

Method for keeping balance of implementation class data through local mean
A technology of local mean and data balance, applied in the field of information, can solve the problem of destroying the local consistency of data, and achieve the effect of obvious class balance, maintaining local consistency, and improving classification accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

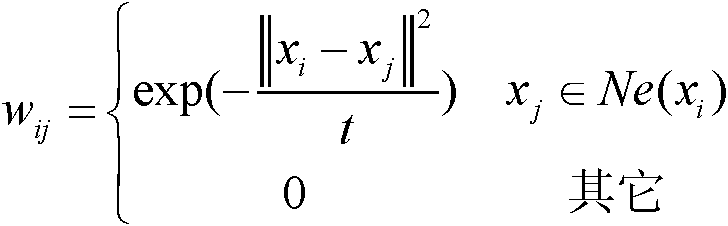
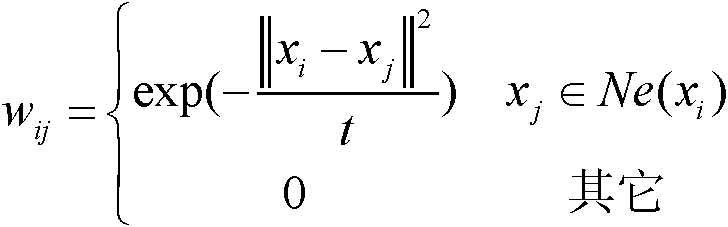
Examples
Embodiment 1
[0033] Example 1: Balanced processing of medical image data for diagnosis of lung cancer
[0034] Explanation: Among the lung medical images taken by patients, most of them are images diagnosed as non-cancer, and only a few images are diagnosed as suffering from cancer. These images are first used to train the classification algorithm, and the newly-shot Before image diagnosis, it is necessary to balance the amount of the two types of data, otherwise, the diagnostic accuracy of cancer will be very low.
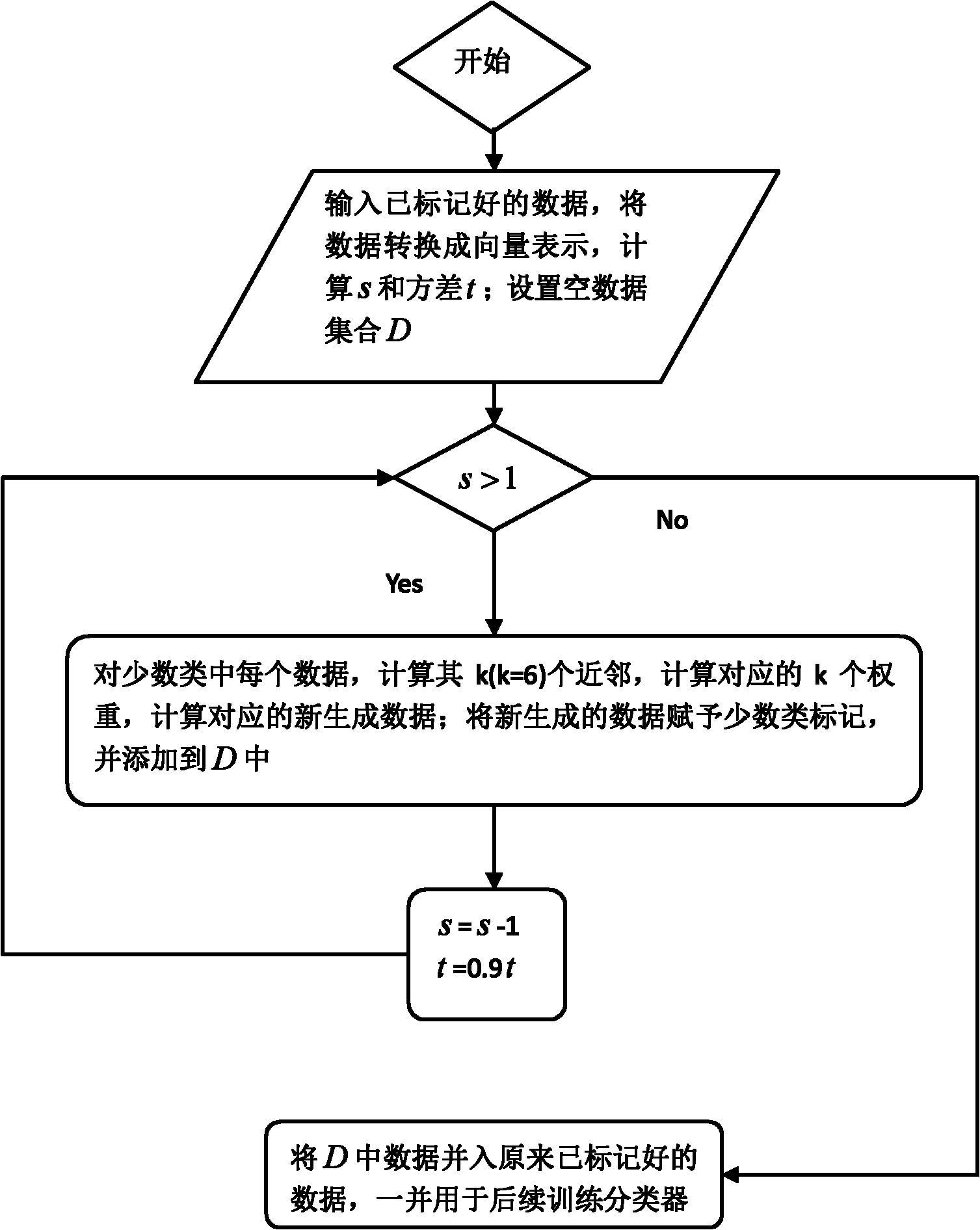
[0035] figure 1 In , the data balancing process is as follows:
[0036] 1) Collect medical images of lung medical diagnosis patients, and mark them as non-lung cancer patients and lung cancer patients according to the doctor's diagnosis results, and the image data of cancer is a minority type of data;
[0037] 2) Using general software tools such as matlab to convert medical images into multi-dimensional vector data, calculate the ratio of the numbers of the two types of ima...
Embodiment 2
[0044] Example 2: DNA data balance for abnormal DNA strand identification
