

Multi-channel speaker-independent voice separation method based on deep clustering
A speaker-independent, speech separation technology, applied in speech analysis, instruments, character and pattern recognition, etc., can solve the problems of poor robustness, achieve the effect of improving robustness, reducing nonlinear distortion, and solving speech separation problems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

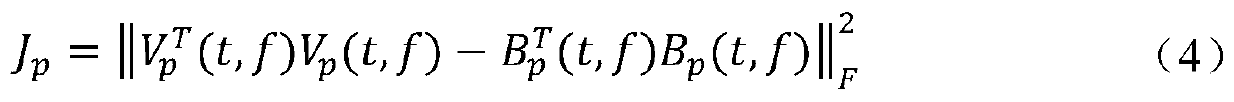

Examples
Embodiment Construction
[0034] The present invention will be further described below in conjunction with the accompanying drawings and embodiments, and the present invention includes but not limited to the following embodiments.
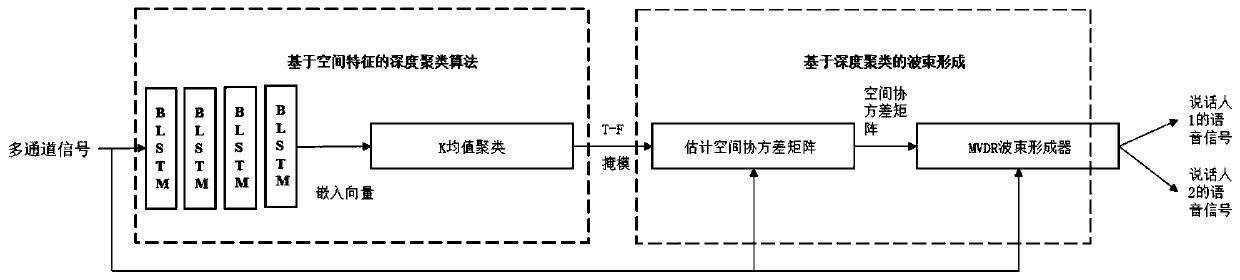
[0035] like figure 1 As shown, the present invention provides a multi-channel and speaker-independent speech separation method based on deep clustering. First, collect the speaker's voice signal received by multiple microphones, and extract the amplitude spectrum features and spatial features of the voice to be processed; then, send the features of each channel to the bidirectional long short-term memory (BLSTM) network, and output the network Carry out K-means clustering to obtain the ideal binary time-frequency (Time-Frequency, T-F) mask after processing; then, use the obtained mask to calculate the spatial covariance matrix of the speaker's voice and the interference it receives, And calculate the coefficients of the MVDR beamformer; finally, the separated speaker voice...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More