

Method and device for retrieving data
A data retrieval and data request technology, applied in the field of big data processing, can solve the problems of long result return response time, retrieval, and the inability of SparkSQL's native architecture to have a large result set, so as to reduce the result return response time and the total retrieval time , solve memory problems, improve efficiency and availability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
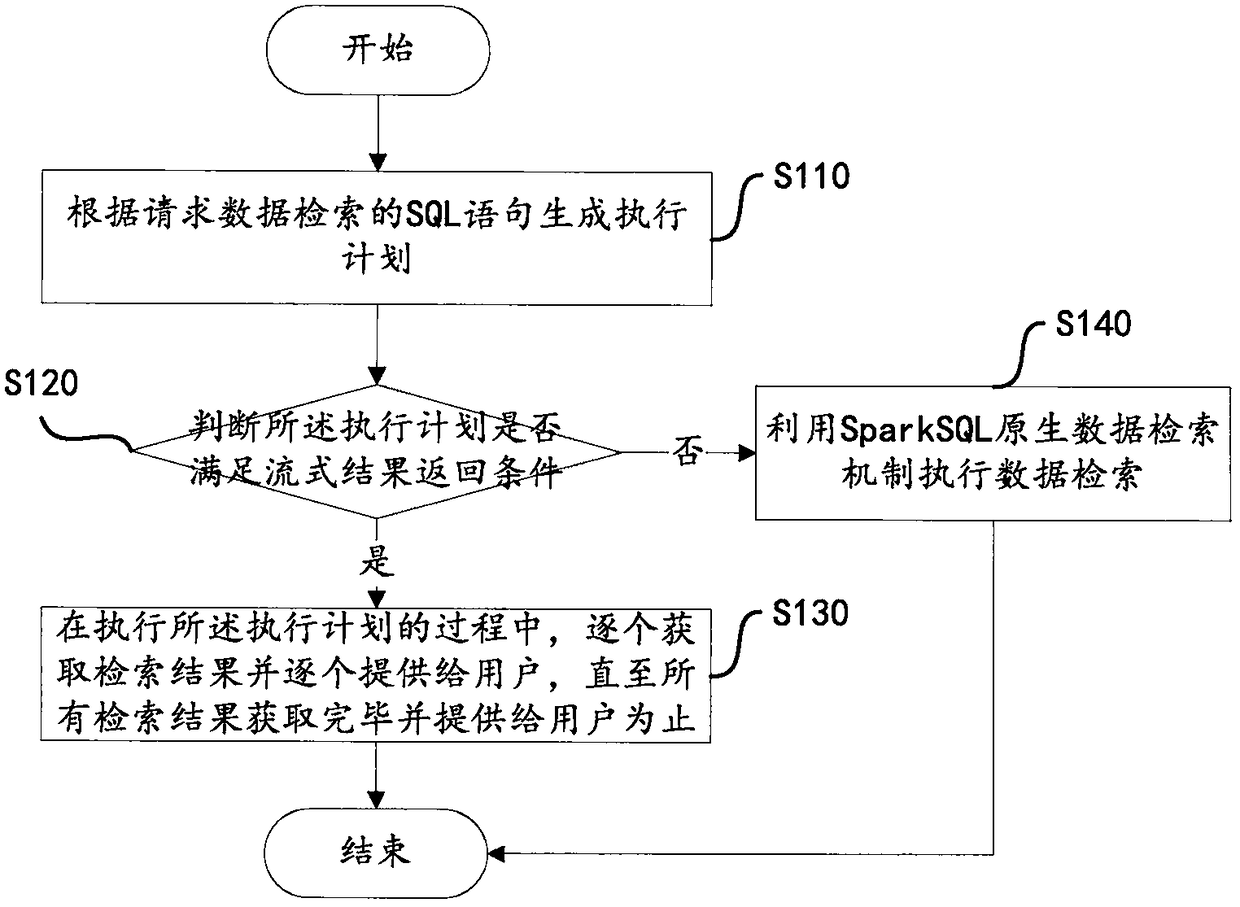
[0027] This embodiment provides a data retrieval method. Such as figure 1 Shown is a flowchart of a data retrieval method according to an embodiment of the present invention.
[0028] Step S110, generating an execution plan according to the SQL statement requesting data retrieval.
[0029] Step S120, judging whether the execution plan satisfies the streaming result return condition; if yes, execute step S130; if not, execute step S140.
[0030] The streaming result return condition includes: the statement type of the execution plan is a preset type, and / or, the number of files to be scanned for data retrieval is greater than a preset threshold. Among them, the statement type is that there is no order requirement for the retrieval results.
[0031] Step S130, in the process of executing the execution plan, obtain the retrieval results one by one and provide them to the user one by one, until all the retrieval results are obtained and provided to the user.