[0045] Explanation: Most of the DNA images are images of normal chain structures, and only a few are images of abnormal chain structures. It is time-consuming and labor-intensive to mark by manual methods, and it needs to be completed with computer assistance. Before using the labeled data to train the classification algorithm, it is necessary to balance the amount of the two types of data, otherwise, when the learned classification algorithm recognizes new images, the recognition accuracy of the abnormal chain structure will be very low.
[0046] The data balancing process is as follows:
[0047] 1) Collect artificially marked DNA image data, and the marks are divided into normal chain image data and abnormal chain image data;
[0048] 2) according to embodiment 1 from step 2) to step 5) the same method balance data;
[0049] 3) Subsequent processing: the above-mentioned class-balanced DNA data is f...
Embodiment 3
[0050] Embodiment 3: web page data balance is used for spam page identification
[0051] Explanation: Most of the web pages are normal pages, and only a few are spam pages. It is time-consuming and labor-intensive to use manual methods to mark them, and it needs to be completed with the help of computers. Before using the marked data to train the classification algorithm, it is necessary to balance the amount of manually marked two types of page data. Otherwise, when the learned classification algorithm distinguishes new pages, if the new page is a spam page, the accuracy of being correctly identified will be reduced. will be low.
[0052] The data balancing process is as follows:
[0053] 1) Each web page manually marked as normal and garbage is represented by a popular VSM (vector space model), that is, each page is represented by a vector;
[0054] 2) according to embodiment 1 from step 3) to step 5) the same method balance data;
[0055] 3) Subsequent processing: the ab...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More