Method for watermarking small wave threshold digital audio multiple mesh based on blind source separation
A technology for digital audio and blind source separation, applied in digital transmission systems, image data processing, image data processing, etc., can solve the problem of small robust watermark information, complex embedding and extraction methods, watermark security depends on watermark embedding and extraction method etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

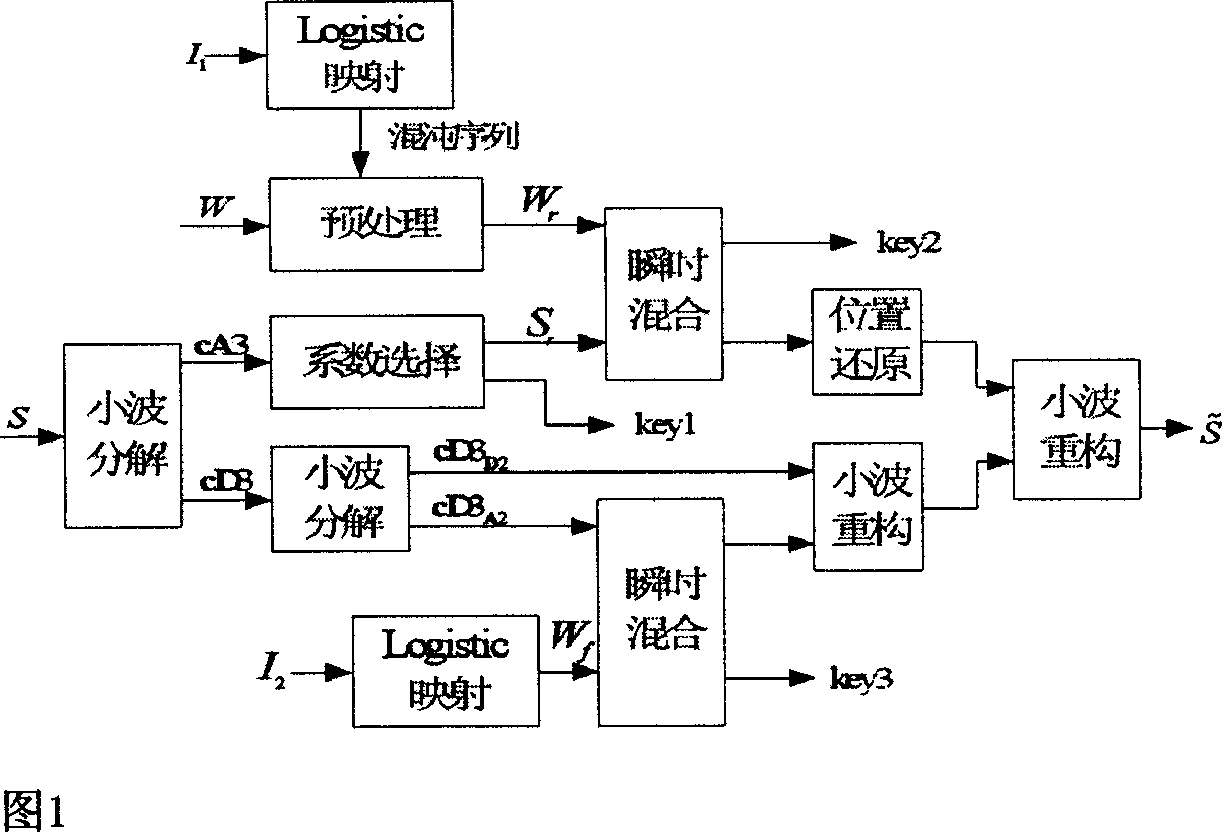
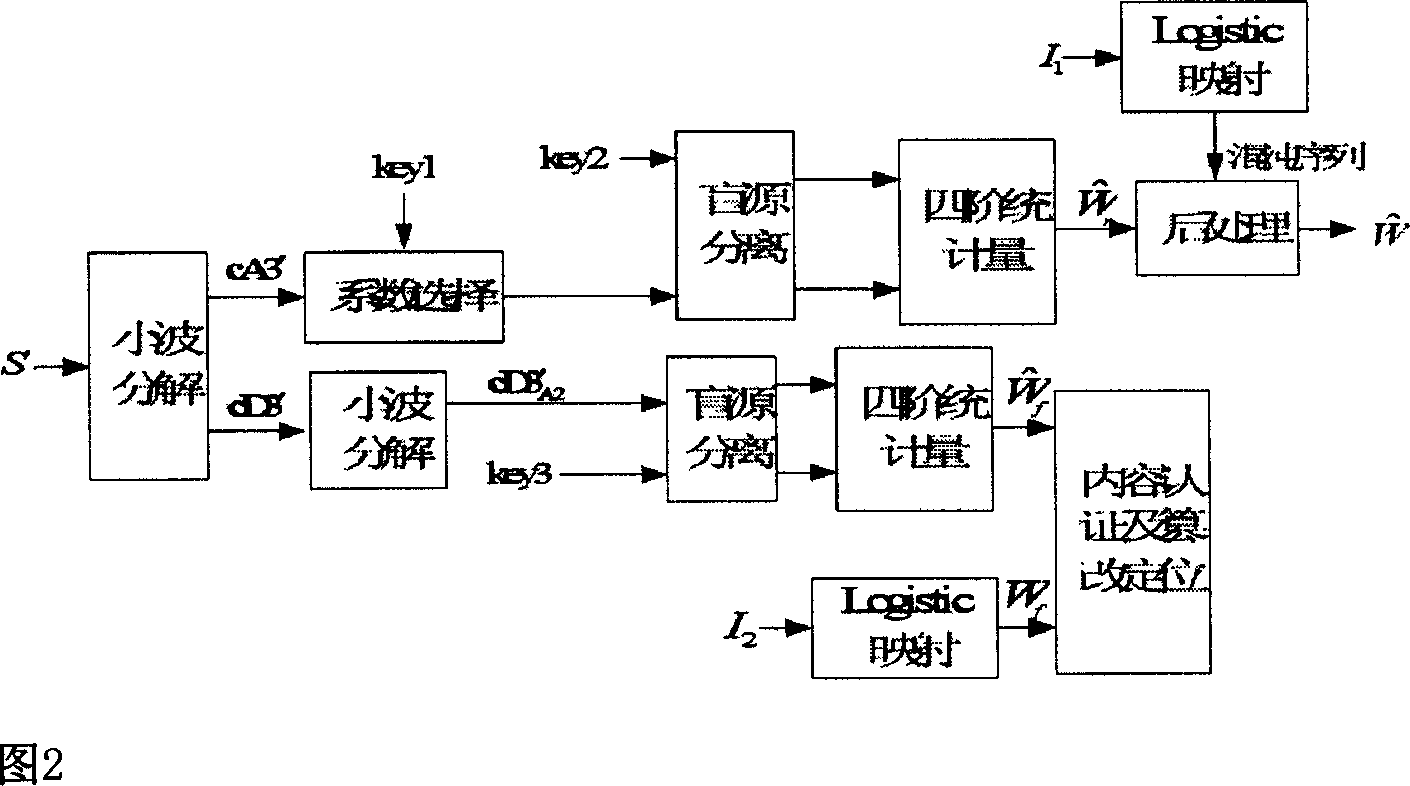
Examples
Embodiment 1
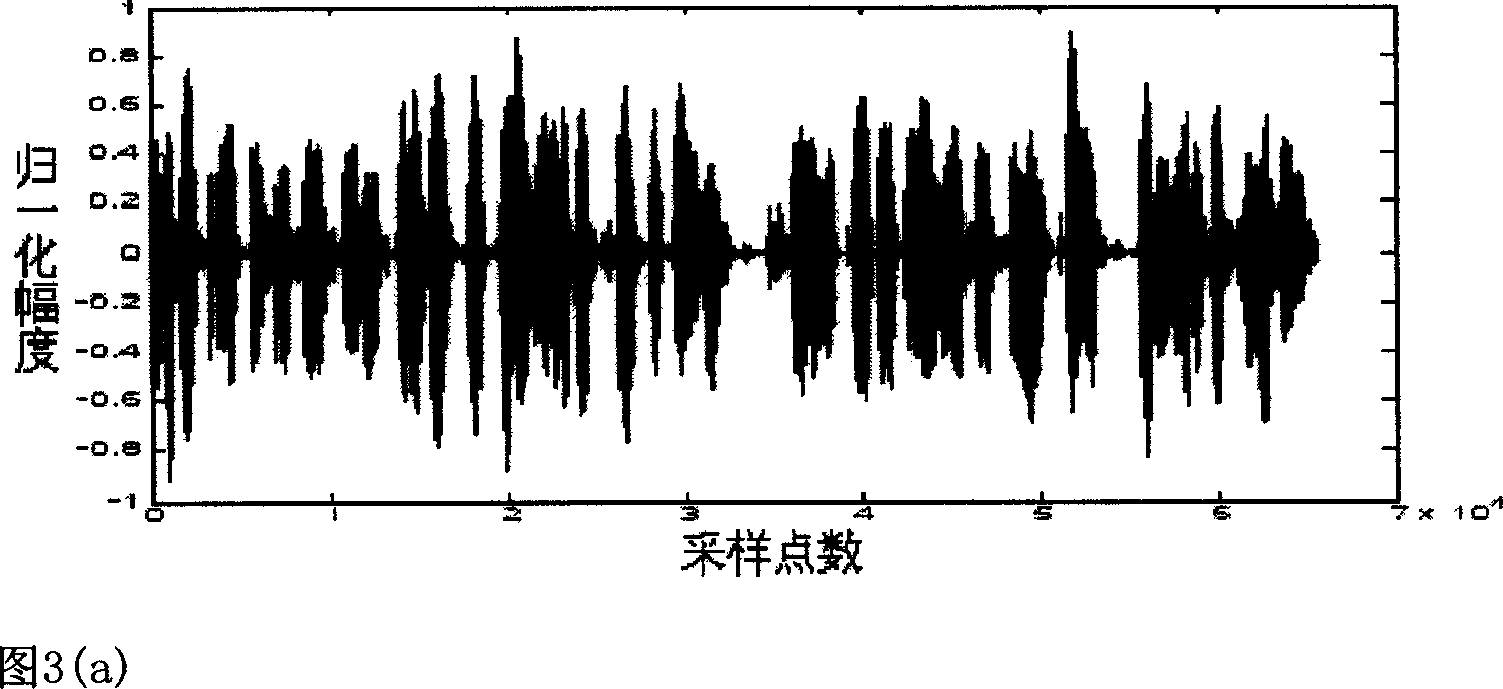
[0058] The original audio signal is selected as a speech signal, and two situations of adult males and young females are considered. When the original audio signal