

Text sequence annotating system and method based on Bi-LSTM (Bidirectional Long Short-Term Memory) and CRF (Conditional Random Field)
A text sequence and sequence technology, applied in the information field, can solve the problems of poor Chinese word segmentation, cost a lot of manpower and material resources, and rely on the selection of features, so as to reduce the cost of manpower labeling and improve efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034] In order to make the object, technical solution and advantages of the present invention more clear, the present invention will be further described in detail below in conjunction with the embodiments and accompanying drawings. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
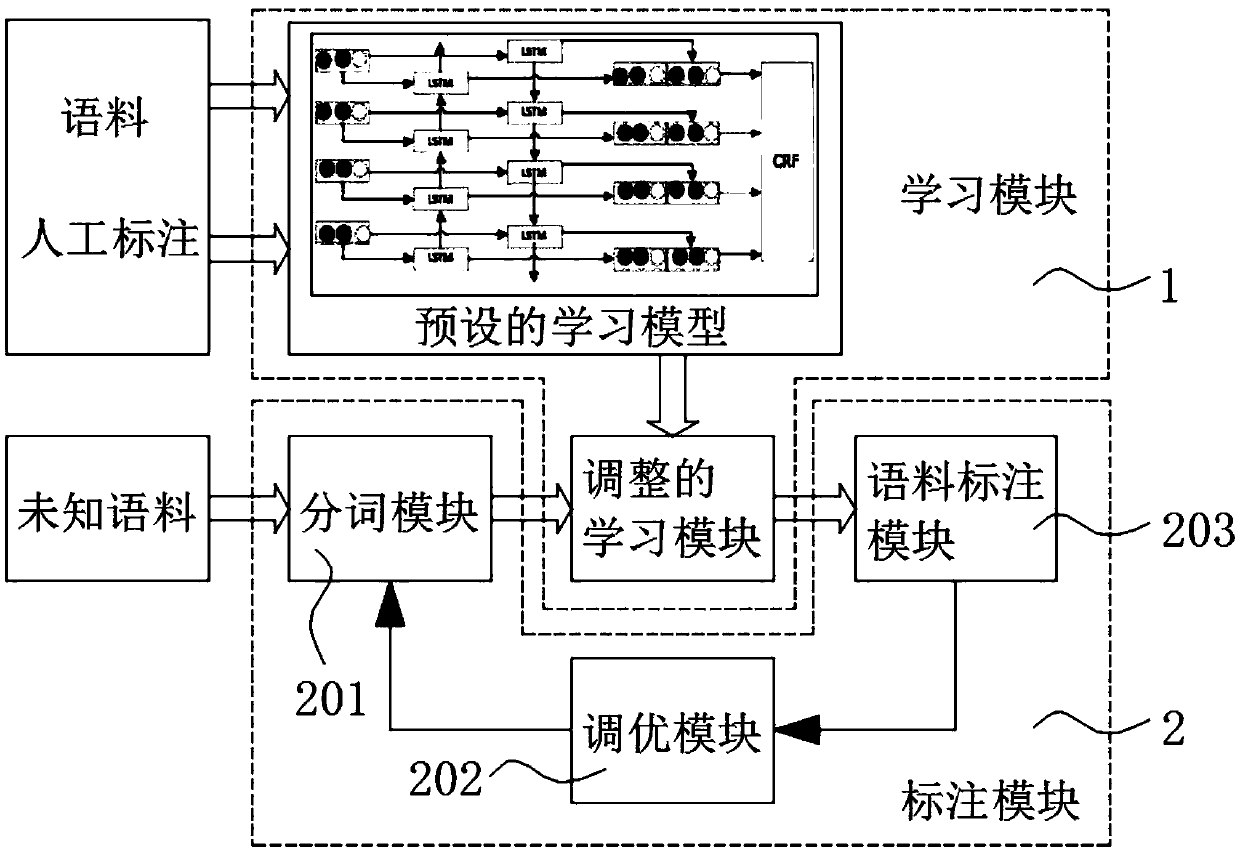
[0035] Such as figure 1 As shown, the Bi-LSTM and CRF-based text sequence labeling system of the present invention includes: a learning module 1 and a labeling module 2, the learning module 1 is used to input the acquired corpus into a preset learning model, according to The sequence classification results output by the learning model add corresponding prediction labels to the acquired corpus, and use the artificial labels to minimize and optimize the loss function of the learning model to fit the matching between the prediction labels and the artificial labels. The corpus provided to the label...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More