Multi-scene self-adaptive intelligent sound amplification system
A sound reinforcement system and adaptive technology, applied in the field of sound reinforcement systems, can solve the problems of troublesome switching methods, time-consuming and labor-intensive, etc., and achieve the effect of simple control function, low cost, and reduction of background music.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
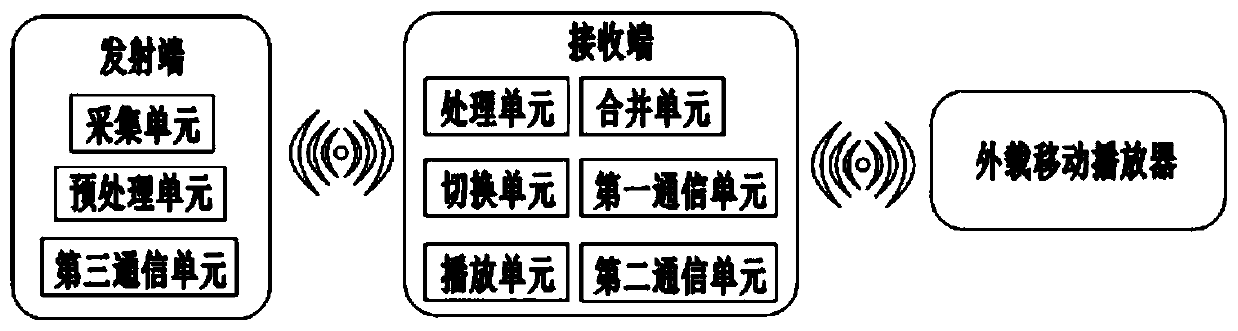
[0059] Such as figure 1 As shown, the multi-scenario adaptive intelligent public address system includes a transmitter and a receiver.
[0060] The transmitting end includes an acquisition unit, a preprocessing unit and a third communication unit.
[0061] The acquisition unit is used to collect human voice; the preprocessing unit is used to preprocess the collected human voice (such as noise reduction, gain adjustment, etc.), and the third communication unit is used to communicate with the transmitter.
[0062] In this embodiment, the preprocessing module adopts a microphone amplifier chip, so that the audio signal quality can be improved while the accuracy of audio collection can be improved, thereby greatly improving the quality of the voice sent to the receiving end. The third communication unit is a 2.4G module. Compared with the FM module, the transmission distance of the 2.4G module is longer, the transmission process is more stable, and the sensitivity is higher. In ...
Embodiment 2
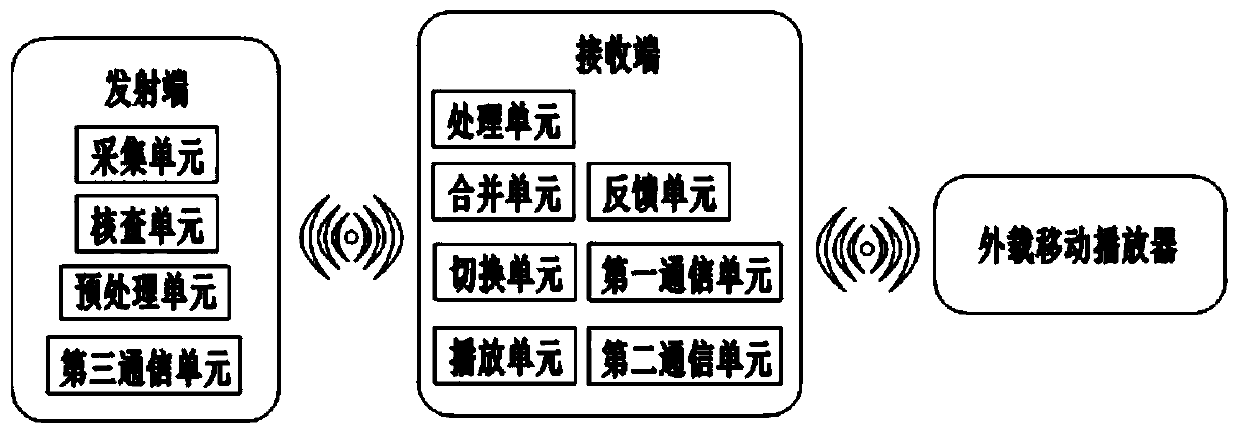
[0082] Such as image 3 As shown, the difference from Embodiment 1 is that in this embodiment, the receiving end also includes a feedback unit for sending a feedback signal to the transmitting end after receiving the data from the transmitting end; the transmitting end also includes a checking unit for checking whether the receiving end to the feedback signal;
[0083] Among them, after the transmitting end sends data to the receiving end, if the verification unit does not receive the feedback signal within T1 milliseconds, the sending end resends the data; if the verification unit does not receive the feedback signal within T2 milliseconds, then discards the data transmitted within T2 milliseconds. Data; T1<T2.
[0084] After sending the data, if the verification unit does not receive a feedback signal within T1 milliseconds, it means that data is lost during the transmission process. Therefore, the sending end resends the data to ensure the integrity of the data. If the ve...
Embodiment 3
[0087] Such as Figure 4 As shown, the difference from the first embodiment is that there are N transmitters and N first communication units in this embodiment, the value of N is 6, and any two transmitters use different communication channels.
[0088] When the receiving end receives the data of two or more transmitting ends at the same time, after the processing unit analyzes them respectively to obtain the human voice signal, the processing unit is also used to initially synthesize the obtained human voice signal to obtain a synthesized human voice signal; the synthesis unit will The synthesized human voice signal is combined with the music signal.
[0089] In this way, whether it is karaoke, speech, host or lecture, multiple users can use it at the same time, and the applicability of use is stronger.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More