is a speech signal, the parameters in the experiment are selected as follows: a r11 =0.75, a r12 =0.25, a r21 =0.99, a r11 =0.01; a f11 =0.97, a f12 =0.03, a f21 =0.95, a f22 =0.05; K=2048, th1=0.6, th2=20. Each piece of test speech (that is, the original audio signal) is monophonic, with a sampling frequency of 8kHz, a resolution of 16 bits, and a length of 8.192s. The time-domain waveform of an adult male speech signal is shown in Figure 3(a). The audio signal after embedding robust watermark and fragile watermark is shown in Fig. 3(b). Comparing Figure 3(a) and Figure 3(b), it can be seen that there is no difference between the two; the listening test of more than 10 people also shows that the audio signal after embedding the two watermarks has no perceivable distortion.
[0059] A robust binary watermar...
Embodiment 2
[0062] The original audio signal is selected as a piece of music signal, and three situations of popular music, classical music and country music are considered. When the original audio signal is the above three music signals, the parameters in the experiment are selected as follows: a r11 = 0.90, a r12 = 0.10, ar21 =0.99, a r11 = 0.01; a f11 =0.97, a f12 =0.03, a f21 =0.95, a f22 =0.05; K=2048, th1=0.6, th2=15.
[0063] Experimental results show that for the above music signals, the algorithm proposed by the present invention can also achieve better results. Especially for resampling attacks, the robustness when the original audio signal is a music signal is far better than that of a speech signal.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com