Privacy protection method and system of data release
A privacy protection system and data release technology, applied in the privacy protection field of data release, can solve problems such as the inability to prevent background knowledge attacks and homogeneity attacks, the leakage of identity information and sensitive attributes, and the inability to prevent privacy leakage. Small size, improved usability, good practicability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
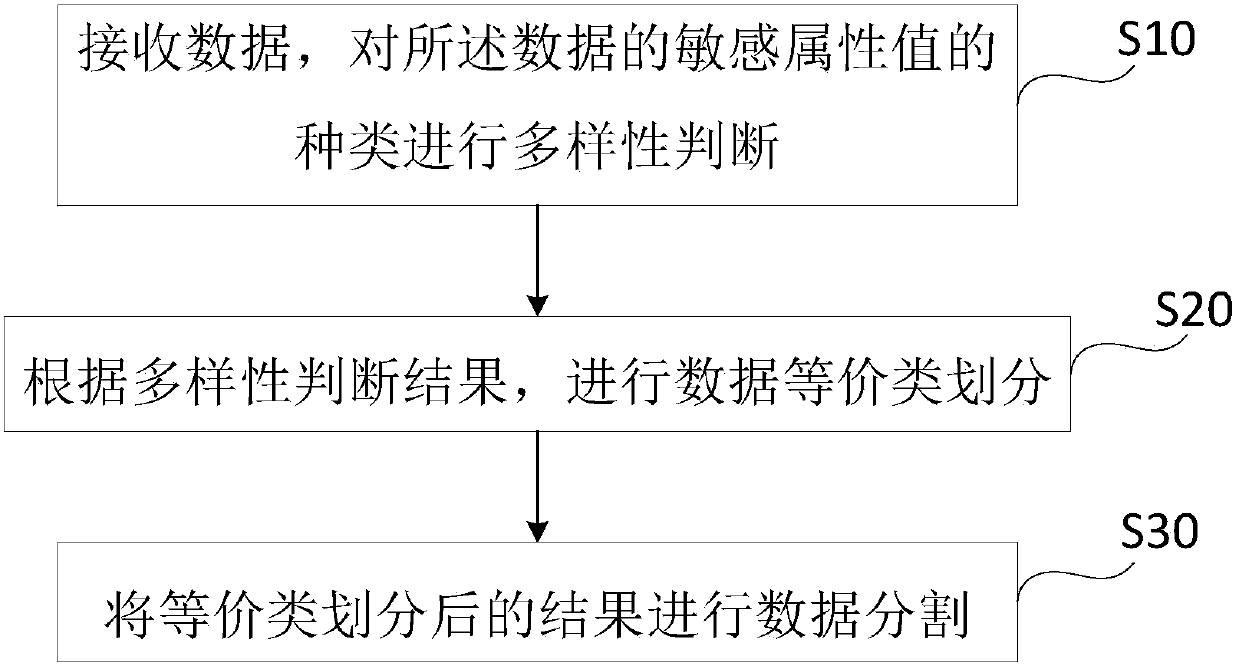
[0070] Such as figure 1 As shown, this embodiment provides a privacy protection method for data publishing, the method includes the following steps:
[0071] S10: Receive data, and perform diversity judgment on the types of sensitive attribute values of the data;
[0072] In this step, receive data with privacy protection requirements, generally a data table, first understand the individual identification attributes, quasi-identification attributes, and sensitive attributes of the data table, and determine the sensitive data in the original data, that is, view the sensitive attribute values of the data , counting the types of different sensitive attribute values in the sensitive attribute column of the data table, for example, the type of sensitive attribute value is S c , based on S c The size of the data table is divided into different divisions. Generally, by setting a diversity parameter l, it is judged that S c The relationship with l, the records that satisfy l-...
