

Sound detection model training method and device, and sound event detection method
A sound detection and training method technology, applied in neural learning methods, biological neural network models, computer components, etc., can solve problems such as hearing loss and low efficiency, and achieve the effect of lowering the detection threshold and improving detection efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
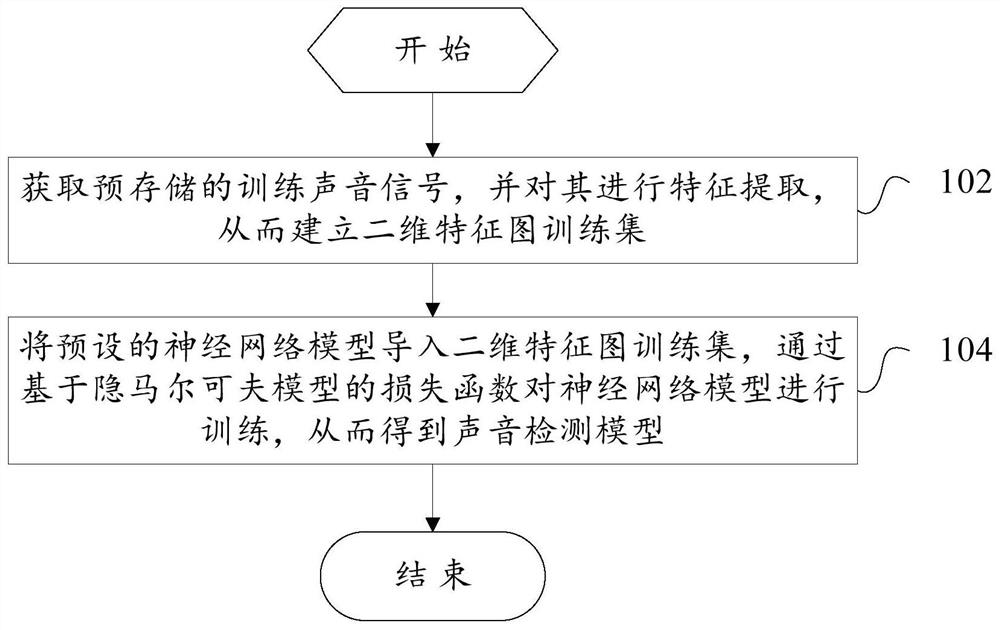
[0104] figure 1 One of the flowcharts showing the training method of the sound detection model according to the embodiment of the present invention, specifically, the training method of the sound detection model may include the following steps:
[0105]Step 102, obtaining a pre-stored training sound signal, and performing feature extraction on it, thereby establishing a two-dimensional feature map training set;
[0106] In step 104, the preset neural network model is imported into the two-dimensional feature map training set, and the neural network model is trained through a loss function based on the hidden Markov model, thereby obtaining a sound detection model.
[0107] In the embodiment of the present invention, by training a neural network model capable of automatically realizing sound event detection, that is, a sound detection model, it is beneficial to realize automatic sound event detection and improve the efficiency of sound event detection.
[0108] Specifically, f...
Embodiment 2
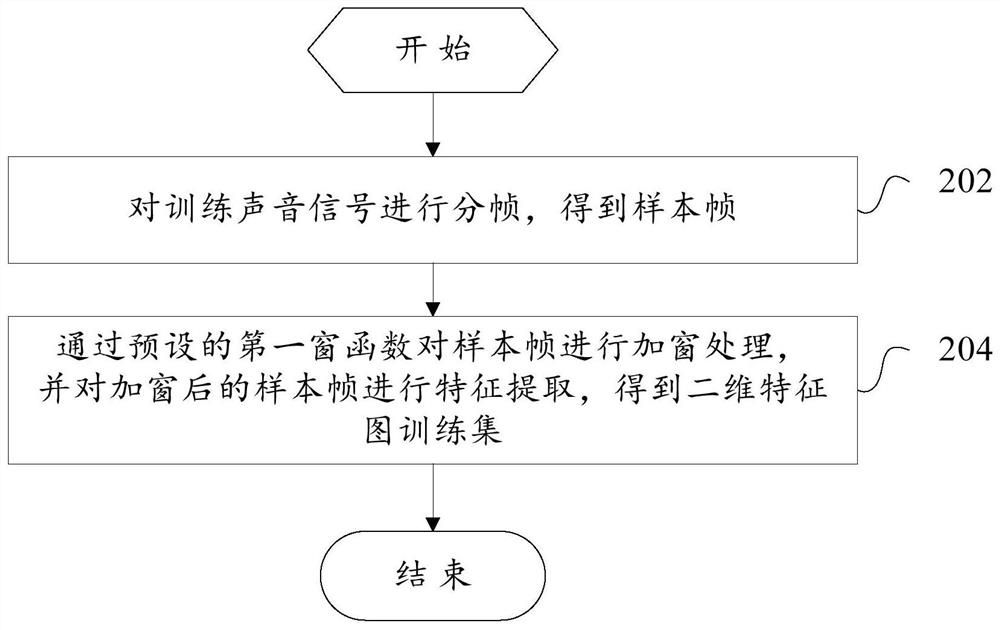
[0113] figure 2 The second flow chart showing the training method of the sound detection model according to the embodiment of the present invention, specifically, the training method of the sound detection model may include the following steps:
[0114] Step 202, divide the training sound signal into frames to obtain sample frames;
[0115] Step 204 , performing windowing processing on the sample frames by using a preset first window function, and performing feature extraction on the windowed sample frames to obtain a two-dimensional feature map training set.
