Currently, there is no convenient way for users to spatially analyze non-spatially referenced data.
With these limited options, it is difficult for users to determine the interaction of various data to a spatial perspective.
These applications are not, however, designed to support
business data in spatial form.
It is difficult for users simultaneously to view spatially referenced data and non-spatially referenced data, such as
customer information, sales results, and inventory levels.
Since there are so many different possible results that can be generated based on user requests, it is very difficult to anticipate all of the possible results, and preload and pre-reference
static data (e.g., images) that represent all of the possible results.
Thus, there are numerous problems in the existing spatial systems solutions.
One problem is dynamically accessing data sets and generating spatial references (i.e.,
geocoding) for enterprise data sets that are typically not spatially-referenced (e.g., sales results,
customer information, inventory levels,
plant or asset locations, etc.).
Another problem is simultaneously combining enterprise data with
third party data (e.g., geographical data) to allow enterprises to spatially analyze and visualize enterprise data and other data (e.g., traditional spatially referenced data sets in a spatial context).
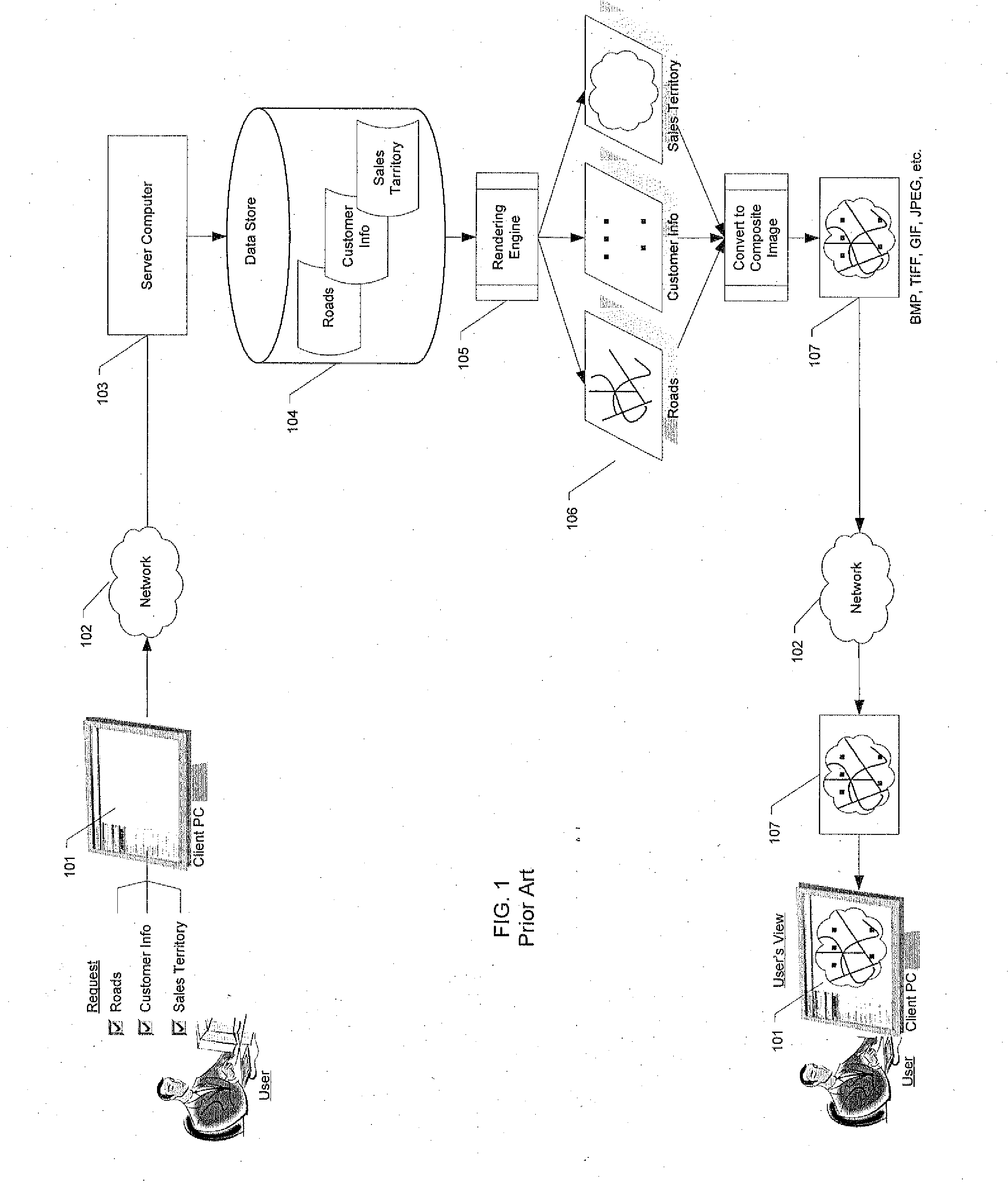
Since the
server computer needs to combine the images into one composite image, and then send the composite image to the
client, several problems occur.
