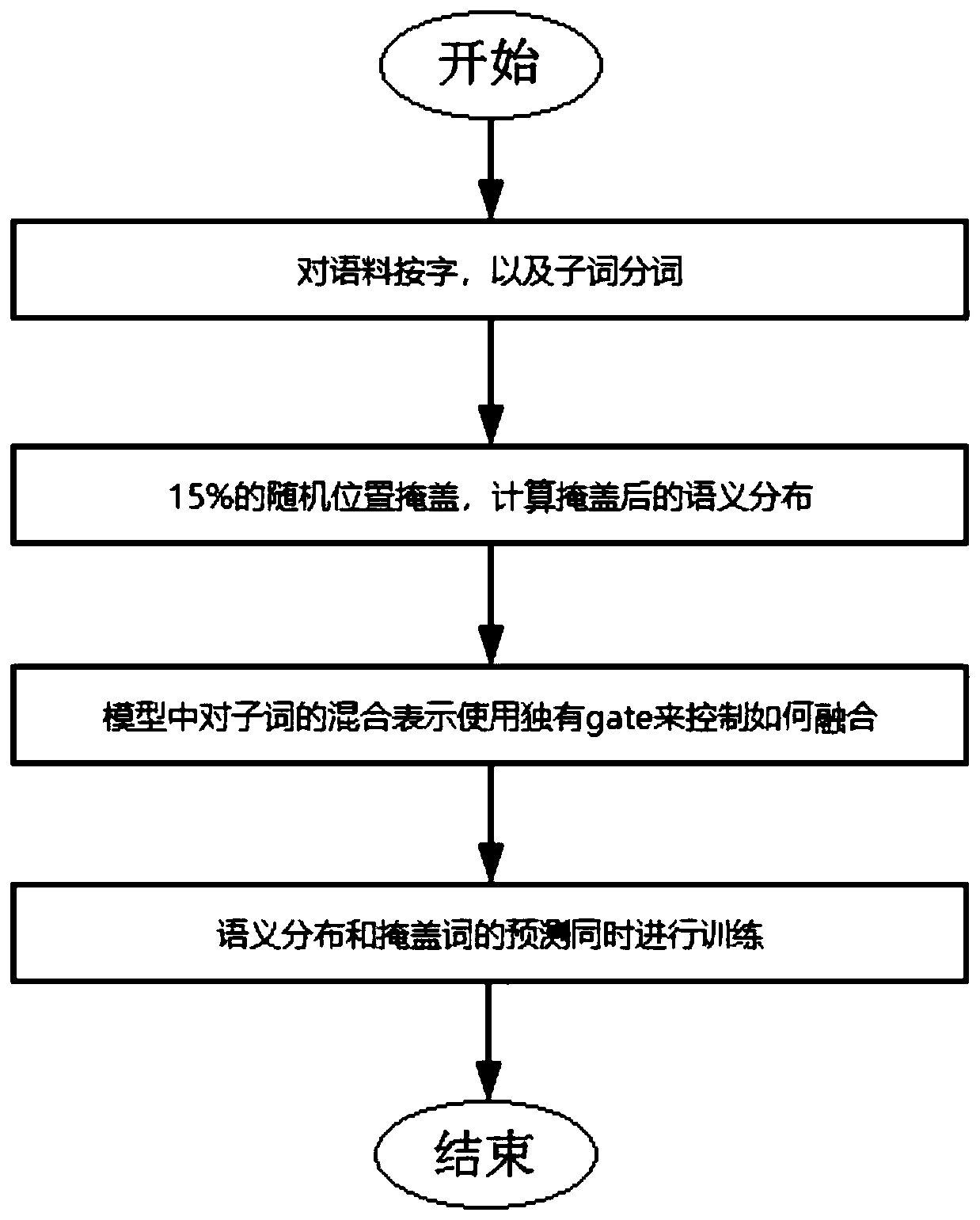
[0014] Using the company's internal job classification data as the corpus, the goal is to predict the job classification corresponding to each piece of work experience. In this example, there are 1930 categories in job classification. The network structure uses the Transformer in the BERT model as the basis, and a piece of work experience is input. After the Transformer, the output feature representation uses the Attention mechanism, and the prediction of the 1930 class is output. The training target uses cross-entropy optimization, and the parameters in the Transformer use the parameter values in the pre-trained BERT model. Using direct prediction, prediction after pre-training based on BERT, and prediction after pre-training with the method proposed in the present invention, three groups of experiments were used to compare the prediction results.
[0015] Among them, the pre-training process carried out by the method proposed in this application is as follows:
[0016]...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More