

Method, apparatus and computer device for identifying voice and storage medium
A technology for speech recognition and to-be-recognized, which is applied in speech recognition, speech analysis, neural learning methods, etc., and can solve problems such as insufficient accuracy of speech recognition, and achieve the goal of improving the speed of recognition, improving the accuracy of recognition, and improving the accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

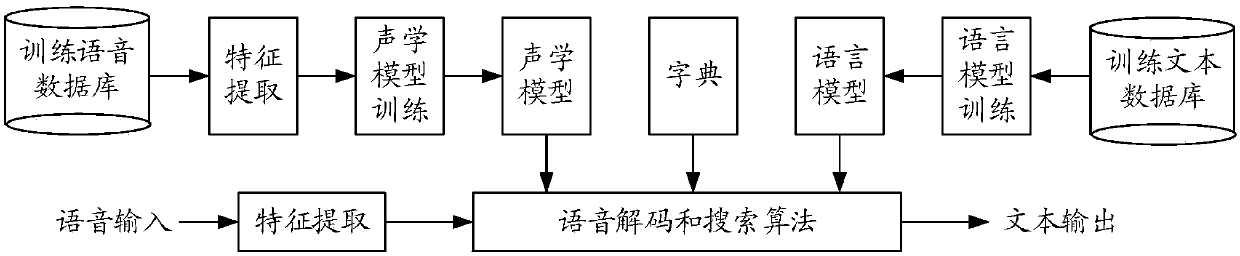
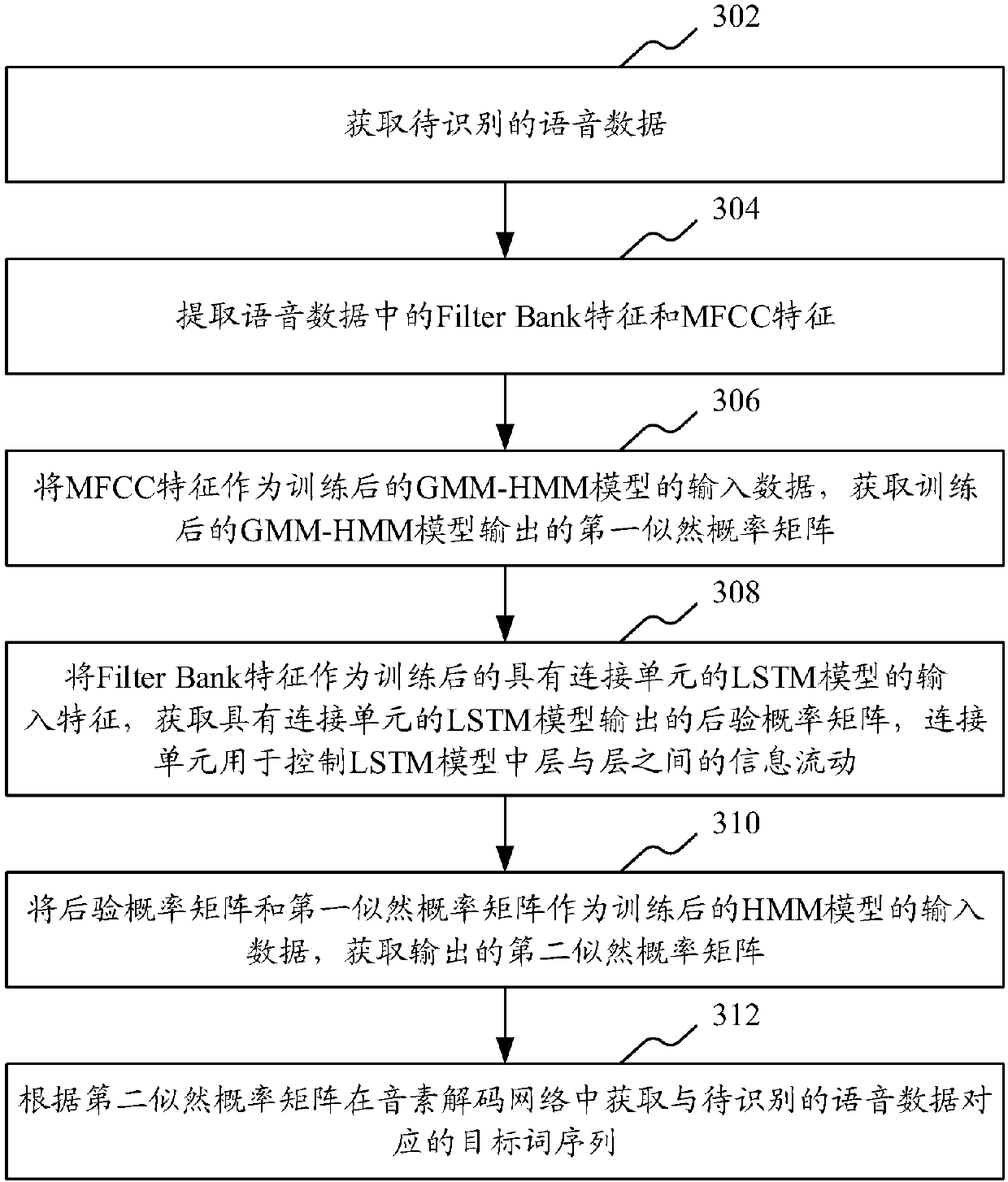
Examples
Embodiment Construction
[0046] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
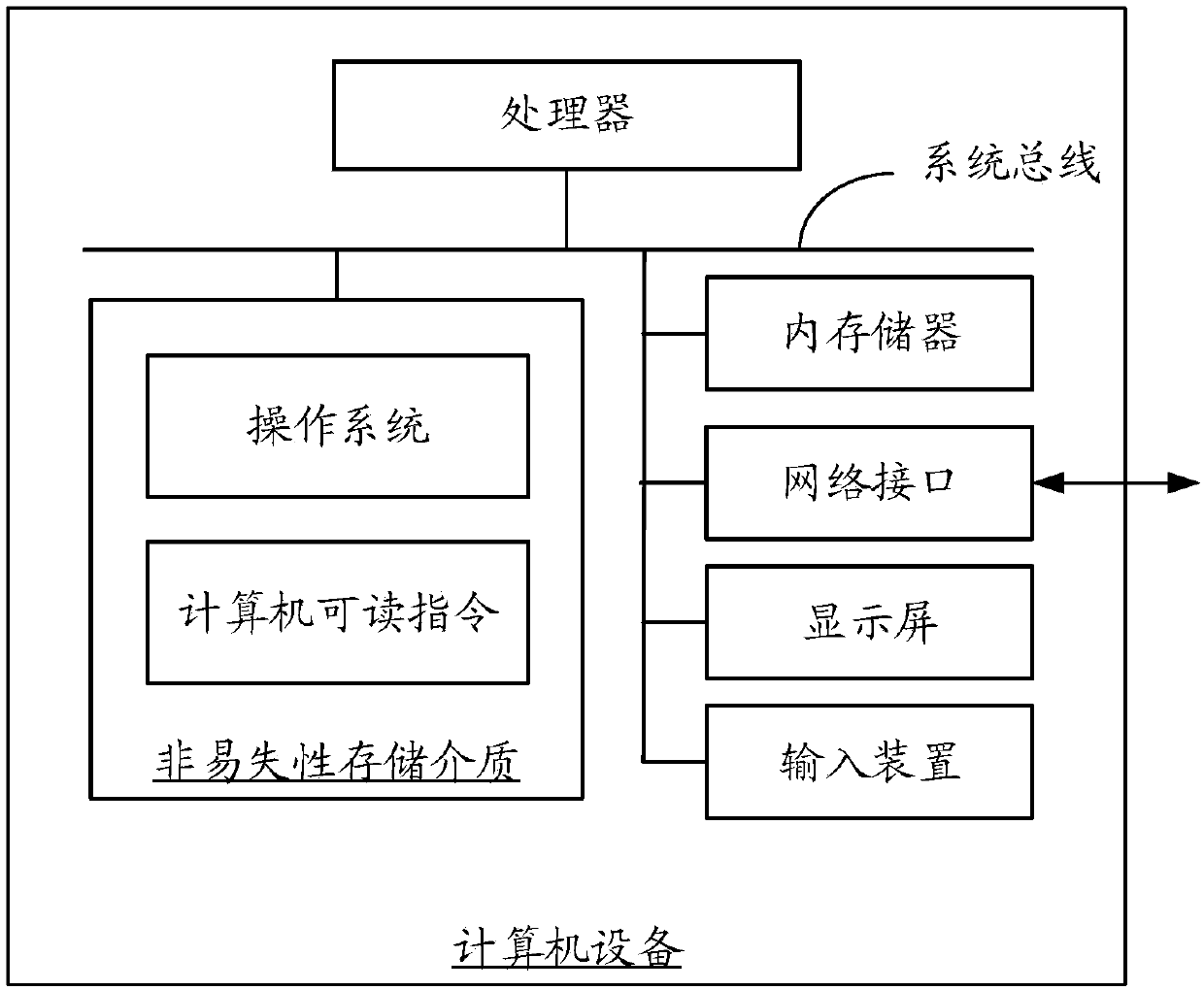
[0047] like figure 1 Shown is a schematic diagram of the internal structure of a computer device in an embodiment. The computer device may be a terminal or a server. refer to figure 1 , the computer equipment includes a processor connected through a system bus, a non-volatile storage medium, an internal memory, a network interface, a display screen and an input device. Wherein, the non-volatile storage medium of the computer device may store an operating system and computer-readable instructions, and when the computer-readable instructions are executed, the processor may execute a voice recognit...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More