

Detection and recovery system and method for RabbitMQ cluster fault
A detection recovery and clustering technology, applied in the field of cloud computing, can solve problems such as unavailable queues, inability to handle network partitions well, and failure of RabbitMQ component services to run normally, so as to improve availability and timeliness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
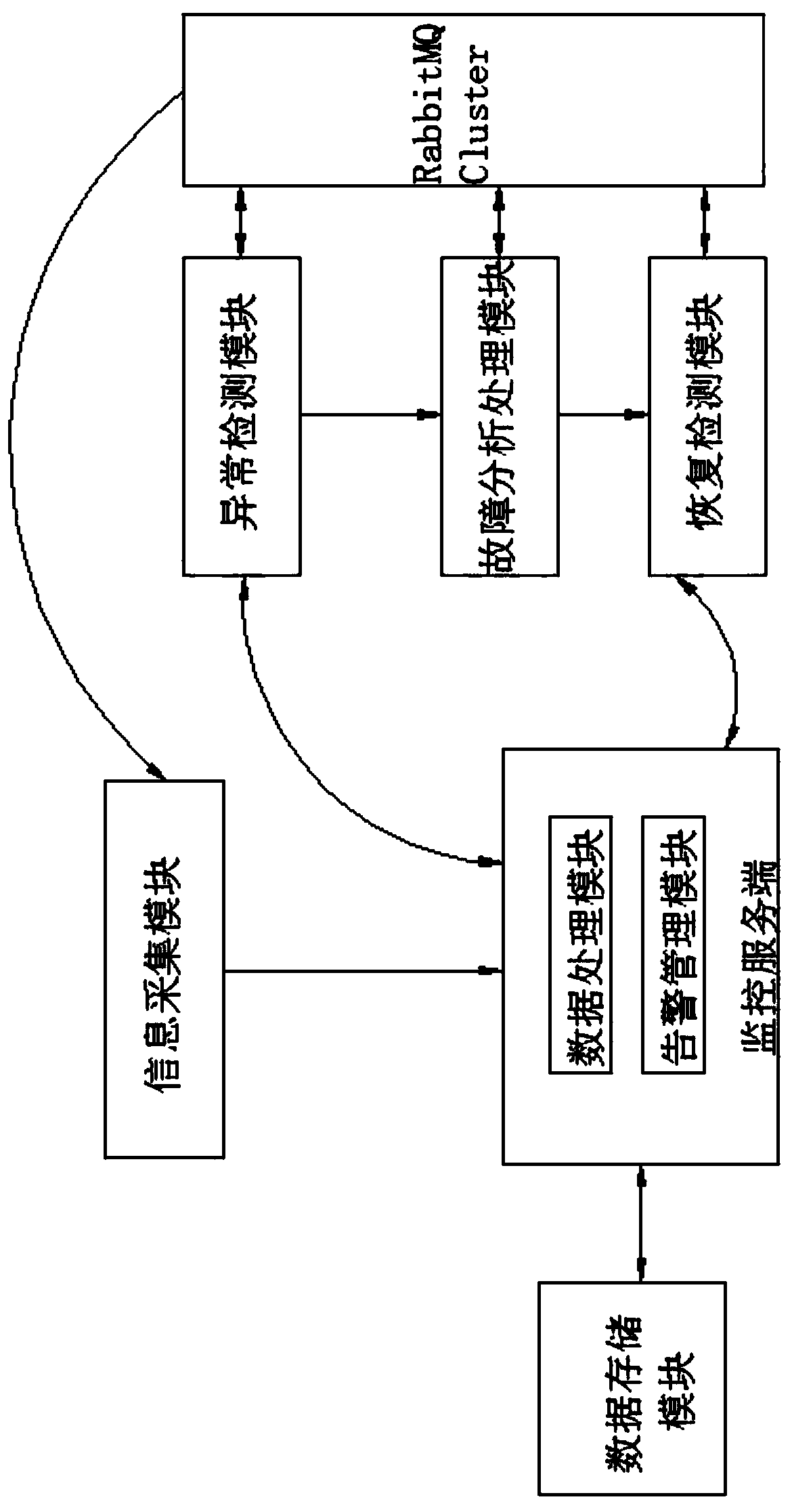
[0062] The RabbitMQ cluster failure detection and recovery system of the present invention includes an information collection module, an abnormality detection module, a monitoring server, a failure analysis and processing module, a recovery detection module and a data storage module.
[0063] Among them, the information collection module is connected to the RabbitMQ Cluster to obtain health data from the RabbitMQ Cluster. The health data is data related to the health status check of RabbitMQ nodes, including RabbitMQ service status, cluster status, log data, operating system performance indicators, operating system Performance indicators include operating system CPU / memory / disk / system load, etc.