[0116] In the embodiment of the present invention, when performing feature extraction on sound, the sound signal is first subjected to frame processing to obtain sample frames of a certain length, wherein each sample frame is a sound segment, and the interval between two adjacent sample frames is There may be some overlap between them. Wherein, the frame length (the duration of the sound sample) and the overlapping l...
Embodiment 3
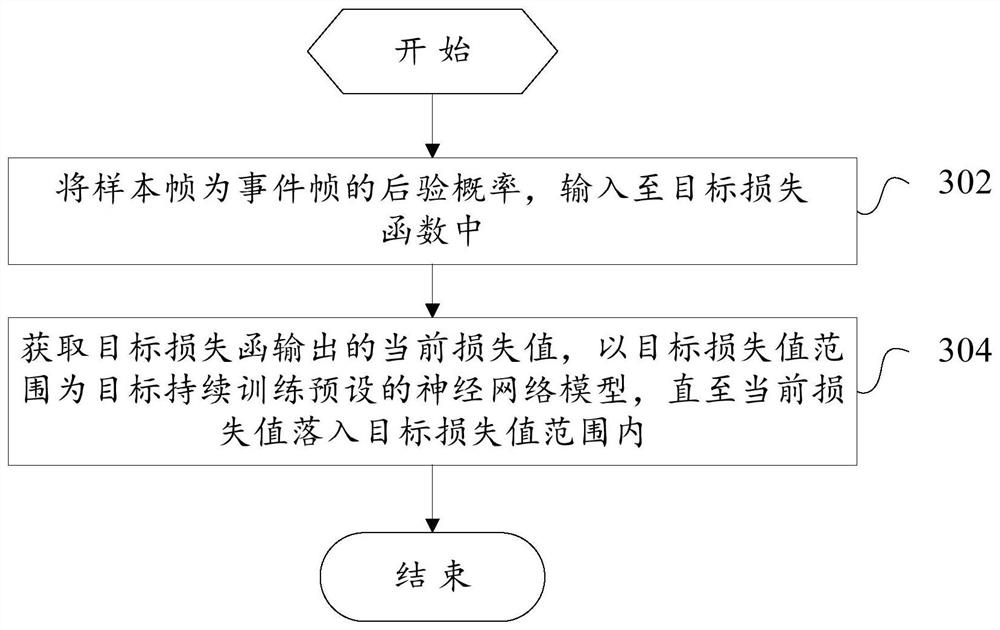
[0120] image 3 The third flow chart showing the training method of the sound detection model according to the embodiment of the present invention, specifically, the training method of the sound detection model may include the following steps:
[0121] Step 302, input the posterior probability that the sample frame is an event frame into the target loss function;
[0122] Step 304, obtaining the current loss value output by the target loss function, and continuously training the preset neural network model with the target loss value range as the target until the current loss value falls within the target loss value range.
[0123] In the embodiment of the present invention, when training the preset neural network model through the two-dimensional feature map training set, the two-dimensional feature map training set is input into the neural network model, and the neural network model will The feature map training set outputs a specific result, specifically the posterior proba...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More