

Audio and video multi-mode sentiment classification method and system
A sentiment classification, multi-modal technology, applied in speech analysis, neural learning method, speech recognition and other directions, can solve the problem of lack of unified method for audio and video raw data, unable to extract facial features, etc., to improve information processing efficiency, The effect of simplifying computing overhead and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

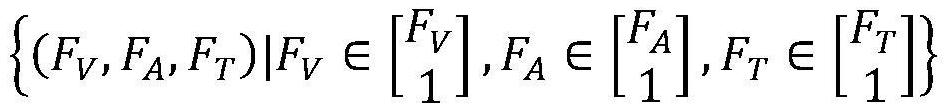
Examples
Embodiment 1
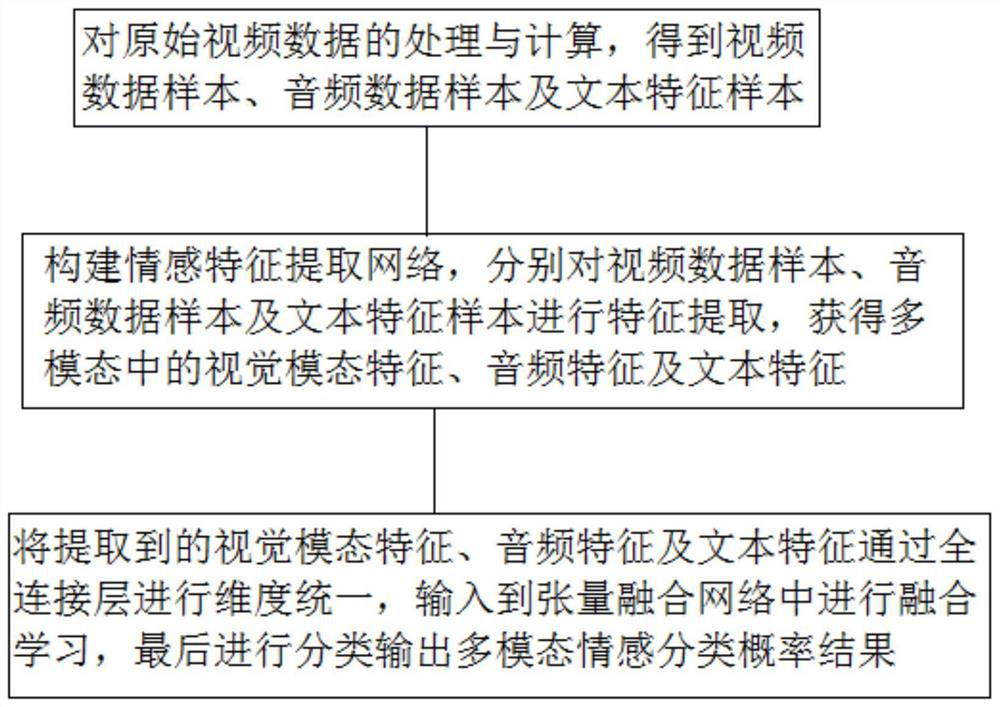
[0032] Such as figure 1 As shown, in the present embodiment, audio-video multimodal emotion classification method comprises the following steps:
[0033] S1. Processing and calculation of raw video data
[0034] Obtain key frames and audio signals from the input original video clip; for each key frame, the frame picture is scaled and input to the face detection module, if the frame picture does not contain a face, the frame picture is equal-sized Segmentation; if the frame picture contains a human face, use the Megvii Face++ open source API to extract the key points of the human face; perform Mel Spectrogram calculation and MFCC (Mel Frequency Cepstral Coefficient) calculation on the audio signal, using open source voice The text-to-text toolkit Deepspeech converts audio into text, and the related functions provided in Transformers (self-attention transformation network) convert the text into word vectors and generate sentence symbols according to the text sentence structure....
Embodiment 2
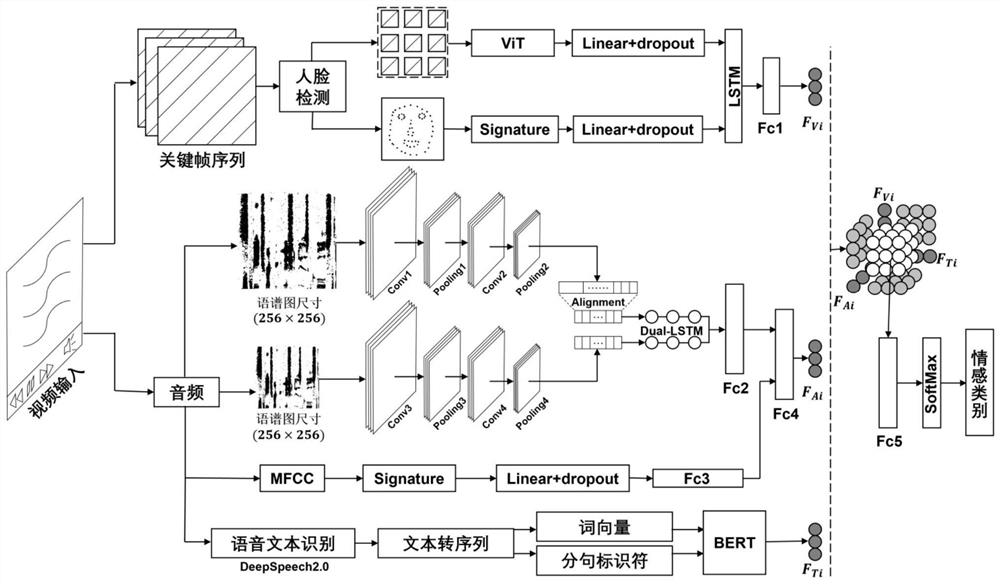
[0060]Based on the same inventive concept as Embodiment 1, this embodiment provides an audio-video multimodal emotion classification system, such as figure 2 shown, including:
[0061] The data preprocessing module is used to realize the step S1 of embodiment 1, to the processing and calculation of the original video data, to obtain video data samples, audio data samples and text feature samples;
[0062] The emotional feature extraction module is used to realize the step S2 of embodiment 1, construct an emotional feature extraction network, and perform feature extraction on video data samples, audio data samples and text feature samples respectively, and obtain visual modal features, audio features and text features;
[0063] The feature fusion and classification module is used to implement step S3 of Embodiment 1, unify the extracted visual modality features, audio features and text features through the fully connected layer, input them into the tensor fusion network for f...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More