[0032] In this e...
Embodiment 2
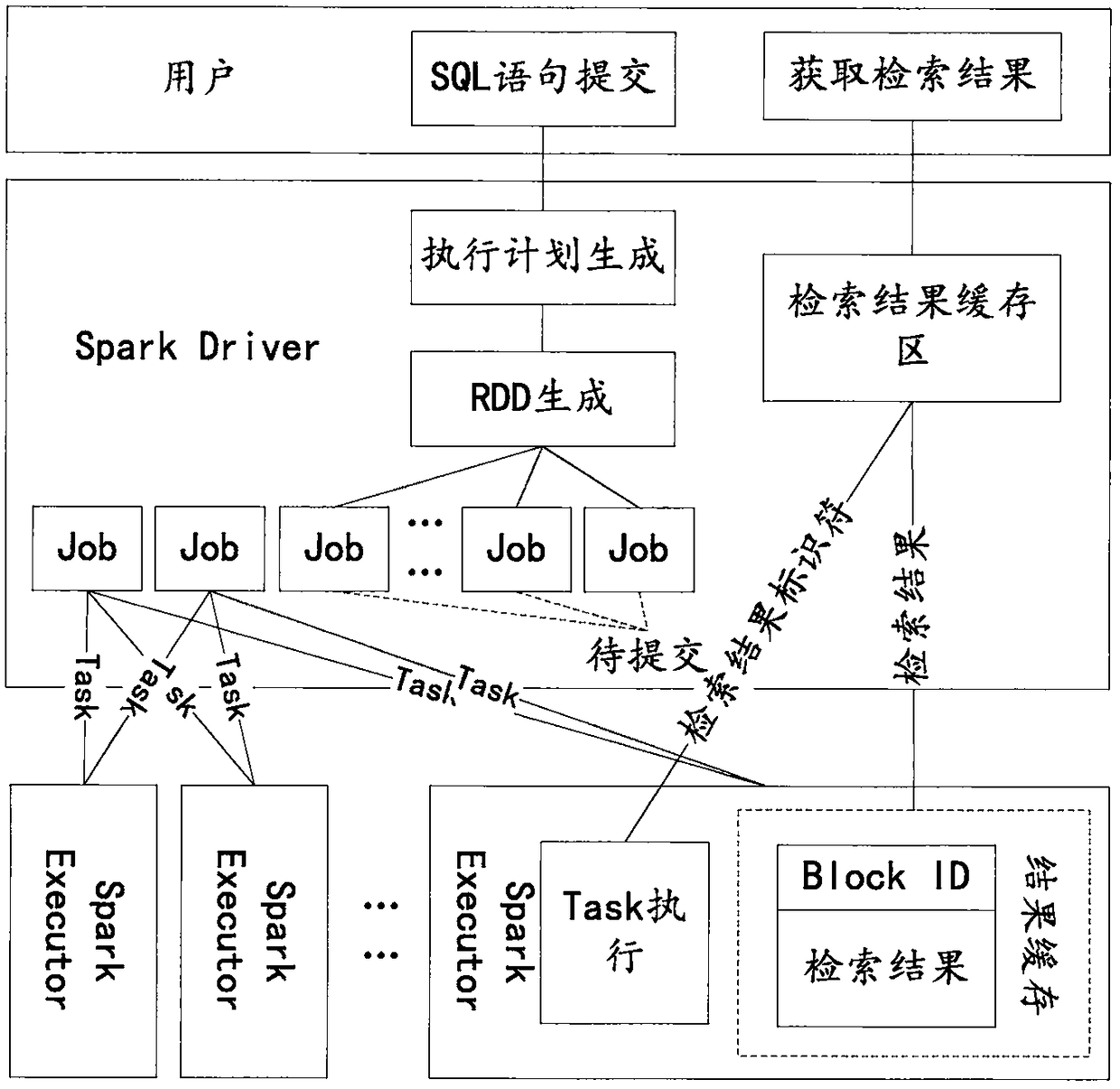
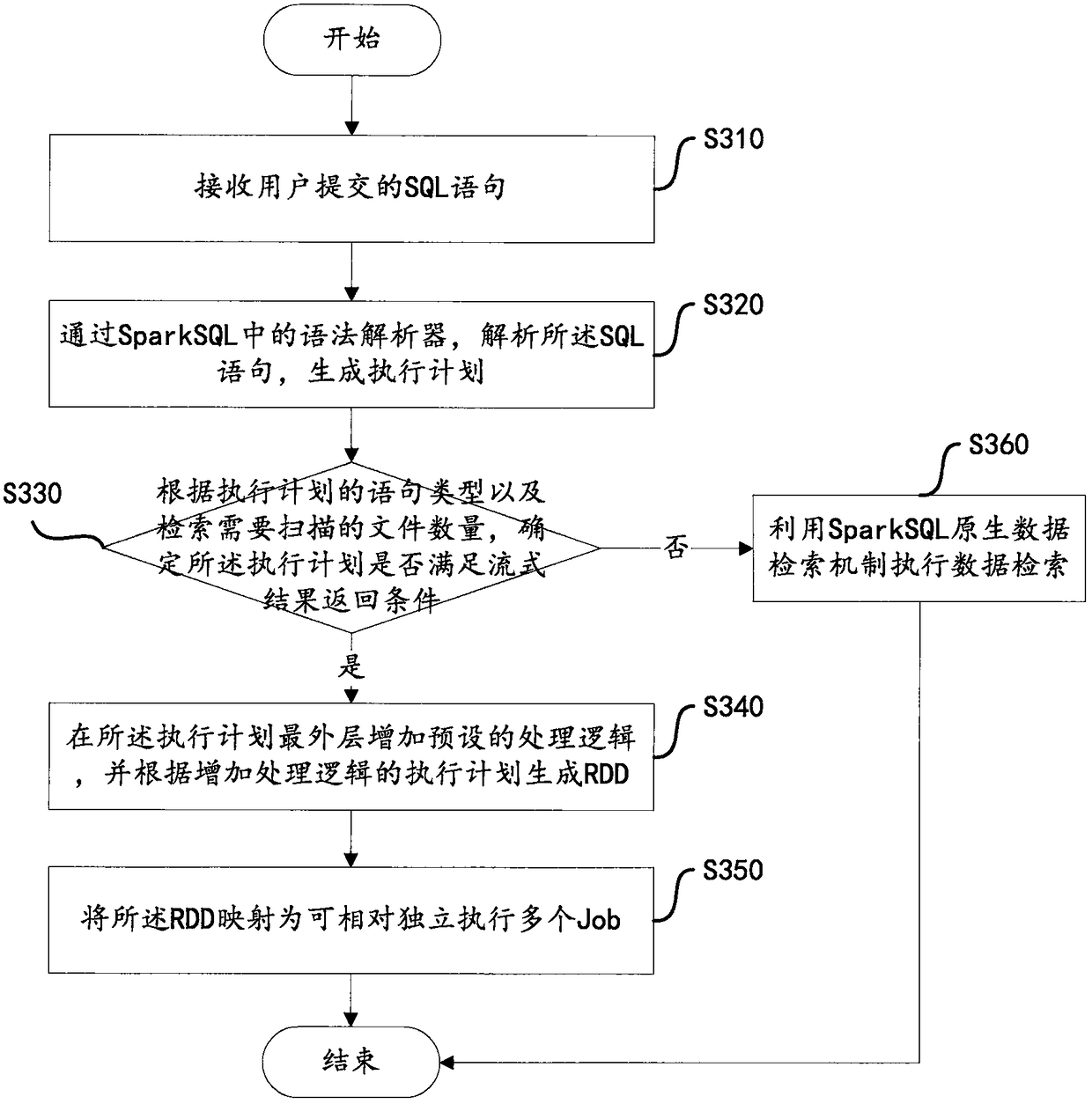
[0048] This embodiment describes the steps of generating a Job. This embodiment is executed on the Spark driver. image 3 It is a flow chart of steps for generating a Job according to an embodiment of the present invention.
[0049] Step S310, receiving the SQL statement submitted by the user.
[0050] This SQL statement is used to request data retrieval.
[0051] Include execution logic and metadata information of files to be retrieved in the SQL statement.
[0052] Wherein, according to the metadata information of the files to be retrieved, the number of files to be scanned for this retrieval can be determined.
[0053] In step S320, the SQL statement is parsed by a parser in SparkSQL to generate an execution plan.
[0054] Parsing the SQL statement into a logical execution tree; generating an execution plan according to the file metadata information of the library table in the SQL statement and the logical execution tree.
[0055] Step S330, according to the statement ...
Embodiment 3
[0066] This embodiment describes the steps of concurrently submitting Jobs. Figure 4 It is a flowchart of the steps of concurrently submitting Jobs according to an embodiment of the present invention.
[0067] In step S410, the Spark Driver starts a preset thread pool.
[0068] In this embodiment, multiple threads are maintained in the preset thread pool, and multiple threads concurrently submit multiple jobs to the Spark scheduling layer in a blocking manner to ensure that an appropriate amount of jobs run at the same time.
[0069] In this embodiment, the smaller execution granularity can effectively reduce the response time of retrieval results, effectively reduce the number of jobs queued for execution at the Spark scheduling layer, reduce the pressure of job distribution, and save The machine resource of the Spark Driver node where it is located.
[0070] In step S420, the Spark Driver judges whether there is an unsubmitted job; if yes, execute step S430; if not, finis...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More