A machine learning-based similarity computation method for multi-feature text data
A similarity calculation and text data technology, which is applied in unstructured text data retrieval, text database clustering/classification, special data processing applications, etc. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0054]All features disclosed in this specification, or steps in all methods or processes disclosed, may be combined in any manner, except for mutually exclusive features and / or steps.
[0055] Any feature disclosed in this specification (including any appended claims, abstract and drawings), unless expressly stated otherwise, may be replaced by alternative features which are equivalent or serve a similar purpose. That is, unless expressly stated otherwise, each feature is one example only of a series of equivalent or similar features.
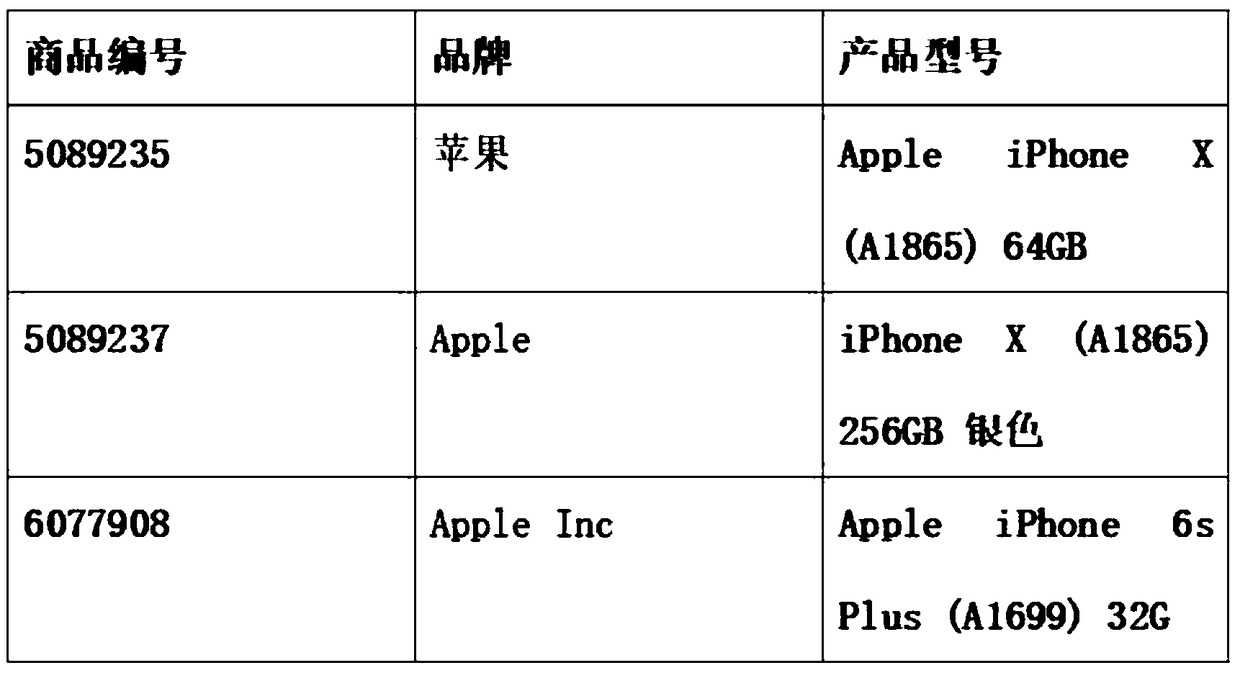
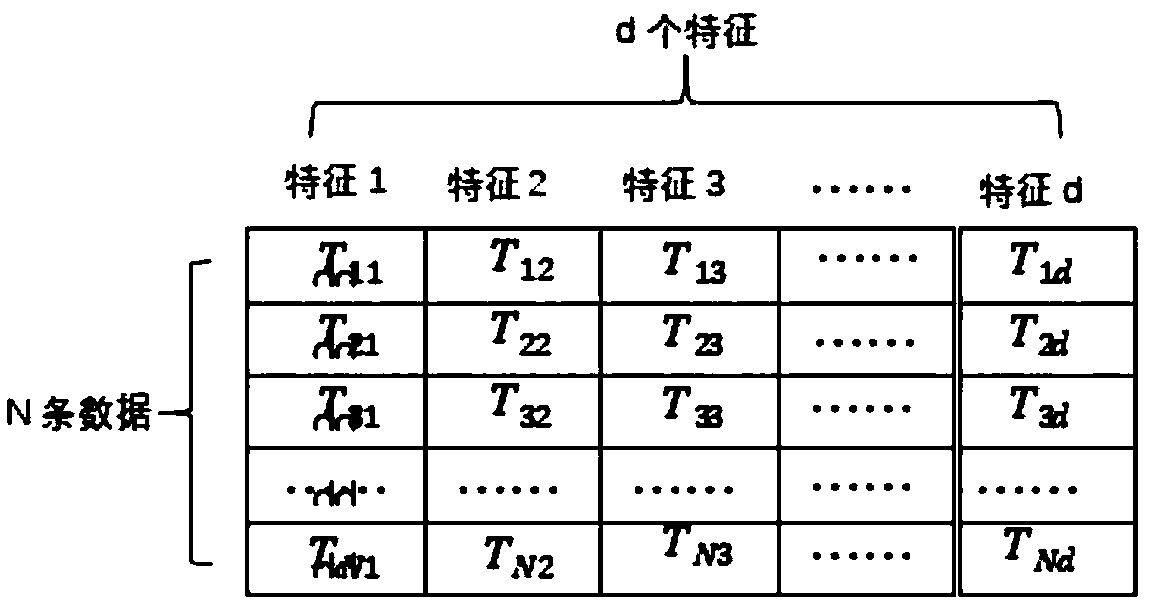
[0056] Such as figure 2 As shown, each piece of data in the data group has d features, and each feature is a text type or data that can be converted into a text type. Meanwhile, the total number of pieces of data is N. Now our goal is to obtain other data with the highest similarity to any piece of data in the data group.
