

Video data feature extraction method based on audio and video multi-mode time sequence prediction
A feature extraction and time series prediction technology, applied in character and pattern recognition, instrumentation, computing, etc., can solve the problems of reducing the accurate classification of video actions, reducing the robustness of model noise, and reducing the accuracy of action recognition, so as to reduce the burden of network learning. , The effect of removing modal redundant features and improving understanding ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
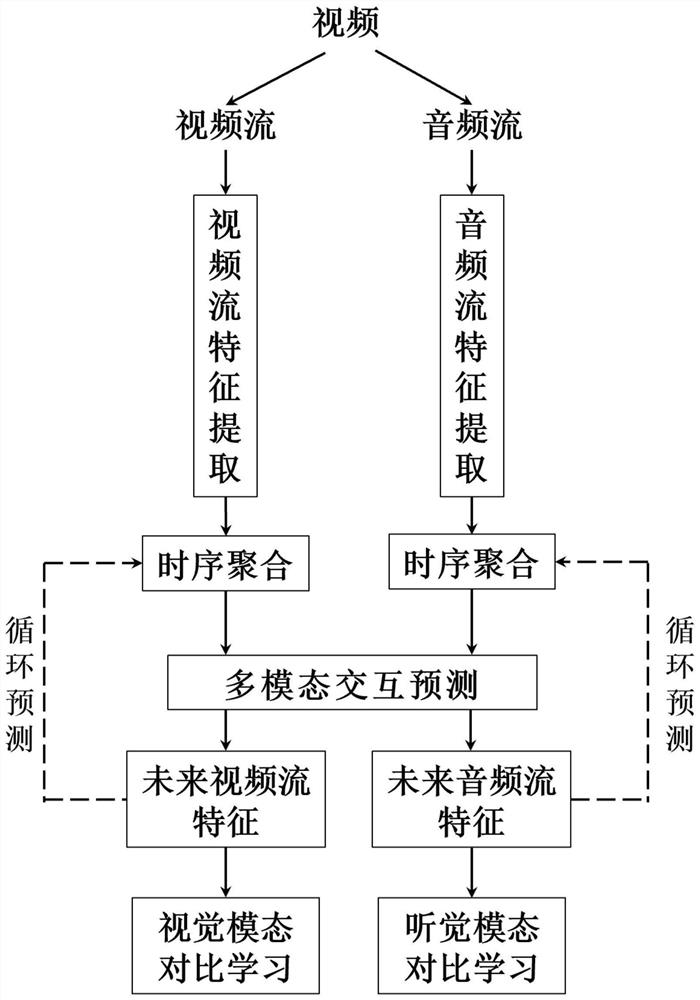
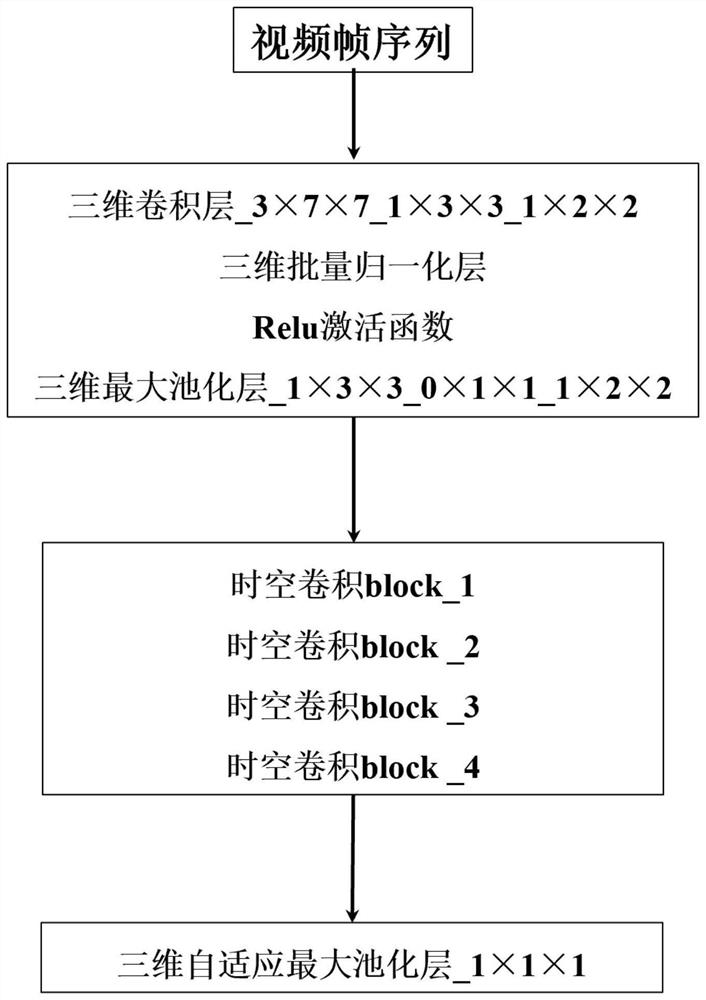
[0047] In this example, if figure 1 As shown, a video data feature extraction method based on audio and video multimodal timing prediction comprises the following steps:
[0048] Step 1. Utilize the video acquisition device to obtain the video data set, denoted as X={X 1 ,X 2 ,...,X i ,...,X N},X i Represents the i-th video, 1≤i≤N, N represents the total number of videos, extract the audio stream A and video stream V from the video data set X, denoted as in, Denotes the i-th video X i audio stream, Denotes the i-th video X i video stream of Represent the i-th audio and video data pair, thereby constructing the audio and video data pair set S={S 1 ,S 2 ,...,S i ,...,S N};
[0049] In the specific implementation, for example, use opencv and moviepy tools (other methods can also be used in actual operation) to extract video frames and audio respectively for a piece of video, construct a set S of audio and video data pairs, and retain frame timestamps for subsequ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More