Embodiment 2
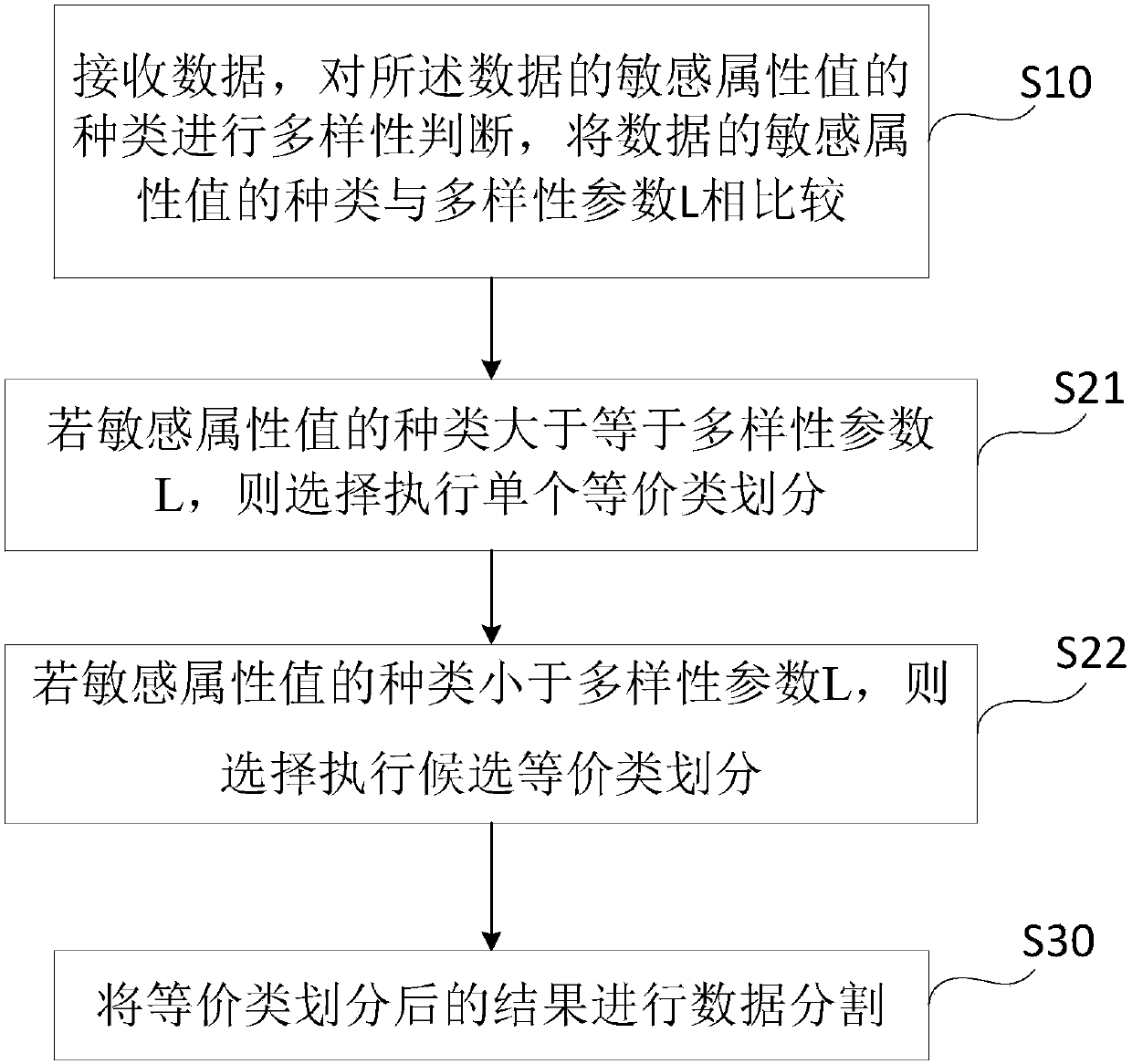
[0079] Such as figure 2 As shown, the difference between this embodiment and the previous embodiments is that this embodiment provides a privacy protection method for publishing data with a specific clustering algorithm, and the types of sensitive attribute values of the data described in step S10 are diversified The judgment is specifically as follows: the type of the sensitive attribute value of the data is compared with the diversity parameter L, and the value of L is a preset value. In general, if there are 7 types of sensitive attribute values, the value of L is set as The value 3 after dividing 7 by 2 and rounding up, that is, L=3;
[0080] The step S20 includes the following steps:
[0081] S21: If the type of the sensitive attribute value is greater than or equal to the diversity parameter L, choose to perform a single equivalence class division; in the process of dividing a single equivalence class in this step, loop to determine whether the length of the equivale...