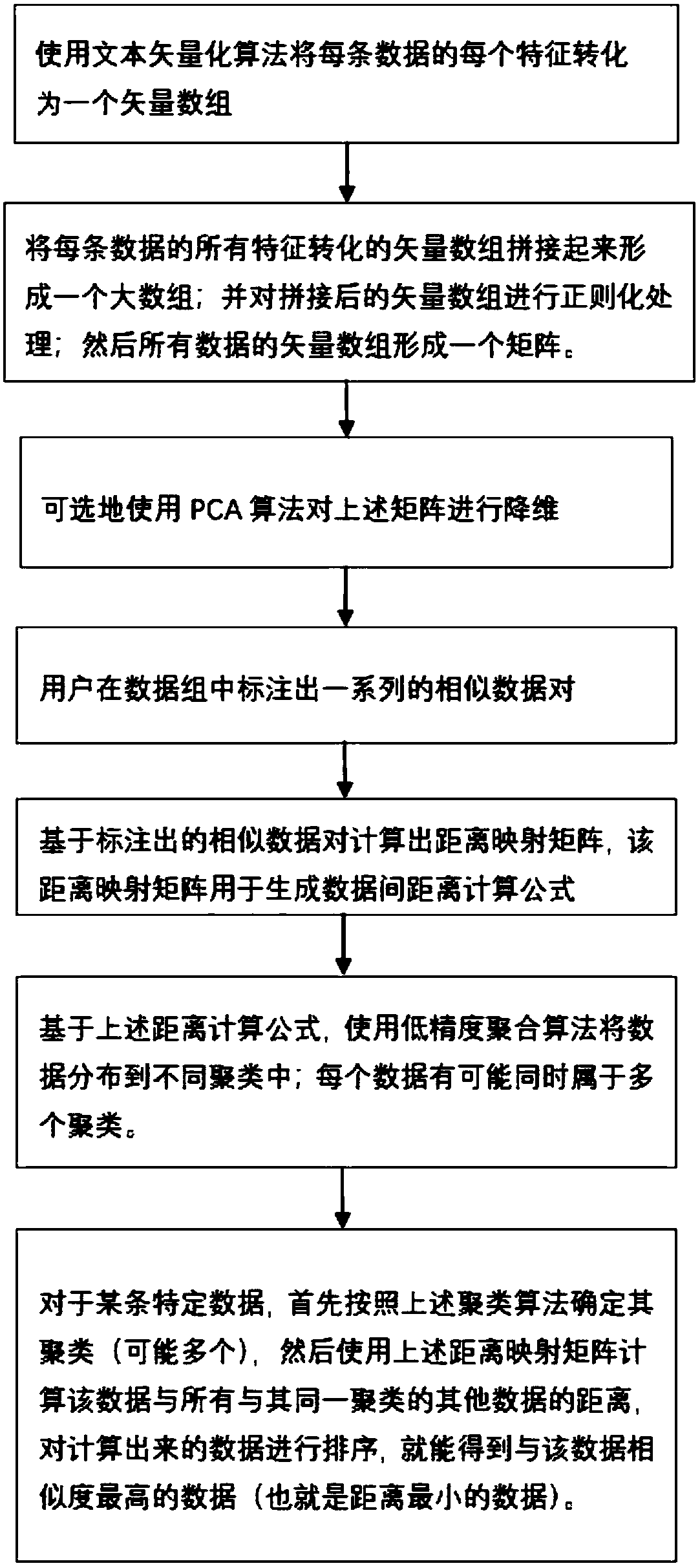
[0057] To solve this problem, we propose a similarity calculation method for multi-feature text data. The procedure o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com