

Dynamic cache processing method and device, storage medium and electronic equipment
A technology of dynamic caching and processing methods, applied in the field of data processing, can solve problems such as data processing efficiency decline, achieve the effects of improving user experience, saving cache resources, and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
example 1
[0066] Example 1: The writing time of data A is 9:21:05, and the current time is 12:21:05. The difference Δt between the writing time of data A and the current time is 3 hours. will parameter a 1 Configured as 10, the parameter b 1Configured as 1, the first score s is calculated by formula 2 1 is 2.5.
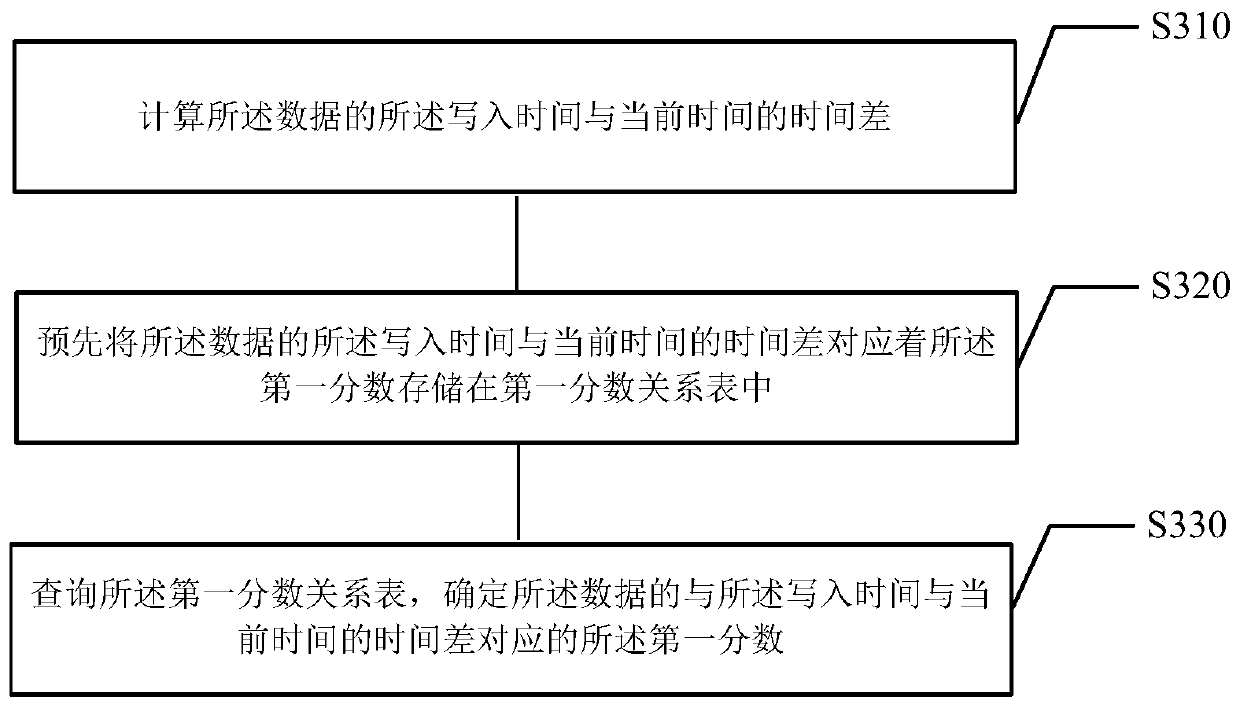
[0067] In another exemplary implementation, in step S120, determining the first fraction of the data based on the writing time of the data may include steps S310-S330. see image 3 said, where:
[0068] In step S310, calculate the time difference between the writing time of the data and the current time;
[0069] In step S320, the time difference between the writing time of the data and the current time is stored in the first score relationship table in advance corresponding to the first score;
[0070] In step S330, the first score relationship table is queried to determine the first score corresponding to the time difference between the writing time and the current tim...
example 2
[0074] Example 2: The current time is May 15, 2019 13:30:21. Data B was written to the cache at 13:21:21 on May 15, 2019. Then the time difference between the writing time of data B and the current time is 9 minutes, and the first score of data B is 40 by querying the first score relationship table (see below). Data C was written to the cache at 13:30:21 on February 15, 2019. Then the time difference between the writing time of data C and the current time is 3 months. By querying the first score relationship table (see below), the first score of data C can be obtained as 0.5.
[0075] The first score relationship table is as follows:
[0076]
[0077] In step S122, a second score of the data is determined based on the writer information of the data. After investigating the experience of using data by a large number of users, it shows that the data written by some users is used more frequently, and the data written by this user is of high importance. Conversely, the data...
example 3
[0086] Example 3: In the company, the relevant data released by the director will be accessed by most managers and employees of all departments, and the number of visits is high, and its importance is high. The relevant data released by the manager will be accessed by the personnel in the department, and the number of visits is relatively high, and its importance is relatively high. The relevant data recorded by employees will be accessed by themselves or their managers, and rarely accessed by other employees. The number of accesses is small and its importance is low. Therefore, the director can be identified as the third level, the manager can be identified as the second level, and the employee can be identified as the first level. Assume that the value of the parameter R is configured as 3, a 2 Configured to 0.5. Calculated by formula 3: the second score s of the relevant data written by the director 2 At 13.5, the second fraction of relevant data written by the manager s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More