[0064] The monitoring server includes a data processing module and an alarm management module. The data processing module is connected to the information collection module, and the health data collected by the information collection module is uploaded and stored in the data processing...
Embodiment 2
[0077] A method for detecting and recovering a RabbitMQ cluster fault of the present invention is realized based on the detection and recovery system for a RabbitMQ cluster fault disclosed in Embodiment 1, comprising the following steps:
[0078] S100, collect health data through the information collection module, and upload the health data to the monitoring server, and check the health data as data related to the health status check of the RabbitMQ node;
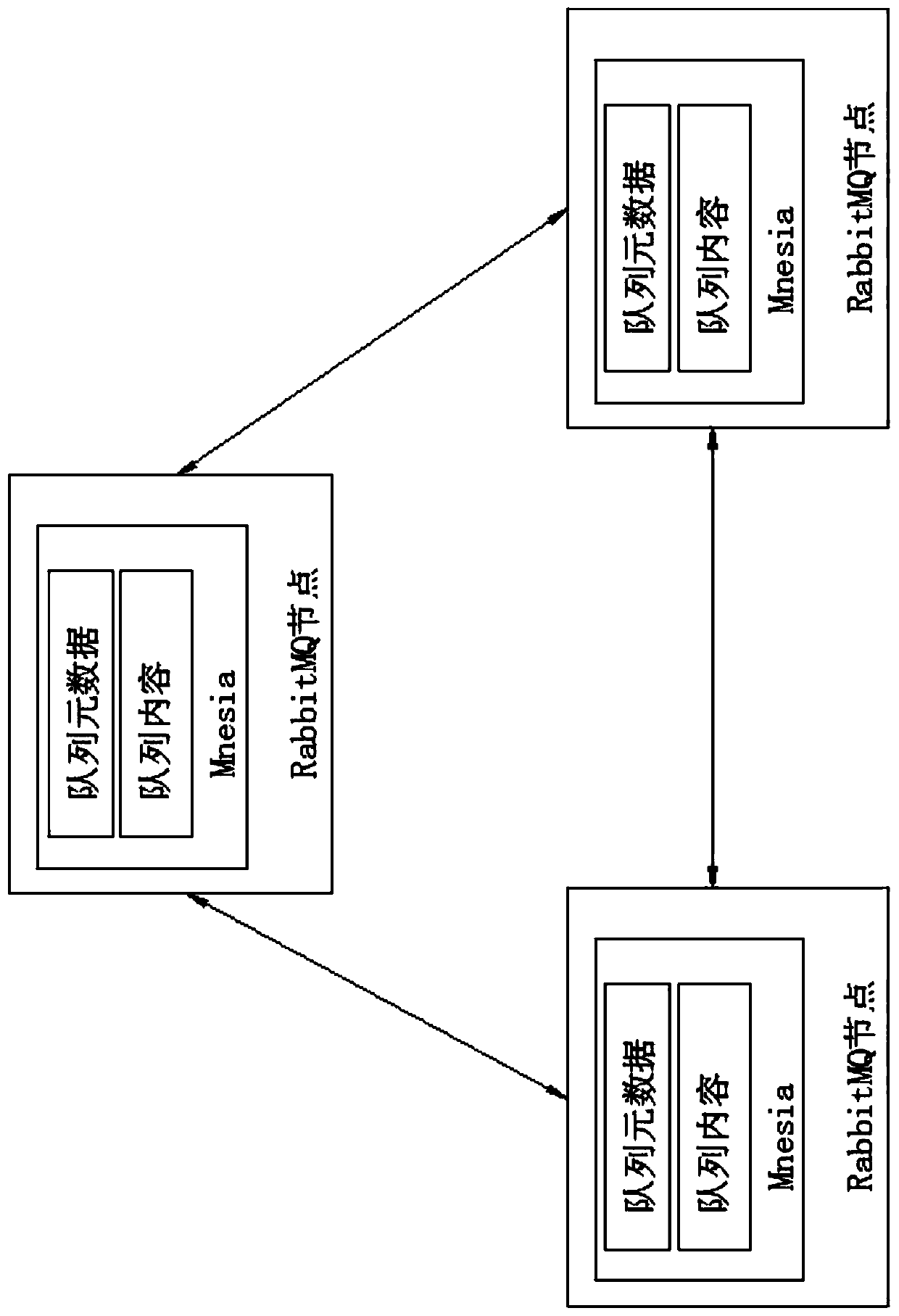
[0079] S200. Detect and analyze the health data through the anomaly detection module, and detect and analyze the consistency of the RabbitMQ cluster status and queue metadata, obtain the detection and analysis results, and upload the detection and analysis results to the monitoring server;
[0080] S300. Generate an alarm message when the detection and analysis results are abnormal through the monitoring server;
[0081] S400, generate a processing result to the RabbitMQ node according to the detection analysis result throu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More