Visual simultaneous localization and mapping method based on depth convolution auto-encoder
A self-encoder and deep convolution technology, which is applied in the field of image processing, can solve the problems of difficult to obtain accurate true value of pose, large absolute error of GPS, and inability to use it.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
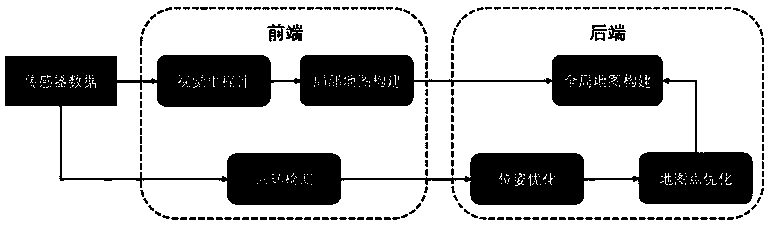
[0127] The technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, not all the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative work shall fall within the protection scope of the present invention.
[0128] A method for simultaneous visual localization and map construction based on a deep convolutional autoencoder. The method includes the following steps:
[0129] Step 1: Select different training data for data preprocessing according to requirements; such as image flipping, compression distortion, local interception, Gaussian noise, etc.
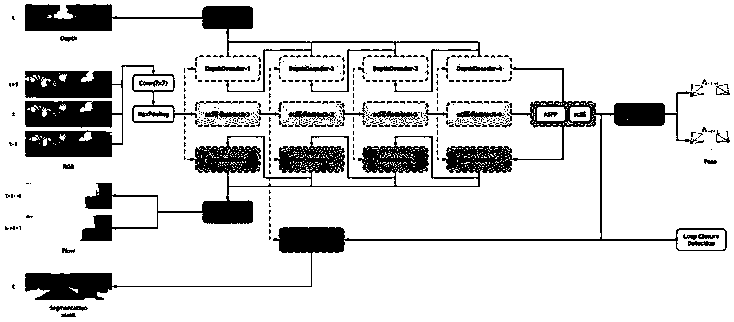
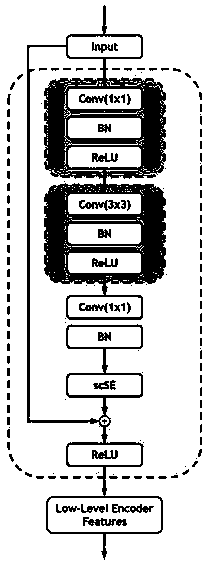
[0130] Step 2: Establish a multi-task learning network based on a deep convolutional autoencoder; the netw...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More