Several problems occur with the technique illustrated in FIG. 2.
Yet another problem is that Geographic Information Systems (GIS) require data to be in a very specific format that allows
client applications to process and allows users to view the data spatially.
The conventional process for converting data so that the data may be viewed spatially cannot be easily automated because of the manual
processing required.
The manual processes also make it very difficult to track the
chain of custody for the data.
This is a problem in a
server computer that handles data from different customers.
The manual processes also make it difficult to generate
data validation procedures that can guarantee the integrity of the data across all the processes.
The resulting transformed data is typically no longer
usable by existing applications.
Moreover, the resulting data cannot be made visible to the
client applications without restarting the client and
server processes.
A further problem is that conventional systems provide
access control to data with one of two approaches.
Both approaches have several problems.
Moreover, it is very difficult to customize the presentation of data to the user based on access information associated with the user.
This creates a very cumbersome process of user access right management within the application and from the perspective of the personnel setting up access rights to the server computer.
Moreover, the application gets tied into the back end
data store technology used, and it is extremely difficult to replace back end
data store technology with a new technology as it becomes available.
Also, application code gets extremely complex when multiple data stores with different access requirements are used.
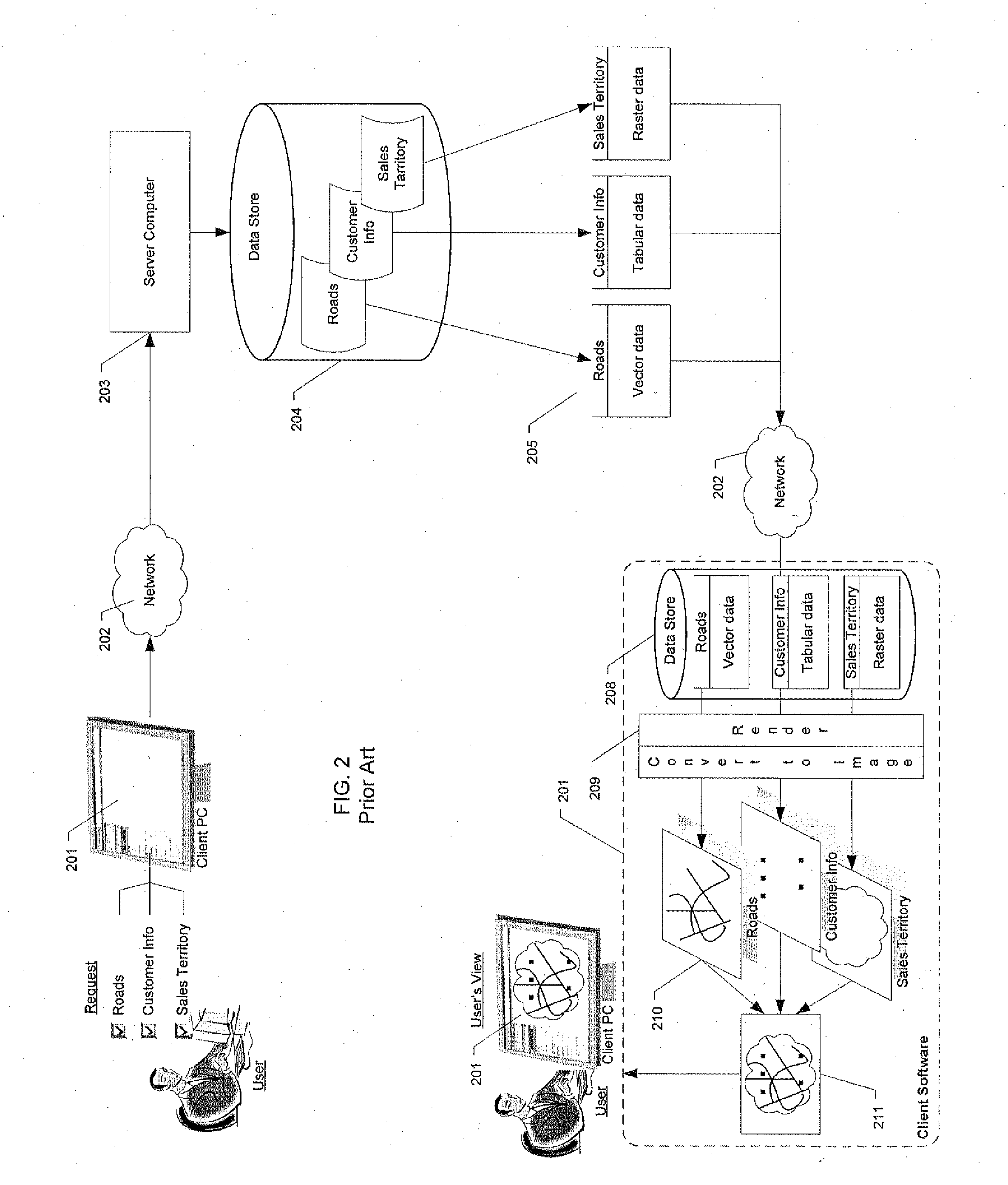
Further problems occur in conventional systems when displaying images from pyramided data.
The one-to-one relationship between data sets and their corresponding data layer representation by the client
software creates several problems.
For example, unnecessary information about how data is stored on the back end
data store is exposed to the client
software.
Therefore, in a typical application, a user can be presented with an overwhelming number of data
layers, many of which are duplicate data
layers for the same set of data at different
zoom scales.
Since the user is allowed to view only one
individual data layer at a time in a
pyramid based on the user's
zoom scale, as the user zooms in or out, the data layer the user is currently viewing may suddenly become unavailable for viewing.
That is, the switchover from one level in the
pyramid to the next is not always transparent.
These conventional systems, however, do not store any other form of spatially referenced data, such as vector data.
If an organization wishes to apply custom
business logic and validations to the manipulation and viewing of spatially enabled information, many steps are necessary and the process is expensive.
Another problem in conventional Geographic Information Systems (GIS) is the difficulty in editing images.