Embodiment 3
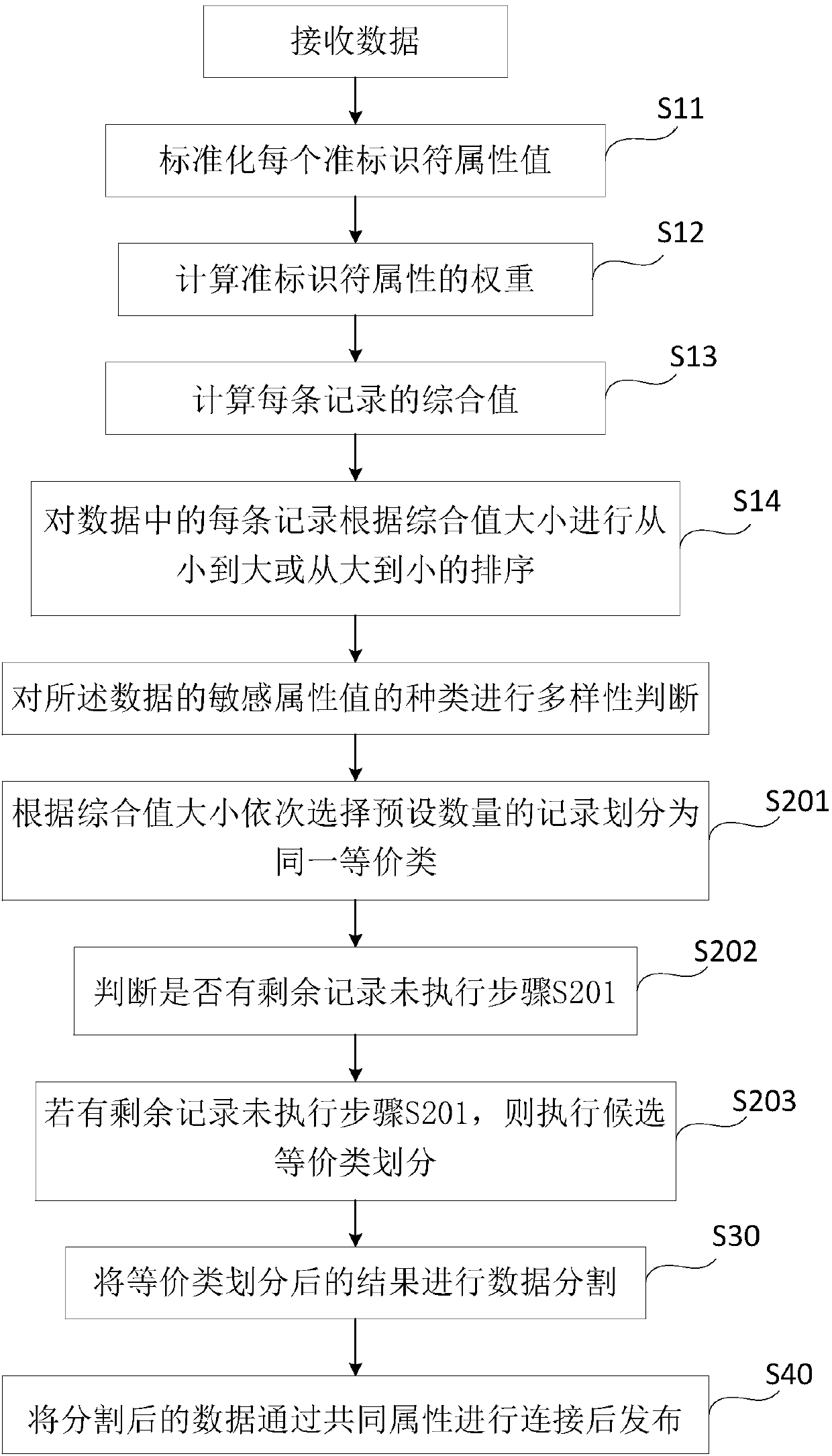
[0084] Such as image 3 As shown, the difference between this embodiment and Embodiment 1 is that in the step S10, data preprocessing is performed after data is received before diversity judgment is performed. Data preprocessing is to consider that different attributes have different weights during the data publishing process, Using weights to cluster data is simple to implement and can better reflect the similarity of data. It specifically includes the following steps:
[0085] S11: standardize each quasi-identifier attribute value, and map the quasi-identifier attribute value to the [0,1] range; logarithmic attribute values are mapped to the [0,1] range using the range standardization calculation formula, New quasi-identifier attribute value=(original quasi-identifier attribute value-minimum value) / (maximum value-minimum value);
[0086] Specifically, suppose the original data table T=1 ,QI 2 ,...,QI n , SA>, has n quasi-identifier attributes, n records, that is, n clus...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com