

Video statement positioning method based on multi-stage aggregation Transformer model
A multi-stage aggregation and video technology, applied in neural learning methods, biological neural network models, character and pattern recognition, etc., can solve problems such as independence, inability to accurately match and locate at different stages, and discard stage information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
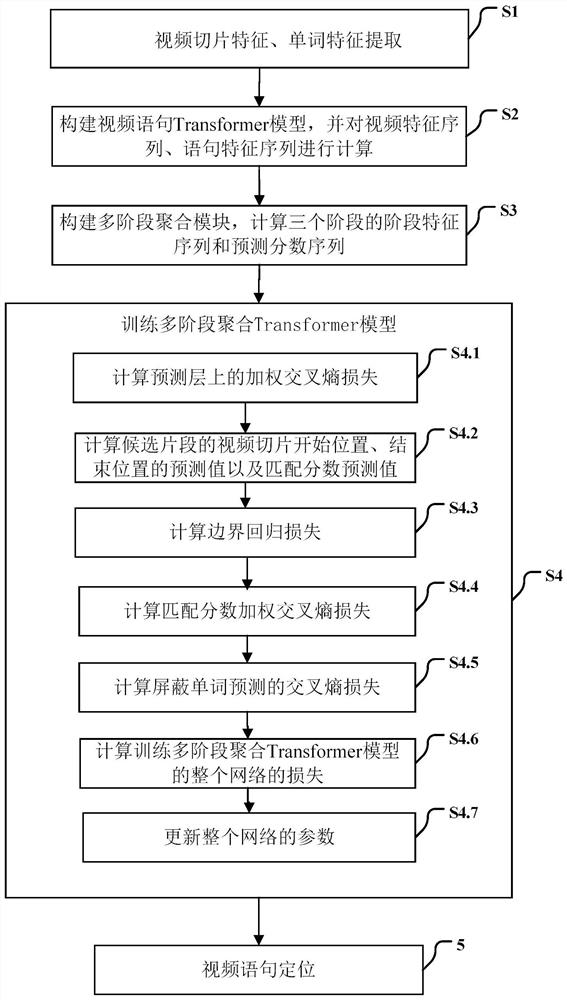
[0060] Specific embodiments of the present invention will be described below in conjunction with the accompanying drawings, so that those skilled in the art can better understand the present invention. It should be noted that in the following description, when detailed descriptions of known functions and designs may dilute the main content of the present invention, these descriptions will be omitted here.
[0061] figure 1 It is a flow chart of a specific embodiment of the video sentence location method based on the multi-stage aggregation Transformer model of the present invention.
[0062] In this example, if figure 1 As shown, the video sentence localization method based on the multi-stage aggregation Transformer model includes the following steps:
[0063] Step S1: Video slice feature, word feature extraction
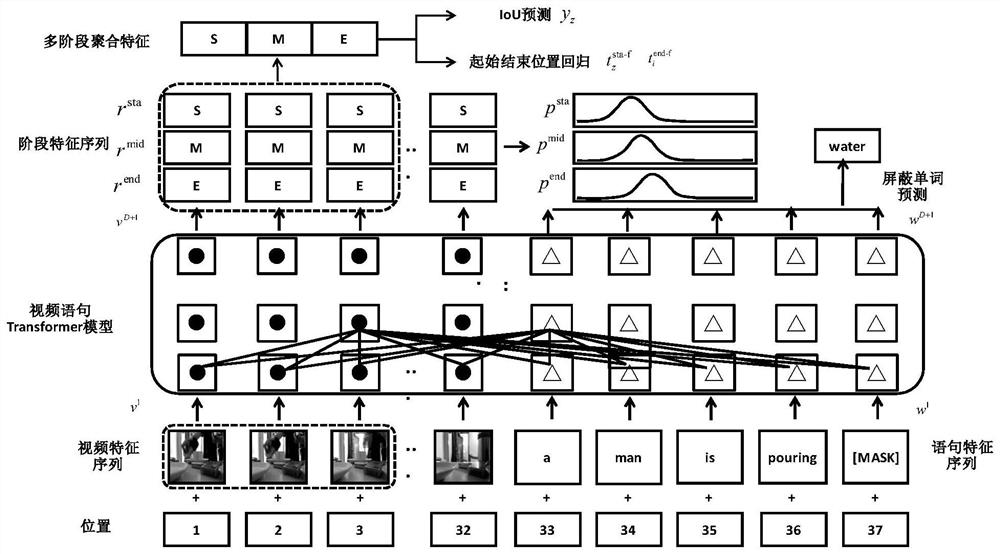
[0064] In this example, if figure 2 As shown, the video is evenly divided into N time points according to time, and at each time point, a video slice (composed...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More