There are several problems with trying to implement an effective editor in client
software.
For example, it is difficult to separate a data layer to be edited from all of the other data
layers forming the displayed composite image.
It is difficult to gather needed information about the elements in the data layer to be edited and to transfer this information from the server computer to the client software quickly.
Also, there is typically a
slow response during editing because interactions with users are transmitted back to the server computer for
processing.
There is difficulty in matching complicated graphical object boundaries to avoid overlaps or exclusion areas by use of “snap to” functions, which match new vertices to existing vertices.
Furthermore, it is difficult to copy portions of graphical objects from various data layers to assist with building or modifying graphical objects.
Conventional editors also lack the ability to tailor the
user interface.
A further problem in a conventional Geographic Information Systems (GIS), involves sharing of customized views of data layers among different users.
In terms of a first type of functionality, some GIS systems provide the ability to save only a limited subset of customizations, such as annotations, in a specific user area on the
server system, but they do not provide a means to share these customized views with other users of the server computer.
In terms of a second type of functionality, other GIS systems allow a limited set of customizations to be shared with other users, but they do not provide the ability to limit access to a subset of the users of the server computer.
Additionally, the first type of functionality provides access limited to only the editor / author of the customized view of the data (i.e., the project) and no other user.
These GIS systems do not have the ability to save all customization done by the user as a project, then share this project with other users, to properly discuss and possibly enable the other users to provide their inputs, comments, and modifications to the project on-line.
That is, the first type of functionality lacks on-line
collaboration of a project within a GIS
system.
Such open access creates the problem that the project will not be confidential and all users of the
system will be able to view and further modify the project on-line.
This functionality creates lack of on-line
confidentiality, security, and integrity of a project within a GIS system.
Regardless of the many benefits of using geographic information to make business decisions, it is very costly for companies to build spatial
information system infrastructure and to maintain the infrastructure properly.
Also, current techniques for acquiring and manipulating spatial data are cumbersome and very
time consuming.
Furthermore, as noted above, there are no easy techniques for integrating enterprise data that is not spatially referenced with geographic
information data to fully maximize the spatial capabilities of geographic
information data.



 Login to View More
Login to View More  Login to View More
Login to View More